

I've published two prior articles
(Case Sensitivity in Selects - Part 1
and Case Sensitivity in Selects - Part 2),
you'll benefit from reading
them before continuing with this one. I'd like to start by looking at part of a
great email I received from reader John Sands (check out his
blog!). As John explained, he read
the first article and wanted to make sure he understood the code AND it worked
before passing it around. Bravo! Anyway, he wrote because he was unable to
achieve the results I mentioned using the convert to binary option. I'll start
by including his text, then look at what happened. After that I'll discuss the
underlying problem that started this journey and see if I can come up with any
alternatives.
| I did this update in Northwind to test it: update Orders set CustomerID = 'frans', ShipCity = 'torino' where orderid = 10753 I did two columns to try nchar and nvarchar columns. CustomerID is char(5) and ShipCity is nvarchar(15). These queries return six rows: select OrderID, CustomerID, ShipCity from Orders where CustomerID = 'frans' select OrderID, CustomerID, ShipCity from Orders where ShipCity = 'torino' OrderID CustomerID ShipCity ----------- ---------- --------------- 10422 FRANS Torino 10710 FRANS Torino 10753 frans torino 10807 FRANS Torino 11026 FRANS Torino 11060 FRANS Torino (6 row(s) affected) OrderID CustomerID ShipCity ----------- ---------- --------------- 10422 FRANS Torino 10710 FRANS Torino 10753 frans torino 10807 FRANS Torino 11026 FRANS Torino 11060 FRANS Torino (6 row(s) affected) I want to return just the lowercase row but NONE of these return any results: select OrderID, CustomerID, ShipCity from Orders where convert(varbinary(50), CustomerID) = 'frans' select OrderID, CustomerID, ShipCity from Orders where convert(varbinary(15), ShipCity) = 'torino' select OrderID, CustomerID, ShipCity from Orders where convert(varbinary(5), CustomerID) = 'frans' select OrderID, CustomerID, ShipCity from Orders where convert(binary(5), CustomerID) = 'frans' select OrderID, CustomerID, ShipCity from Orders where convert(varbinary(5), CustomerID) = convert(varbinary(5), 'frans') select OrderID, CustomerID, ShipCity from Orders where cast(CustomerID as varbinary) = cast('frans' as varbinary) select OrderID, CustomerID, ShipCity from Orders where cast(ShipCity as varbinary) = cast('torino' as varbinary) select OrderID, CustomerID, ShipCity from Orders where cast(CustomerID as binary) = cast('frans' as binary) select OrderID, CustomerID, ShipCity from Orders where convert(binary(5), CustomerID) = convert(binary(5), 'frans')
|
He's exactly right, none of those work! Took a few minutes to figure out, but
the culprit was that the customerid column was an nchar. Because it's a binary,
you have to make sure to compare apples to apples. To help me figure
out what was going on, I included the converts in the select so I could see
exactly what was occurring, like this:
select OrderID, CustomerID, ShipCity, convert(varbinary(5), convert(varchar(5), customerid)), convert(varbinary(5), 'frans') from Orders where convert(varbinary(5), convert(varchar(5), CustomerID)) = convert(varbinary(5), 'frans')

Just another 'gotcha' when dealing with mixed case sensitivity.
As I mentioned way back in part one this all started with me tracking down a
performance issue. That got me curious and now that I've explored this ugly part
of SQL, it's time to see if I can't solve the problem more elegantly. Here is
basically the table I'm dealing with at work:
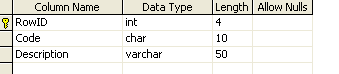
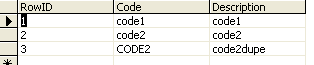
A pretty standard lookup table right? Well, where we got off track is that
the product that implements this was meant to run on multiple database platforms
and because (as I understand it) not all databases supported case insensitivity,
they went with the lowest common denominator. All that means is that they always
did a case sensitive comparison. We could have stopped the madness by just
making the column unique! Instead, we have junk like I've shown above where we
have a case insensitive column that has duplicate values that aren't duplicates.
That means we have to account for them in every join we do. What's worse, we
can't even easily stop users from adding more since we can't set a unique index
(case insensitive).
The first option is to identify the duplicates and remove them. To do that
you have to find every place where it might have been used and replace it with
the new code. Potentially in any of 40 or so columns across 10 tables in each of
about 200 databases. Doable, just takes a little time to set up. Once done I
could add a unique index to make sure the problem doesn't recur.
Now that I think about it, what's wrong with that? Do it and be done!
One thought I had was to add a new column called perhaps CodeInsensitive and
store a binary representation of 'Code'. That way I could still use the
technique I offered in article #1 about doing the join plus the compare, but now
I'd have the big part of the work already done. Why convert each time if you can
just do it once? Easy enough to maintain via a computed column or triggers, and
it would be indexable. Even uniquely indexable. Worth doing? Questionable I
think, doesn't seem like I'd gain much in performance over what I've already
done.
Tried to think of a way to use a view to help, but it doesn't take me
anywhere.
The only remaining option I can see is to modify everything that does the old
style case sensitive join to use the new method I described. I'll have to check
to see how many stored procs this might touch. Changing them is probably faster
than doing all the updates to remove the duplicates, about even in risk maybe.
At this point I haven't decided. Removing the duplicates is clearly the right
thing to do, just changing the code is probably faster. Tradeoffs to be made.
I imagine this only scratches the surface of issues you can have using
multiple collations. I think I'll just try to avoid them. In closing, you might
think about how case sensitivity affects other tools/languages. XML is case
sensitive. VB6 and VB.Net are not case sensitive, but the string comparisons
they do are unless you've set Option Compare Text on (please don't). C# and many
others the language is case sensitive.