

Introduction
During a migration project that was porting a very large database system from SQL Server 2005 to SQL Server 2016, I was given the task of checking a few SSIS packages for correctness and completeness. If need be, I was to do some minor bug fixing. At least, that was the plan.
But few plans ever survive contact with the enemy, it seems. These packages had been created by a developer working for the customer, containing functionality carried over from legacy DTS/SQL Server 2000 packages. They ran perfectly on the SQL Server 2005 server, but would obviously not be supported anymore on the new platform. The packages were mostly correct, but one of them was lacking a clever bit of functionality that had been added to a DTS package by one of my colleagues, not knowing that the SSIS 2016 R&D at the customer’s had already started.
Having already exceeded the allotted time for the project, I needed a solution pretty quickly. I did a bit of searching on the Internet to see whether someone else had already dealt with this problem, but found only a few solutions. These required a heck of a lot of code to make the Flat File Source do something it was never designed to do. At the end of the day things were just not working properly, so it was decided that for the time being this functionality would not be included in the finished product. Each change in the incoming files would have to lead to the delivery of a new version of the package.
I had a couple of weeks off and, as it so happens, I had a good idea while enjoying the rest. The below image shows an overview of the resulting sample package containing my proven solution.
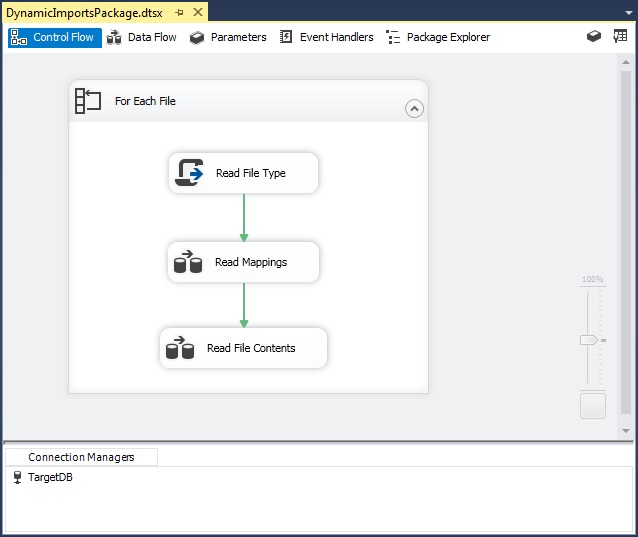
The Challenge
That clever bit of functionality was dynamic column mapping while reading flat files containing GRP ratings, pertaining to various commercial television channels, which cater for specific demographic groups of people, known as “target groups”. All incoming files share the first two columns, which identify the channel and the time-band, while the rest of the columns contain the ratings for the target groups relevant to the channel at hand. Files contain ratings for up to 30 target groups, for every minute during which a channel broadcasts programs and commercials.
Some channels may have partly overlapping target groups, but by and large, the selection of target groups defines a television channel’s audience, so the ratings are key to determining the value of a commercial break to advertisers. The identification of the target groups representing the numbers in each ratings column is specified in the first row of the files. There is a table in the database that maps file column names to the names of columns in a staging table used further downstream, where the imported ratings are finally processed.
DTS supported this scenario quite efficiently, by allowing you to create a transform that decided where the data should go based on information provided at run-time; a database table, in this case.
The Flat File Source
The Flat File Source of SSIS, however, unless I have overlooked something, does not support this sort of flexibility right out-of-the-box. As time for R&D activities is forever in short supply during office hours, it’s quite a scare to encounter a dead-stop like this, when time is running out.
The solutions I found were running scripts to somehow persuade the Flat File Source to comply, and that is by no means a trivial task. The Flat File Source uses the Flat File Connection, which persists a lot of meta-data about the file and its contents. This is actually a virtue, in my humble opinion, as it provides a fast and relatively type-safe mechanism of reading file contents, even allowing you to view passing data during debugging sessions.
At run-time, this meta-data is validated against files and database connections and, if a discrepancy is encountered, package execution halts, the job fails, and an error is reported stating that the package “needs new meta-data”. This usually happens when things like field length or data type changes take place, or when there’s a change in the code page specified for a field or a database.
As I mentioned, the solutions I found implemented lots of code to achieve some degree of flexibility when reading files. These would require a huge amount of time to implement and maintain in this particular package, which runs very frequently every day to read incoming files. This is done to prevent the buildup of a backlog of files from draining the server’s resources.
Every line of code is a liability if you are responsible for support and maintenance of such a package in a heavy workload production environment with hundreds of users, who take a dim view of the “busy” cursor on their screens.
I decided the Flat File Source was definitely not the weapon of choice.
When Stuck, Turn Left
Investigating what options were still available, I briefly evaluated the possibility of creating a custom data-source in the shape of a CLR assembly that would then have to be installed on a beefy, but already heavily burdened server. I was pretty sure it was going to work perfectly, but fearing the poor maintainability of this approach in such a complex production environment, I decided this would be my last resort, if all else failed to deliver a better solution.
For maximum flexibility I elected to use the Script Component, which allows one to fully customize the process of reading incoming data from any accessible source. At the same time this provides the required type-safety in its non-dynamic definitions of the outputs of the Script Component. This is not the Script Task, mind, but the Script Component, available within a Data Flow Task.
The First Step
In this particular case, all incoming files follow a naming pattern, from which the source and format of any file can be determined, as well as the date the ratings are to be associated with. Determining the file format was easily incorporated in another task already in the package, but to this example, the step of determining file format is trivial. For the sake of simplicity, I’ve included this step in a very simple script task, which reads the file name and updates an integer variable used in the next step to filter column mappings.
If this article provides a solution to your problem, then depending the specific functionality of your package, there will probably be better, more appropriate ways of determining the file format in order to filter column mappings to match a given file.
Reading the Map
The Read Mappings task runs the following query to retrieve the relevant mappings records, based on the previously determined file format. It uses a “?” as the parameter placeholder. The left join on the mappings table guarantees that there will be a mapping record for all of the columns in the staging table, even if there’s no mapping for any particular column. This approach allows not only for variable column names in files, but also for a variable number of columns. Limited, of course, to the number of columns in the staging table.
SELECT
ISNULL(TempTableMappings.MapFromField, columns.name) AS FileColumnName,
CAST(columns.name AS VARCHAR(50)) AS MapToOutPut,
CASE LOWER(systypes.name)
WHEN 'bigint' THEN 'System.Int64'
WHEN 'bit' THEN 'System.Boolean'
WHEN 'datetime' THEN 'System.DateTime'
WHEN 'decimal' THEN 'System.Decimal'
WHEN 'float' THEN 'System.Double'
WHEN 'int' THEN 'System.Int32'
WHEN 'money' THEN 'System.Decimal'
WHEN 'numeric' THEN 'System.Decimal'
WHEN 'real' THEN 'System.Single'
WHEN 'smalldatetime' THEN 'System.DateTime'
WHEN 'smallint' THEN 'System.Int16'
WHEN 'smallmoney' THEN 'System.Decimal'
WHEN 'tinyint' THEN 'System.Byte'
WHEN 'uniqueidentifier' THEN 'System.Guid'
ELSE 'System.String'
END AS OutputDataTypeName,
columns.is_nullable AS IsNullable
FROM sys.columns
INNER JOIN sys.tables
ON columns.object_id = tables.object_id
INNER JOIN sys.systypes
ON columns.system_type_id = systypes.xtype
LEFT JOIN dbo.TempTableMappings
ON columns.name = TempTableMappings.MapToField
AND TempTableMappings.MappingFormatID = ?
WHERE tables.name = N'TempTable'
ORDER BY columns.column_idWhen executed against a database created with the script provided with this article, the results should look like this for file format 1:
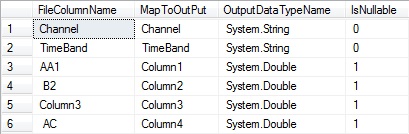
Fig 1 - File format 1
And this for File Format 2:
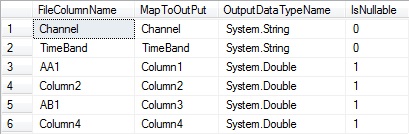
Fig 2 - File format 2
In these mappings, two of the specified file column names for file format 1 have leading spaces. Though it’s easy enough to trim them off, I’ve decided not to, because it’s a typo easily made by anyone. When incoming files have this issue, it’s easy to update the mapping until the source of the files has fixed it permanently. With this type of automation, resilience to some degree of abuse is key to provide dependable components that report issues and continue to function properly, rather than failing a much larger task entirely.
Besides, SQL Server still supports spaces in table and column names, as executing this statement will prove: CREATE TABLE dbo.[ ]([ ] INT); This does make the Object Explorer tree of SSMS look rather strange though.
File format 2 has less columns than format 1, but, as we’re guaranteed to have a mapping for every column in the staging table, no effort needs to be made in the script to deal with variable column count. Missing columns just map to themselves, remain empty and will be ignored during the final processing of imported ratings.
Both formats share a mapping for target group, “AA1”, while the other mappings are unique to each format, so there is some overlap in target audience between these channels. The important thing, however, is that in either case, the ratings for target group AA1 end up in Column1 of the staging table. This makes it possible to correctly interpret the raw data during final processing further downstream.
The results of the above query are stored in a Recordset Destination associated with package-level variable User::MappingsRecordSet. The data-type of each column in the staging table is translated to its best fitting managed counterpart, which information will be used to create the columns for an in-memory buffer table to collect file contents before pushing it to the output of the Script Component.
The Script Component
The final stage in the file import consists of the data flow below. The destination is just a regular OLE DB Destination that uses the TargetDB connection; no surprises there. The “Read File Contents” Script Component is where the magic happens. You can see my Data Flow structure below.
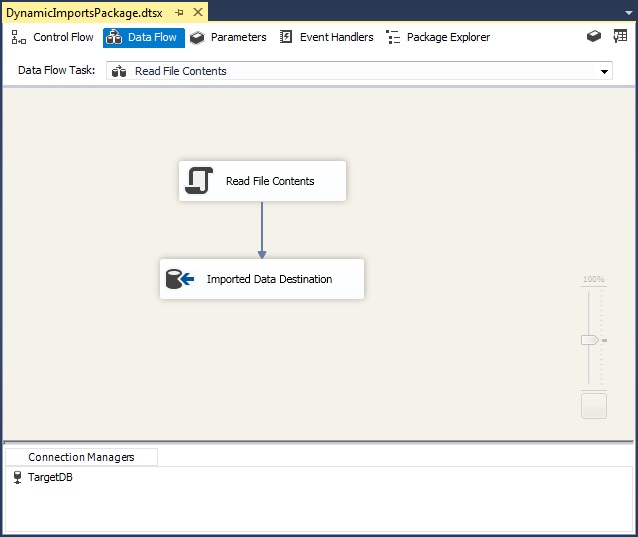
The Script Component class exposes a few interesting methods that can be overridden: PreExecute, CreateNewOutputRows, and PostExecute. There’s also the ComponentMetaData object, which allows the running script to report progress, warnings or errors to the package, by calling either of the FireInformation, FireWarning, or FireError methods. This information can be viewed during debugging sessions and also in the “All Executions” report provided by the SSIS Catalog on the host server. This is very helpful when investigating why a job failed.
During the pre-execute phase, a DataTable is being created based on the previously retrieved mappings. Initially, all columns are assigned the names as specified in the “FileColumnName” field of the mapping table. This DataTable serves as a buffer to temporarily store the values being read from the file, until the CreateNewOutputRows method override has finished sending them downstream on the component’s output, which is defined to match the structure of the staging table:
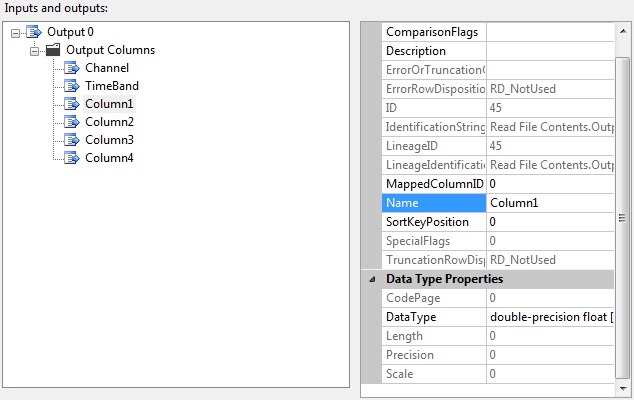
As I said, these output columns are non-dynamic, with their definitions persisted within the package the same way the Flat File Source and Flat File Connection objects do. After creating the outputs, the structure of the defined output columns materializes in the script, which will contain a few auto-generated classes providing the hard-coded wiring that matches the structure of the outputs.
This design allows for any connected transform or destination to read the source’s meta-data and validate its own properties at both design-time and run-time, while supporting the familiar designer interface with which you define the rest of the data flow. When you connect a destination or a transform to a Script Component’s output, if the names and data types of the output columns match the structure of the targeted database table, the mappings will probably be automatically detected.
A Simple Solution
The aforementioned good idea was to take a step back, think outside of the SSIS toolbox and to explore the object-oriented approach: by extending a standard component to fit the requirements. Any declaration of an object within the class that defines a Script Component, can be shared between all methods in the class, right? In this case, the Read File Contents script defines a nested private class, which extends the standard DataColumn class, adding the MapToColumn string property to its public interface.
Private Class MappedDataColumn
Inherits DataColumn
Public Sub New(ByVal columnName As String,
ByVal mapToName As String,
ByVal dataType As System.Type,
ByVal allowNull As Boolean)
MyBase.New(columnName, dataType)
AllowDBNull = allowNull
MapToColumn = mapToName
Unique = False
End Sub
Public Property MapToColumn As String
End ClassWhen the buffer table is being created during the pre-execute phase, its columns are instances of the above class. Thus, each column will have two names: the name matching the column as specified in the file and its mapped name, matching the target column’s name in the staging table. The constructor also specifies data type and nullability, so each column requires only a single line of code to create:
_BufferTable.Columns.Add(New MappedDataColumn(columnName, columnMapToName, System.Type.GetType(columnMapToType), isNullable))
Reading File Contents
The actual reading of a file’s contents is performed using the Microsoft.VisualBasic.FileIO.TextFieldParser class, which is capable of doing a lot more than just parsing. For example, it lets you specify the delimiter and whether or not to preserve white space. It exposes the ReadFields method, which, as the name suggests, reads a single line from a file and returns a string array of values while progressing focus to the next line in the file.
As each line is being read from the file, the script validates the contents to ensure proper handling of exceptional situations. For example, if it encounters a column name that is not found in the mappings table, the column in question will be ignored, while other columns continue to be imported. Additionally, if during the reading of the data rows the script encounters exceptions, such as an invalid cast exception, a format exception or an overflow exception, it is assumed the column might have the same problem in consecutive rows. This leads to ignoring the column’s contents from then on.
In these cases the problem is reported to the package, so that the “All Executions” report will tell you exactly where to fix things. The good news being that if the problem is caused by the file contents not being compliant with the agreed standards, you can just send a screenshot to the customer, who will ask the source of the file to fix the problem and re-submit the file. In my experience, the more verbose the problem reporting during package execution, the less likely it is that I have to investigate any code to find a logical explanation for the exception.
An example of a problem during execution is shown below.

Even though the ratings columns in the staging table are all nullable, if the package encounters a missing value, the column will be ignored and reported as having an issue. This just seemed the appropriate thing to do with the package in question. Those columns need to be nullable, because unmapped columns will always remain empty and this is required to allow for a variable column count in incoming files. But individual ratings going missing is a problem that needs to be reported and dealt with.
Localizing File Contents
When reading floating point values from a file, the important thing is to make sure the decimal sign will be interpreted correctly. In some countries this is a decimal dot while others, such as the Netherlands, use a decimal comma. Get it wrong and you will end up with values that are off by quite a large factor, messing up the results of any calculations applied afterwards. This will cause you a big headache when you have to somehow determine which values to correct in a production database.
To mitigate this risk, the script uses the LocaleID as specified on the data flow to create an instance of the CultureInfo class, which it uses when converting values from the file to the data type of their mapped destination. This affords us the possibility of easily making this behavior configurable from the outside by changing the locale from a SQL Server Agent job that runs the package. So the package can run quite happily in any part of the world, without the need for code changes to handle any cultural differences.
If your files are coming in from multiple countries, such that the decimal sign might vary from file to file, you can simply store the applicable LocaleID in the database to be retrieved by the mappings query and extend the script to accurately convert incoming values to the locale specified on the database or the server.
Mapping Columns
At the end of the pre-execute phase, when all of a file’s contents have been stored in the buffer table, we no longer need to call the columns by their names as present in the file. Then the following three lines of code perform the actual task of mapping the values contained within the buffer:
For Each column As MappedDataColumn In _BufferTable.Columns
column.ColumnName = column.MapToColumn
NextAs the mappings query reads the MapToColumn names from the sys.columns table, we’re guaranteed their existence in the staging table. Each column is simply renamed and from here on in, the columns in the buffer will be retrieved using their mapped names, matching the staging table column names.
Pushing the Output
When the PreExecute method returns, the SSIS runtime calls the CreateNewOutputRows method. In my implementation in the sample package, this method cycles all rows in the buffer, checks for individual values being Null, and if they are Null, explicitly sets the output value to Null. Otherwise the column’s value on that particular row is sent down the output. As the structure of the staging table is not going to change anytime soon, I can cast the value hard-coded to the required data-type, System.Double as it is in this case. I have only one column represented in the below code snippet.
For Each row As DataRow In _BufferTable.Rows
Output0Buffer.AddRow()
If row.IsNull("Column1") Then
Output0Buffer.Column1_IsNull = True
Else
Output0Buffer.Column1 = CType(row.Item("Column1"), Double)
End If
NextConclusion
Having done the research at my leisure, the solution presented in this article was easily implemented in the package, just before final testing and delivery were due, and that was that. The script reading the files has been running flawlessly many times a day, for over a year now.
No support required.
Cool.
Using the Code
The zip-file with this article contains the files to set the stage for testing this approach. The provided package has been created using BIDS 2015 and compiled against an SQL Server 2014 instance, so as to provide support for more than one version of SSIS and SQL Server.
Extract the files, open the Create Database Script and change database file locations as needed and run the script. Then create a new SSIS project and drop the package in it. Update the properties of the TargetDB connection to use the newly created database and specify valid credentials as applicable. Set the ProtectionLevel property of the project to DontSaveSensitive.
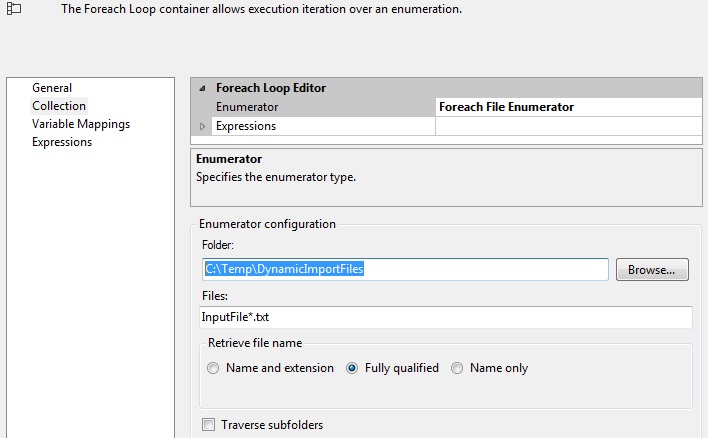
Then place the test files in folder C:\Temp\DynamicImportFiles, or edit the For Each File Loop container’s properties (shown below) as appropriate and press F5 to start the package in debug mode.
Further Fine-tuning Options
The original DTS package did not have the wiring to send rejected rows to an error output, and the migrated package did not require this to be implemented, so it’s not included in this script. But that should be easy enough to implement in case your project so requires.
As mentioned previously, you might choose to extend the script and store a LocaleID for each file format in the database, so that regardless the originating culture of a file, the system always interprets decimal values and dates correctly.
It might not be a bad idea to include a step that sends an e-mail message to an administrator in the event of a warning or an error. I did evaluate this option, but decided against it because many administrators implement their own triggers to warn them in such cases and might not expect a package to send messages on its own.
You might also opt to change some reported warnings to errors as required in your project, to halt package execution in stead of just issuing a warning while the package continues executing.
Ideally, the application which uses the database, should include a screen which can be used to manage the mappings in a secure fashion, validating the specified mappings against file and database structures
About the author

I’m a software developer with over 9 years’ worth of SSIS experience, working on projects involving C#, VB.Net, SQL Server, SSAS, SSIS and legacy VB6.
I believe that no single toolbox could ever be large enough, to contain every tool you might need. That’s why I have a keen interest in finding out how standard components might be gently manipulated to provide extraordinary functionality.
