

Overview
Clustering SQL Server 2005 Services in Windows Server 2003 has been greatly enhanced from SQL 2000 on Windows 2000 clusters. There are quite some excellent articles in the internet offering guidance on cluster topics ranging from preparation, installation and configuration to post installation maintenance. On the other hand, the enhancements by the new versions also created certain confusions regarding cluster group failover behaviors due to the fact that the new failover behaviors are significantly different from what we used to expect from the older versions. The proof is that there are some questions posted in news groups complaining about something like "My SQL Server 2005 database engine failed last night. But the resource group didn't fail over to the passive node. Is the failover cluster not working? Why? Help! ".
To answer this kind of questions, we need to drill down to several basic Windows Server 2003 cluster concepts. There are several configuration items within the Windows 2003 Cluster Administrator tool that we need to explore in more details to get a better understanding about how the cluster failover works according to these configuration settings. This is important because it can help us take full advantage of the new failover mechanism offered by Windows Server 2003 and SQL Server 2005 to design a better failover solution to fit in individual Service Level Agreement (SLA) requirements.
About Cluster Administrator (CluAdmin.exe)
Cluster Administrator is a Microsoft Windows administrative tool to manage clusters in your domain. It is not part of the Administrative Tools programs by default. It is available after the Windows Cluster services are installed in your servers. It can also be installed in your Windows XP professional workstation as part of the Windows Server 2003 Admin tools Pack (adminpak.msi) installation. The pack can be downloaded from Microsoft website http://www.microsoft.com/downloads/details.aspx?FamilyID=c16ae515-c8f4-47ef-a1e4-a8dcbacff8e3&displaylang=en
Configure Cluster Properties
Once you have this tool ready for use either in Cluster node servers or in your local workstation, and you have administrative privileges to the clusters in your network, then you can launch it to examine, configure and manage a wide variety of cluster properties. This article will only focus on the following two levels of properties that have significant impacts on SQL cluster resources failover behaviors. The two levels of cluster properties are Group level and Resource level. Group properties have impact on all resources under the group, while Resource properties can have impact on its own resources most of the time with the exception of the "Affect the group" option, which will be covered with more details later in the article.
There are a number of Group and Resource cluster properties available for us to configure. However, we only focus on the ones that matter the failover behaviors. You will find these properties by right click on a Group or Cluster Resource and select Properties.
Group Level Properties:
Failback: The properties can be found under Failback tab of a group properties window. It specifies what should happen when the group comes back online, and finds itself owned by a node other than its original primary node. Choose "Prevent Failback" to prevent the group from failing back to a failed node that returns to online status. Choose "Allow Failback" to enable failback. You should also specify that the failback will either occur immediately or within a specified span of hours.
What does this mean: In most cases, we should stick with the default setting of "Prevent Failback" to prevent an additional unnecessary failover. This will leave you more room and time to determine what caused the service failure and plan on a better time to fail it back once the root cause of the problem gets resolved. Otherwise, you will find your SQL services may have to be interrupted for twice as the cluster service trying to go back to its original primary node during an unpleasant time ( for a 24x7 server, any time could be unpleasant time unless it is scheduled ).
Resource Level Properties:
You can find these properties by right-click on the concerning Resource, and select Properties. The following properties are under the Advanced tab in the Resource Properties window.
Restart: to specify whether or not to restart the resource if it fails.
What does this mean: For most resources, the Restart option should be selected because you want all cluster resources to be kept online.
Affect The Group: If selected, the group will fail over when the resource fails. The Threshold and Period values determine how many times the Cluster Service will attempt to restart the resource for a specific attempts within a specified period of time before the group fails.
What does this mean: This may be the most important single item to configure. There are only a handful of resources should have this option turned on. And if it is turned on for the resource, the Threshold and Period values control whether you want the Group to fail over to the other node(s) immediately or try to recover on the same node for the specified times within the period of time. Usually we would want it to fail over to the other node immediately because trying to recover on the same node could possibly be a waste of time without knowing the cause of the issue. The following Resource should usually have the "Affect the group" option turned on:
- SQL Server database engine service
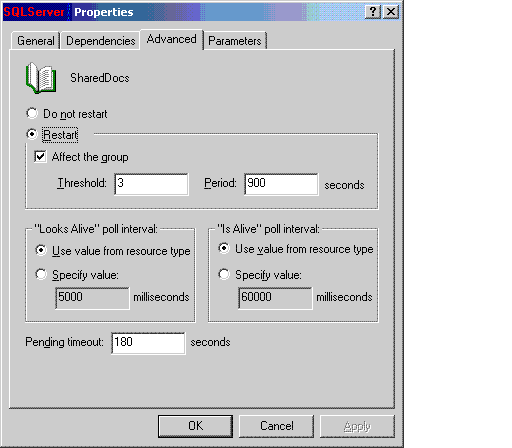
You may want to disable "Affect the group" option for the following resources to avoid unessential resources bringing down the entire group and the SQL engine.
- SQL Server Agent Service
- MSDTC
- Backup drives
- File share folders
In case these resources fail, investigations and manual restart should be performed without impacting the SQL engine service.
Below are the steps to configure SQL Server Agent Service so that a failure to the SQL Agent resource does not affect the group
- Log on to any node of the cluster.
- Start Cluster Administrator.
- Under Groups, click the cluster group that includes the SQL Server Agent Service resource.
- Right-click the SQL Agent Service resource and then click Properties.
- On the Advanced tab, clear the Affect the group check box, and then click OK.
Polling: Use the Looks Alive and Is Alive parameters to specify how often the Cluster Service polls the resource to determine if it is up
What does this mean: Usually we should use the default values of "Use values from resource type" unless you have a compelling reason for otherwise.
Pending Timeout: specify the amount of time a resource can be in a pending state before the Cluster Service fails the resource.
What does this mean: Same tactic as Polling should be applied to Pending Timeout. If there are issues with your cluster that require adjusting this parameter to avoid certain problems, you may want to tackle the root cause rather than playing around with the number unless this is your last resort.
Dependencies: This property is under Dependencies tab in the Resource Properties window to specify what other cluster resources are required online as a prerequisite for the resource to maintain online status.
What does this mean: This is the cluster resource internal integrity checking mechanism and it is a very important property to configure. For example, if the master database resides on cluster share H drive, then we have to make sure SQL Service has a dependency on H drive, such that SQL Service will wait for H drive being online before trying to bring itself online. Otherwise we will see error message if H drive is still in the process of bringing online when the SQL service resource is trying to start up.
On the other hand, we should eliminate unnecessary dependencies for SQL services. We may want to remove SQL dependencies to resources not essential to database engine. For example, a dump/backup drive may not be a good candidate as a SQL dependency. (Noted that some database backup software does require this explicit dependency to make the drive available for operations)
File Share in Cluster
In addition to the above two levels of properties, share folders used by critical SQL functionalities such as log shipping and snapshot replications, should be made as cluster resources. Local Windows folder share names on each node may be lost when failover occurs.
For example, you create a folder share named "My_File_Share" on share drive F of the active node. If you don't defined the share folder as a FileShare cluster resource, the share name "My_File_Share" may not be recognized in the cluster after drive F fails over to another node. So the best practice to keep your folder share names is to make them cluster resources in the same group of the SQL engine services. To create a Clustered file share, please see KB article How to create file shares on a cluster (http://support.microsoft.com/kb/224967) for detailed steps.
Conclusions
The above provided basic descriptions and configuration guide lines of the following configurable items: Failback, Dependencies, Restart, Affect Resource Group and its child parameters. All of the items could have significant impact on the SQL cluster group's failover behaviors. Users should be aware of the implications before implementing any of settings, and should test the adjusted environments to see if the changes match with your design expectations before roll out to production environments.

