

One of the main struggles I had (and still have) while working with R is getting my head around its data structures. R is an object oriented language, and the way it works with data is a little different from the relational model that we are used to in T-SQL. It is not very different, but one does have to know basic data manipulations well or you can spend a lot of time just wondering how to do what. Understanding how R stores data, what constitutes a unit of data – a field, a record, whatever – is really important to put R to good use.
In this post I will attempt to explore and explain some basic data manipulations. I am specifically only going to address a dataset – called a dataframe in R . There are many other types of variables and datatypes to explore, but this articles specifically looks at datasets since we, as SQL professionals, primarily need to understand that in order to use R with SQL Server.
I am using the Adventureworks for 2016 database here. In the below commands, I am connecting to the database from R Studio and pulling the data I need into a dataset. The dataset I am using is a simple T-SQL query as below:
USE AdventureWorks2016CTP3 SELECT DISTINCT TOP 10 P.ProductID, P.Name, P.ListPrice, P.Size, P.ModifiedDate, SOD.UnitPrice, SOD.UnitPriceDiscount, SOD.OrderQty, SOD.LineTotal FROM Sales.SalesOrderDetail SOD INNER JOIN Production.Product P ON SOD.ProductID = P.ProductID WHERE SOD.UnitPrice > 1000 ORDER BY SOD.UnitPrice DESC
This returns a dataset in Query Analyzer as below.
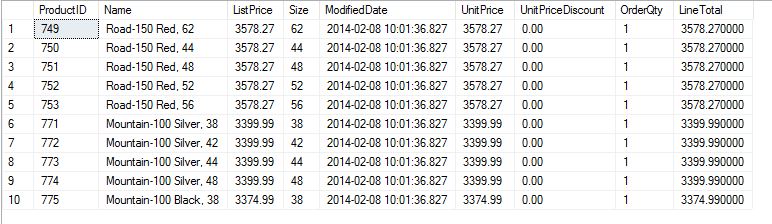
Now we are going to try and pull the same dataset into a dataframe variable in R studio.
After we connect to R studio, we need to install the necessary packages and load libraries to enable the connection to SQL Server first. This is something we have to do every single time we get into R to pull data from SQL server. Next, we connect to the database using the odbcserverconnect command and pull the results of the SQL query into a dataframe, called advdata. It is important to be aware that R will not return or display any information on the dataset when we pull it into a variable. This also includes any errors in the query we have provided. To see the results of the dataset, we need to type the name of the variable and then enter.
Install R package and libraries:
install.packages("RODBC")
library(RODBC)
Connect to the database and pull query results into a dataset:
cn <- odbcDriverConnect(connection="Driver={SQL Server Native Client 11.0};server=MALATH-PC\\SQL01;database=AdventureWorks2016CTP3;Uid=sa;Pwd=Mysql1")
advdata<-sqlQuery(cn, 'SELECT DISTINCT TOP 10
P.ProductID, P.Name, P.ListPrice, P.Size, P.ModifiedDate,
SOD.UnitPrice, SOD.UnitPriceDiscount, SOD.OrderQty, SOD.LineTotal
FROM Sales.SalesOrderDetail SOD INNER JOIN
Production.Product P
ON SOD.ProductID = P.ProductID WHERE SOD.UnitPrice > 1000
ORDER BY SOD.UnitPrice DESC')Below is the result from displaying the contents of the advdata variable that contains our dataset (same results as what we got with running the query in query analyzer).

Dataframes in R have rules similar to SQL tables in some ways,
- Two variables in a data frame cannot have the same name - like two fields in a table.
- All records or vectors as they are called in R terms have the same defined length.
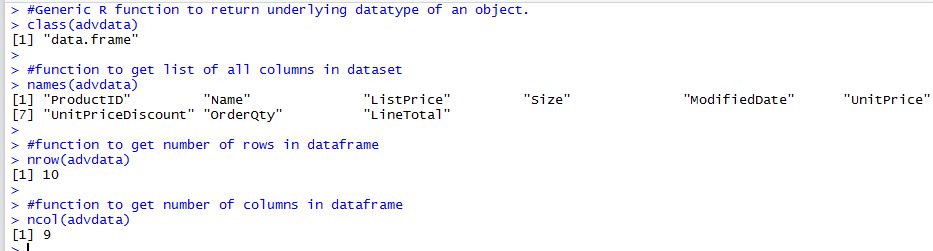
We can explore the properties of the data frame we just created using some functions.
- The 'class' function returns the datatype of the variable. In our case this is a data frame.
- The 'names' function gives us list of all columns.
- The 'nrow' function returns the number of rows in the dataframe
- The 'ncol' function returns the number of columns in the dataframe.
#Generic R function to return underlying datatype of an object. class(advdata) #function to get list of all columns in dataset names(advdata) #function to get number of rows in dataframe nrow(advdata) #function to get number of columns in dataframe ncol(advdata)
My results are as below:
How do I now refer to individual data elements in a data frame?
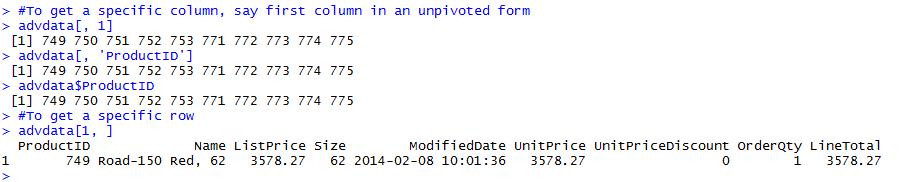
To get all the values in a specific column, refer to the name of the column or give a number that indicates the order it is in. For example, column 1 is productid. You can refer to it as advdata[1] or advdata["ProductId"]. To list all the values in a row or unpivot the same - we can say advdata[, 1] or advdata[, 'ProductID'] or advdata$ProductID. We may wonder why we need this, but the needs for this will become clearer as we use more advanced functions in R.
To get a specific row, we can provide rownumber as the first prefix. For example, advdata[1, ] lists row 1. It is important to be aware that R identifies rows by row numbers - if you look at above listing of the contents of advdata, we can see row numbers on the extreme left.
#To get a specific column, refer to the # of the column or name of the column advdata[1] advdata[‘ProductId’] #To get a specific column, say first column in an unpivoted form advdata[, 1] advdata[, ‘ProductID’] advdata$ProductID #To get a specific row advdata[1, ]
The results are shown below:
To get a subset of rows for any condition we can use the ‘subset’ function. The conditions can be "and", "or" or any combo of these logical operators. The operators can be used on rows or columns. The most common logical operators are & - AND, | OR and ! for NOT.
There are conditions like &&, ||, xOr, etc,, which apply to vector comparisons or set based comparisons. They are a topic for another post. This particular example only deals with individual element comparisons
For example, to pull the rows that match condition of size < 60 and listprice > 3500 - we can use query shown below.
#Getting rows based on and condition subset(advdata, advdata$Size < 60 & advdata$ListPrice < 3500)
Results are as below:

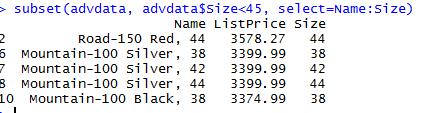
You can also query on a subset of the data. This is like a subquery in T-SQL. Here am selecting only the 3 columns name, listprice and size from my main dataframe and out of those, I need size > 45.
subset(advdata, advdata$Size<45, select=Name:Size)
Any subset of the dataframe in turn returns another dataframe which we can assign to a variable and manipulate in of itself. The variable does not get refreshed dynamically. It is similar to temp tables and table variables in T-SQL and has to be used as appropriate.
There is a huge number of permutations and combinations thus possible with sub queries.They are easy to learn with some practice and anyone with experience in T-SQL or Excel can learn them.
To summarize, we learned how to pull data from a SQL Server database into an R dataframe and you should now understand the structure of the dataframe. You should also understand how to pull various elements of data from the dataframe.
In the next post we can look at how to use this understanding to play with various R functions and come up with interesting findings. Thank you for reading!
