

Introduction
Dynamic management views are immensely useful tools that are provided with all editions of SQL Server. Using them, you can quickly find out information about many aspects of SQL Server, everything from index usage, query cache contents, server process data, wait stats, and much, much more!
The addition of In-Memory OLTP brings with it a host of new DMVs that track many parts of this new feature, but there are a few other new views and changes that are worth writing home about. Attached is a spreadsheet that lists all changes I could identify between SQL Server 2012 and 2014. If you are upgrading, these changes could be invaluable towards monitoring new features, or taking into account changes such that your existing monitoring doesn’t break after upgrading.
The Details
As a reference, a full list of DMVs can be returned by running the following query:
SELECT
*
FROM sys.system_objects
WHERE name LIKE 'dm_%'
AND type = 'V'
ORDER BY nameThis information can be used to verify the existence and contents of any DMV in any version. Also note that Microsoft occasionally implements changes in service packs. A handful of new DMVs were quietly added in SQL Server 2008R2 SP1, and so it’s worth keeping in mind that changes don’t only occur when a major version comes out.
What follows is a list of what I consider to be the most significant or interesting changes in SQL Server 2014. We’ll cover DMVs related to In-Memory OLTP last as they constitute the huge majority of recent DMV additions.
sys.dm_db_log_space_usage
It’s a minor change, but the log_space_in_bytes_since_last_backup column was added to the view. This could be handy for keeping track of log usage prior to, or in between backup cycles:

Note the size is in bytes, so some additional conversion will be required if you’d like that number in a more digestible units, such as KB or MB.
sys.dm_hadr_database_replica_states
Another single column addition, this one inserted into the 6th position. If you use AlwaysOn, then you now can verify if a replica is the primary replica using the column is_primary_replica.
sys.dm_io_cluster_valid_path_names
This is a brand new view in SQL Server 2014 that returns data on all valid shared disks for servers using failover clustering. If an instance is not clustered, then no rows are returned. This view provides the path_name, which is the root directory path for database and log files, cluster_owner_node, the current owner of the drive, which is the node that hosts the metadata server, and is_cluster_shared_volume, which tells you if this is a cluster shared volume or not.
sys.dm_os_buffer_pool_extension_configuration
This new view provides configuration information about the new buffer pool extension functionality in SQL Server 2014. It will return one row per buffer pool extension file. If this feature is disabled, a single row will be returned with default metadata that will look like this:

The buffer pool extension allows you to expand your buffer pool onto SSDs so that you can cheaply increase performance, especially in read-heavy OLTP environments. It can be configured and used without any application or databases changes, allowing it to be implemented quickly. Lastly, since it only operates on clean pages, there is no chance of data loss. We can look forward to an in-depth article in the future that will dive into this feature and thoroughly analyze its effects on SQL Server.
sys.dm_resource_governor_resource_pool_volumes
sys.dm_resource_governor_resource_pools
sys.dm_resource_governor_configuration
For users of the Resource Governor, a new view, as well as some changes to existing views have been made in order to account for the ability in SQL Server 2014 to govern IO. There is no GUI available for modifying IO settings within the Resource Governor. In order to change the max or min IOPS per volume, TSQL will need to be used to create a new resource pool or alter an existing one. Here’s an example of a basic test resource pool being created:
CREATE RESOURCE POOL [test_resource_pool]
WITH(MIN_CPU_PERCENT=0,
MAX_CPU_PERCENT=33,
MIN_MEMORY_PERCENT=0,
MAX_MEMORY_PERCENT=33,
CAP_CPU_PERCENT=100,
AFFINITY SCHEDULER = AUTO,
MIN_IOPS_PER_VOLUME=0,
MAX_IOPS_PER_VOLUME=1000)To dm_resource_governor_configuration, a single new column was added, max_outstanding_io_per_volume, which is self-explanatory. To dm_resource_governor_resource_pools, 18 new columns were added, increasing visibility into usage within this feature. These new IO-related columns are primarily cumulative data, as well as min and max usage values. For example, the new column read_io_completed_total provides the total read IOs since the Resource Governor statistics were last reset. Here is a subset of some of the new columns that have been added to this view:

The new Resource Governor view, dm_resouce_governor_resource_pool_volumes, appears to contain overlap of most of its columns with dm_resouce_governor_resource_pools, but the breakdown is slight different: the former divides this data by disk volumes in use by the instance and the latter strictly by resource pools (which can be identical depending on configuration). The new data is strictly related to IO on each volume and will only be populated when at least one user connection is made via the Resource Governor. Until that point, it will remain empty.
In-Memory OLTP
By far, the biggest feature addition in SQL Server 2014 is the addition of memory-optimized tables and native compiled stored procedures. Along with this feature are a total of 11 database-specific DMVs and 6 instance-level DMVs. In order to adequately illustrate their usage, we will walk through the creation of some in-memory objects and show how the results are reflected in our DMVs.
Our example here will be a setup of 3 tables that describe ingredients, meals, and a one-to-many relationship that illustrates what a meal will contain. I’ll include the steps to create a new database and configure it for memory-optimized tables:
CREATE DATABASE restaurant
GO
-- Create a filegroup for memory-optimized data and add a file
ALTER DATABASE restaurant ADD FILEGROUP restaurant_mod CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE restaurant ADD FILE (name='restaurant_mod1', filename='c:\Data\restaurant_mod1') TO FILEGROUP restaurant_mod
USE restaurant
GO
-- This is a table of ingredients that will be referenced by other tables
CREATE TABLE dbo.ingredients (
ingredient_id INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=50000),
ingredient_name VARCHAR(50) NOT NULL,
cost DECIMAL(10,2) NOT NULL,
color VARCHAR(25) NULL
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
-- Create a table that will contain meals
CREATE TABLE dbo.meals (
meal_id INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 20000),
meal_name VARCHAR(50) NOT NULL,
cuisine VARCHAR(25) NOT NULL,
meal_description VARCHAR(100) NOT NULL,
recipe_description VARCHAR(2000) NOT NULL,
spice_level TINYINT NULL
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
-- This table relates meals to ingredients as recipes
CREATE TABLE dbo.recipe (
recipe_id INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 100000),
meal_id INT NOT NULL,
ingredient_id INT NOT NULL,
INDEX ix_recipe_meal_id NONCLUSTERED HASH(meal_id) WITH (BUCKET_COUNT = 100000),
INDEX ix_recipe_ingredient_id NONCLUSTERED HASH(ingredient_id) WITH (BUCKET_COUNT = 100000)
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
-- Insert some data for our restaurant:
INSERT INTO dbo.meals VALUES (1, 'Chicken Taco', 'Mexican', 'A spicy taco with chicken', 'Cook chicken, combine with beans and other ingredients in a taco shell.', 6)
INSERT INTO dbo.meals VALUES (2, 'Meatloaf', 'American', 'A hearty loaf of beef and spices', 'Combine all ingredients and bake at 350 for 90 minutes.', 2)
INSERT INTO dbo.meals VALUES (3, 'Lemonade', 'American', 'Refreshing lemonade for a cold day', 'Combine all ingredients and chill for an hour before serving.', 0)
INSERT INTO dbo.ingredients VALUES (1, 'Chicken', '3.99', 'White')
INSERT INTO dbo.ingredients VALUES (2, 'Taco Shells', '2.00', 'Yellow')
INSERT INTO dbo.ingredients VALUES (3, 'Lettuce', '1.50', 'Green')
INSERT INTO dbo.ingredients VALUES (4, 'Tomato', '1.25', 'Red')
INSERT INTO dbo.ingredients VALUES (5, 'Cilantro', '2.00', 'Green')
INSERT INTO dbo.ingredients VALUES (6, 'Black Beans', '0.50', 'Black')
INSERT INTO dbo.ingredients VALUES (7, 'Beef', '3.00', 'Brown')
INSERT INTO dbo.ingredients VALUES (8, 'Bread Crumbs', '1.50', 'Yellow')
INSERT INTO dbo.ingredients VALUES (9, 'Parsley', '1.75', 'Green')
INSERT INTO dbo.ingredients VALUES (10, 'Tomato Sauce', '0.60', 'Red')
INSERT INTO dbo.ingredients VALUES (11, 'Lemons', '0.75', 'Yellow')
INSERT INTO dbo.ingredients VALUES (12, 'Sugar', '2.50', 'White')
INSERT INTO dbo.ingredients VALUES (13, 'Water', '0.10', 'Clear')
INSERT INTO dbo.recipe VALUES (1, 1)
INSERT INTO dbo.recipe VALUES (1, 2)
INSERT INTO dbo.recipe VALUES (1, 3)
INSERT INTO dbo.recipe VALUES (1, 4)
INSERT INTO dbo.recipe VALUES (1, 5)
INSERT INTO dbo.recipe VALUES (1, 6)
INSERT INTO dbo.recipe VALUES (2, 7)
INSERT INTO dbo.recipe VALUES (2, 8)
INSERT INTO dbo.recipe VALUES (2, 9)
INSERT INTO dbo.recipe VALUES (2, 10)
INSERT INTO dbo.recipe VALUES (3, 11)
INSERT INTO dbo.recipe VALUES (3, 12)
INSERT INTO dbo.recipe VALUES (3, 13)
GO
-- Update statistics before continuing
UPDATE STATISTICS dbo.meals WITH FULLSCAN, NORECOMPUTE
UPDATE STATISTICS dbo.ingredients WITH FULLSCAN, NORECOMPUTE
UPDATE STATISTICS dbo.recipe WITH FULLSCAN, NORECOMPUTE
GO
-- Create a natively compiled stored procedure for returning all ingredients for a particular meal.
CREATE PROCEDURE dbo.ingredient_list @meal_id int
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
SELECT
ingredients.ingredient_name
FROM dbo.meals
INNER JOIN dbo.recipe
ON meals.meal_id = recipe.meal_id
INNER JOIN dbo.ingredients
ON ingredients.ingredient_id = recipe.ingredient_id
WHERE meals.meal_id = @meal_id
END
GO
-- Run our natively compiled stored proc for an arbitrary meal
EXEC dbo.ingredient_list 1
GONow that we have some in-memory schema to play with, we can take a look at some of our new DMVs and how they work.
sys.dm_db_xtp_object_stats
Basic object usage data is provided by this DMV. A positive object_id indicates user objects, whereas a negative object_id indicates system objects. System tables are used to store run-time information for the in-memory engine. Since they are solely in memory, they are not referenced in system catalogs as other objects are. We can join this to sys.all_objects in order to get more info on our schema.
SELECT
dm_db_xtp_object_stats.*,
all_objects.name
FROM sys.dm_db_xtp_object_stats
INNER JOIN sys.all_objects
ON all_objects.object_id = dm_db_xtp_object_stats.object_id
WHERE all_objects.object_id > 0 -- Explicitly filter out system objects 
This query returns all user objects, so we can see our 3 memory-optimized tables and some stats on them. Note that this data is maintained as of SQL Servers last restart.
sys.dm_db_xtp_index_stats
This index provides additional index statistics for all indexes on memory-optimized tables. Similar to the previous view, we can get this data along with the index name using a join to sys.indexes:
SELECT
name,
type_desc,
dm_db_xtp_index_stats.*
FROM sys.dm_db_xtp_index_stats
INNER JOIN sys.indexes
ON indexes.index_id = dm_db_xtp_index_stats.index_id
AND indexes.object_id = dm_db_xtp_index_stats.object_idThis query returns our 2 nonclustered indexes along with the default primary key indexes on each table we created:

Note that this data is maintained as of SQL Servers last restart.
sys.dm_db_xtp_table_memory_stats
This view provides memory usage statistics for all in-memory tables, including system tables (which will have a negative object_id if displayed). A join to sys.all_objects provides additional information as-needed:
SELECT
all_objects.name,
dm_db_xtp_table_memory_stats.*
FROM sys.dm_db_xtp_table_memory_stats
LEFT JOIN sys.all_objects
ON all_objects.object_id = dm_db_xtp_table_memory_stats.object_idThe output of this query will look like this:
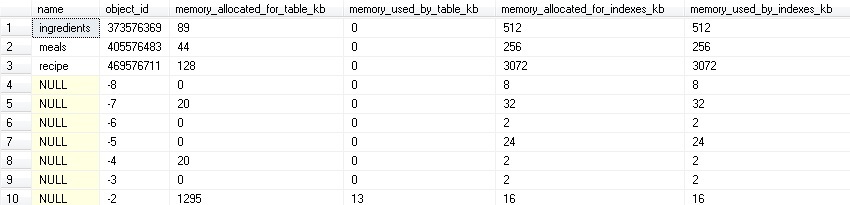
A sum of any of the columns in this DMV (aside from object_id, of course) will give you the total memory usage/allocation for all in-memory objects. System objects were kept here so that we don’t inadvertently filter them out, in the event that we do want to aggregate or report on this data.
sys.dm_db_xtp_memory_consumers
This view returns all memory consumers for the in-memory OLTP engine. This data includes indexes, tables, and a number of system objects. The following query will return the data from this view, along with the name of the table or index it relates to, if applicable:
SELECT
all_objects.name AS name,
indexes.name AS index_name,
dm_db_xtp_memory_consumers.*
FROM sys.dm_db_xtp_memory_consumers
LEFT JOIN sys.all_objects
ON all_objects.object_id = dm_db_xtp_memory_consumers.object_id
LEFT JOIN sys.indexes
ON indexes.index_id = dm_db_xtp_memory_consumers.index_id
AND indexes.object_id = dm_db_xtp_memory_consumers.object_idNote that any rows with a NULL object_id and a memory_consumer_type_desc of VARHEAP are memory that is set aside for use by variable length columns. There will also be a single row per database for PGPOOL, which tracks memory consumption for the database page pool (used for table variables, some serialized scans, and other runtime operations).
sys.dm_db_xtp_hash_index_stats
This is an important view for verifying the performance of any hash indexes you have created on an in-memory table. The following query will return info on your hash indexes, the parent object, and statistics on bucket usage:
SELECT
object_name(dm_db_xtp_hash_index_stats.object_id) AS 'object name',
indexes.name,
floor((cast(empty_bucket_count as float)/total_bucket_count) * 100) AS 'empty_bucket_percent',
dm_db_xtp_hash_index_stats.total_bucket_count,
dm_db_xtp_hash_index_stats.empty_bucket_count,
dm_db_xtp_hash_index_stats.avg_chain_length,
dm_db_xtp_hash_index_stats.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats
INNER JOIN sys.indexes
ON indexes.index_id = dm_db_xtp_hash_index_stats.index_id
AND indexes.object_id = dm_db_xtp_hash_index_stats.object_idA hash index is structured differently from a standard nonclustered index in that you create a set number of buckets which will be populated automatically via SQL Server’s hash function. Hash indexes will only work on equality predicates (=) and do not support sorting on the index (as the data is not stored in order). Hash indexes work best for key columns that are unique, as the more duplicate values exist, the more SQL Server needs to work in order to sort through a bucket of duplicate keys (all duplicate key values will always be stored in the same bucket).
In monitoring the performance of a hash index, we primarily are interested in the empty bucket count and the average chain length. Running the query above, we can look analyze this information and determine if our indexes are effectively being used:
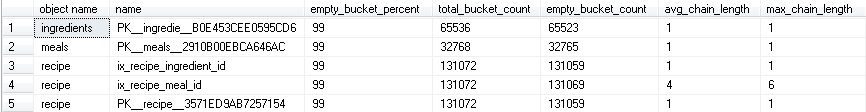
Microsoft recommends that the total_bucket_count be about 2x-4x the number of unique key values. Too many buckets will result in wasted memory whereas too few buckets will result in slower searches when a bucket contains many key values. A table scan will scan ALL buckets, including empty buckets. As a result, an excessively large empty bucket count will negatively impact table scans. As an aside to the data above, the number of buckets in a hash index will always be rounded up to the next power of 2 from the value you provide when the table is created.
The empty_bucket_percent is an indicator of how much space is left in the index before buckets need to start being reused for key values. Having about 1/3 of the buckets empty allows for a safe level of growth. dm_db_xtp_hash_index_stats can be used to monitor your hash indexes en masses to determine if any need to be recreated with a larger bucket count.
The avg_chain_length tells us, on average, how many keys are chained in each bucket. Ideally, this value would be 1, or at least close to 1. A high value for this stat can indicate that there are many duplicate keys in your index. If this is the case, it may be worth considering using a standard nonclustered index instead. A high avg_chain_length can also indicate that the bucket count is too low, forcing buckets to be shared. Recreating the index with a higher bucket count will resolve this problem.
Our example above is far too small to be able to analyze with any intention to optimize it, but it illustrates the layout of this DMV and how the data will look when returned. Hash indexes are extremely efficient for equality searches and scans and this new view will allow you to make the best decisions with regards to their creation, usage, and maintenance.
sys.dm_db_xtp_nonclustered_index_stats
This view tracks index usage statistics on all nonclustered indexes. This does not include hash indexes, though, which are included in dm_db_xtp_hash_index_stats. In order to illustrate its usage, we will create an additional table with a standard nonclustered index, and then analyze the data in the view:
CREATE TABLE dbo.reviews (
review_id INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000),
review_title VARCHAR(50) NOT NULL,
review_content VARCHAR(2000) NULL,
meal_id INT NOT NULL INDEX ix_review_meal_id NONCLUSTERED
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
INSERT INTO dbo.reviews VALUES ('Delicious tacos!', 'This recipe made very flavorful tacos. I''d add jalapeno peppers next time.', 1)
INSERT INTO dbo.reviews VALUES ('This meatloaf is OK...', '', 2)
INSERT INTO dbo.reviews VALUES ('Yikes!', 'Needs...more...sugar...badly...', 3)
GONow, we can run a query on this view, referencing sys.indexes in order to grab the index name:
SELECT
object_name(dm_db_xtp_nonclustered_index_stats.object_id) AS 'object name',
indexes.name,
dm_db_xtp_nonclustered_index_stats.*
FROM sys.dm_db_xtp_nonclustered_index_stats
INNER JOIN sys.indexes
ON indexes.index_id = dm_db_xtp_nonclustered_index_stats.index_id
AND indexes.object_id = dm_db_xtp_nonclustered_index_stats.object_idRunning this query returns data that will look similar to this:

Using this large amount of information, we can quickly see how large our index is, as well as how often it is being written and read, similar to existing index DMVs that track standard indexes for non-memory-optimized tables. 6 columns in this view reference retry counts and are worth keeping an eye on. A high number of retries signifies a concurrency issue as SQL Server is unable to perform a specific action on the index. Strangely enough, Microsoft’s recommendation for handling this issue is to give their Support staff a call:
http://msdn.microsoft.com/en-us/library/dn645468%28v=sql.120%29.aspx
sys.dm_xtp_gc_stats
sys.dm_xtp_gc_queue_stats
sys.dm_db_xtp_gc_cycle_stats
SQL Server 2014 utilizes a system garbage collector that will clean up old versions of rows in memory. When a row is deleted or updated (updates are essentially a delete & insert), the old version that was deleted becomes garbage. An End Timestamp is populated in the row header, indicating when the row was deleted. It is up to the garbage collection process (which is run by both system and user processes) to free up the memory so it can be reused. For the sake of this article, I’ll keep the DMV descriptions brief, but more info can be found on the specific columns for each of these DMVs on MSDN.
dm_xtp_gc_stats provides general statistics on the garbage-collection process. This data applies to all In-Memory OLTP data across the entire SQL instance, and is not limited to the current database.
dm_xtp_gc_queue_stats will return a row for each logical CPU on a database server. Each row represents a garbage collection worker queue and the current & total work it has performed. The key metric to watch out for in this view is if the current_queue_depth is growing and not being processed. This can be caused by long-running transactions and can be a sign of inefficient SQL. This view also applies to in-memory garbage collection across an entire SQL server.
dm_db_xtp_gc_cycle_stats manages committed transactions that have deleted rows, causing stale data. These transactions are moved into queues associated with generations, depending on when they were committed with respect to the last active transaction. If memory pressure occurs on a server, garbage collection will move through this data in order of the age of transactions (oldest first).
Another 8 views were added in SQL Server 2014 that relate to In-Memory OLTP, but I will not cover in detail here due to lack of space to elaborate on their usage and how their underlying features tie to the DMV. The remaining views are comprised of 4 database-specific views as well as 4 instance-specific views:
sys.dm_db_xtp_checkpoint_files
sys.dm_db_xtp_checkpoint_stats
sys.dm_db_xtp_merge_requests
sys.dm_db_xtp_transactions
sys.dm_xtp_system_memory_consumers
sys.dm_xtp_threads
sys.dm_xtp_transaction_recent_rows
sys.dm_xtp_transaction_stats
DMV Removal/Deprecation?
Based on all of Microsoft’s documentation, as well as experimentation, no DMVs have been removed in SQL Server 2014, nor have any been deprecated for removal in a future version. No columns were removed from any views either, though many were added.
Conclusion
To help compare all of the changes in dynamic management views from SQL Server 2012 to SQL Server 2014, I have attached an Excel spreadsheet that contains a row for each DMV in each version of SQL Server. Rows highlighted yellow were mentioned in this article while the rest were either unchanged or did not receive significant enough change to warrant further discussion.
