

Introduction
SQL Server 2016 introduced the Compress() function that allows users to reduce the overall size of data stored in fields by compressing it to a varbinary value using the GZIP algorithm. It also introduced Decompress(), which will convert that compressed varbinary value back to its full state where it can be converted to a human readable value. In this article, we are going to walk through using these two functions against different kinds of data by creating some test data, comparing data lengths of raw and compressed values, decompressing the values, and comparing storage. I am by no means an expert in compression algorithms, so this article will not be diving into the mechanisms of GZIP, discussing the merits of the algorithm, or going into detail as to exactly why values compress the way they do.
Setup
First, we are going to create a table and populate it with some dummy data. I created 5 rows, but one of the rows was the HTML source code from a page on SQL Server Central, so I will exclude it from this write up for the sake of readability. The reason I chose it was to represent non-uniform data. So feel free to pop over to another webpage, right-click, grab the source code of the page, and use that value if you want.
CREATE TABLE CompressTesting(
ID INT,
Val_Varchar VARCHAR(MAX),
Val_NVarchar NVARCHAR(MAX)
)
GO
INSERT INTO CompressTesting(ID, Val_Varchar, Val_NVarchar)
VALUES
(1, 'This is a short test string with a non alpha char!', N'This is a short test string with a non alpha char!')
,(2, '2349798237498273324', N'342353453454252352')
,(3, REPLICATE(CAST('X' AS VARCHAR(MAX)), 9000), REPLICATE(CAST(N'X' AS NVARCHAR(MAX)), 4500))
,(4, REPLICATE(CAST('abc123' AS VARCHAR(MAX)), 9000), REPLICATE(CAST(N'abc123' AS NVARCHAR(MAX)), 4500))
-- ,(5, Lots of HTML code here. Add whatever you would like.
GOQuerying Data
Now that we have a table, let's start playing around with it. First, we want to examine our data lengths and see what we have.
SELECT
id
, val_varchar
, varchar_DL = DATALENGTH(val_varchar)
, val_nvarchar
, nvarchar_DL = DATALENGTH(val_nvarchar)
FROM compresstesting
ORDER BY id
; At first, we don't have anything really exciting. Just some short and long strings representing both repeating data and also randomish data.

Figure 2-1: Query output showing strings and data lengths for both unicode and non-unicode data.
Let's bring in the Compress function and see what happens. Compress uses the GZIP algorithm to compress the value passed to it, so lets apply it to the values.
SELECT
id
, val_varchar
, varchar_DL = DATALENGTH(val_varchar)
, varchar_compress = COMPRESS(val_varchar)
, varchar_DL_compress = DATALENGTH(COMPRESS(val_varchar))
, val_nvarchar
, nvarchar_DL = DATALENGTH(val_nvarchar)
, nvarchar_compress = COMPRESS(val_nvarchar)
, nvarchar_DL_compress = DATALENGTH(COMPRESS(val_nvarchar))
FROM compresstesting
ORDER BY id
; 
Figure 2-2: Output with Compress() data lengths
Now we can see some interesting things. First, our very short strings actually have a longer data length after being compressed. We also see how well our uniform data compresses. Strings of the same value or repeating values compress very well, and the efficiency of the compression increases as the string gets longer, as evident by comparing id 3 to 4. And lastly, our HTML code that is not uniform at all still has a large reduction in size, but not nearly as profound as the repeating values.
Next, we are going to store our compressed values somewhere and then decompress them. Let's make a new table for the varbinary data.
CREATE TABLE Compressed_Values ( val VARBINARY(MAX) ) GO INSERT INTO Compressed_Values (val) SELECT COMPRESS(val_varchar) FROM CompressTesting GO SELECT val FROM Compressed_Values
To decompress the value back into a human-readable format, just pass the varbinary value to the Decompress function and cast it back to a varchar.
SELECT val, CAST(DECOMPRESS(val) AS VARCHAR(MAX)) AS readable_val FROM Compressed_Values
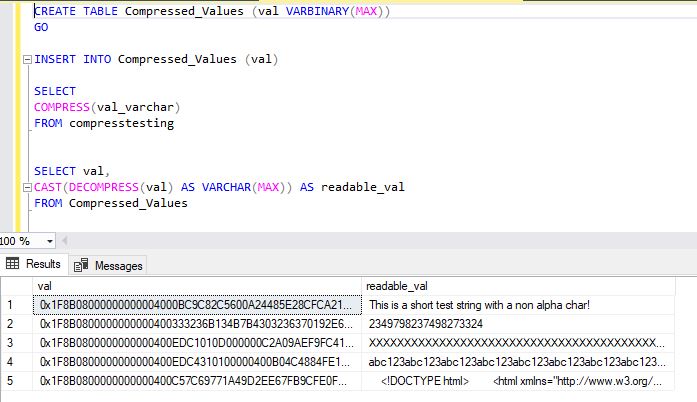
Figure 2-3: Storing compressed value and decompressing it
The Compress and Decompress functions can also be used in calculated columns. Entire tables of large strings can be stored compressed and returned in a human-readable format on the fly without taking up more storage.
ALTER TABLE Compressed_Values ADD computed_decompress AS CAST(DECOMPRESS(val) AS VARCHAR(MAX)) GO SELECT val, computed_decompress FROM Compressed_Values
Checking Storage
Now that we are comfortable playing around with our two functions, let's see how it translates into storage. I am going to use a script close to what we used to generate our sample table, but this time only store the id and the uncompressed value and run it 40,000 times.
CREATE TABLE CompressTesting(
ID INT,
Val_Varchar VARCHAR(MAX)
)
GO
INSERT INTO CompressTesting(ID, Val_Varchar)
VALUES
(1, 'This is a short test string with a non alpha char!')
,(2, '2349798237498273324')
,(3, REPLICATE(CAST('X' AS VARCHAR(MAX)), 9000))
,(4, REPLICATE(CAST('abc123' AS VARCHAR(MAX)), 9000))
-- ,(5, Lots of HTML
DROP TABLE CompressTesting
GO 40000
And in another database, I am going to create a table to store the id and compressed value from the table we just made.
CREATE TABLE Compressed_Values ( ID int, val VARBINARY(MAX) ) GO INSERT INTO Compressed_Values (id, val) SELECT id, COMPRESS(val_varchar) FROM sqlfundo2016.dbo.compresstesting
When we examine the sizes of the tables, there is a drastic difference in size. The id and compressed value table is about 10% of the size of the non-compressed data table
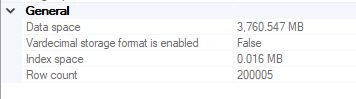
Figure 3-1: Non-compressed data field table
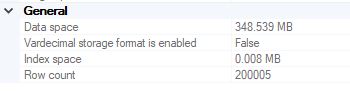
Figure 3-2: Compressed data field table
Wrapping Up
The Compress and Decompress functions make it very easy to err on the size of storing more data rather than less data. If you have an application you want to capture entire JSON responses from, or entire debug/stack trace dumps, you can simply compress the enormous value as a string and store it in a table. And whenever you need it for troubleshooting, you can cast and decompress the value. These functions are very easy to work with and will save loads of storage in databases that can run decompress on stored values upon retrieval.
