

Introduction
In this new article, we will learn how to connect to our Azure Data Warehouse using Visual Studio and then we will query and create a new table.
Requirements
- An Azure Subscription.
- An Azure SQL Server and an Azure Data Warehouse already created (if you do not know how to create a Data Warehouse, go to our article "Azure Machine Learning - Your first experiment" and go to the Creating an Azure SQL Data Warehouse close to the getting started section.
- Visual Studio 2013 or later. In this example, we are using VS2015.
Get Started
In the Azure Portal, go to SQL servers:
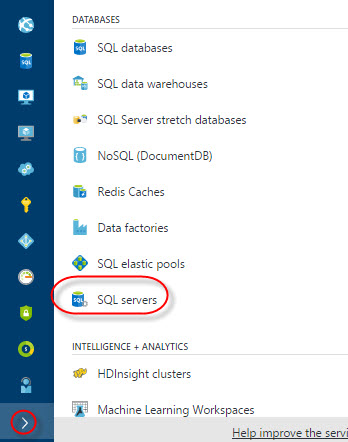
Click on the SQL server where you have your Warehouse (see the requirements). In this example, we will click sqlcentralserver1:
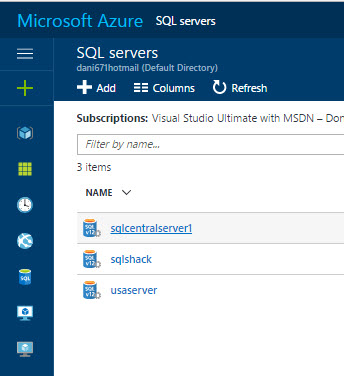
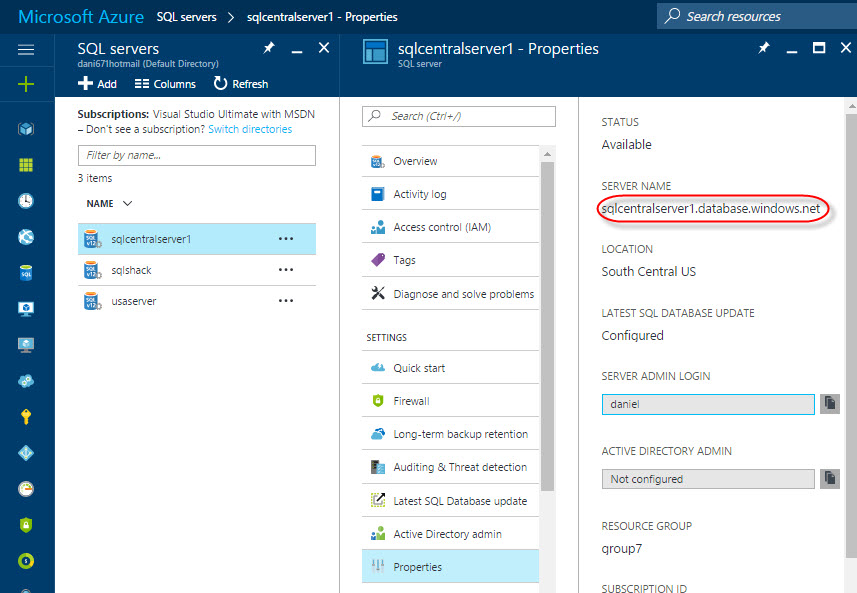
Click properties and copy and paste the server name. This name will be used to create the connection from Visual Studio:
Open Visual Studio and go to View>SQL Server Object Explorer to connect to our Data Warehouse in Azure:
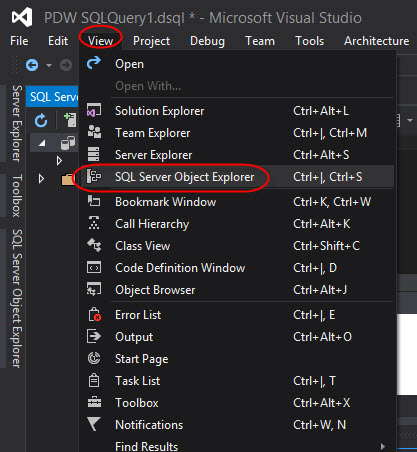
Click the Server icon and in the Window displayed, specify the Server Name (that we copied from the Azure Portal), the user name, password and database name (these values were created in our previous article mentioned in our requirements):
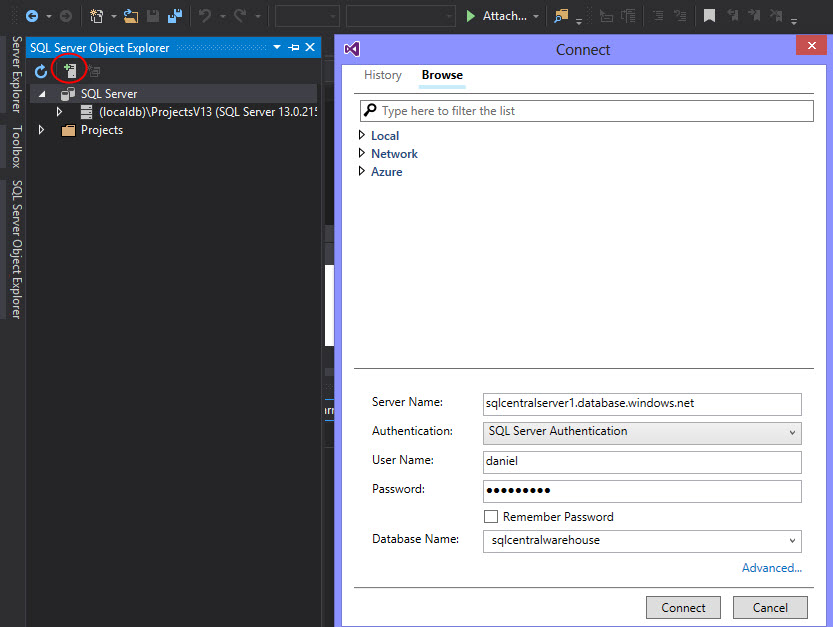
If you did not create a firewall rule, you will add your IP as a new rule in Azure:
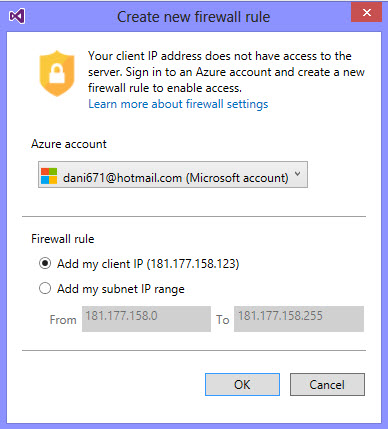
The Azure Data Warehouse created contains the adventure works sample tables. It is a very useful sample database to learn and it is easier to test the features because it already contains data:
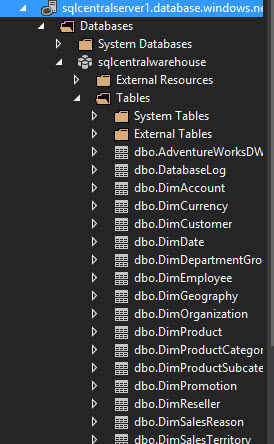
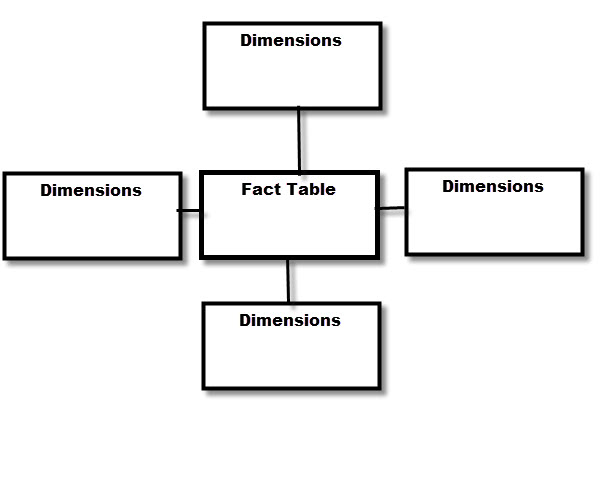
In the sample database, you have dimensions and fact tables. The dimensions have the dim prefix and the fact tables have the fact prefix:
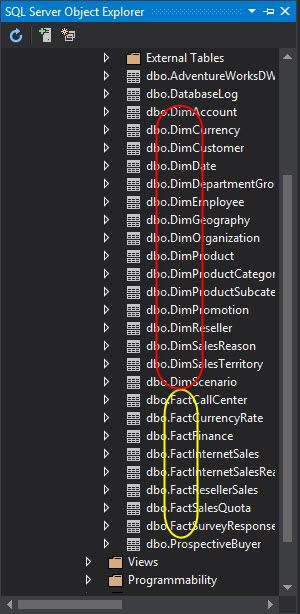
The fact tables contains the values that we want to measure in a company. For example, the sales, number of items sold, the total income, income per year, etc. The dimensions help us to get more details about the fact information. For example, with the dimension geography, we can query the sales of the fact table per country or per city. Another example is the time dimension. We can query the sales of the fact table per year, per month, per day, etc.
The fact table can have several dimensions and they are related using common columns:
Let's take a look to the data. In Visual Studio, right click the Data Warehouse created and select the New Query option:
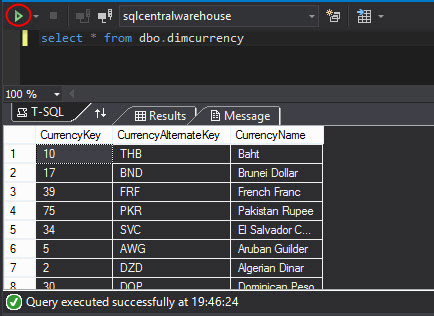
We will run a select in the dbo.dimcurrency view to check the information:
As you can see, it is very simple to query a Data Warehouse. You only need to know T-SQL. You can optionally save the results of the query in a file or save the results as text:
Now let's query the dbo.factInternetSales:
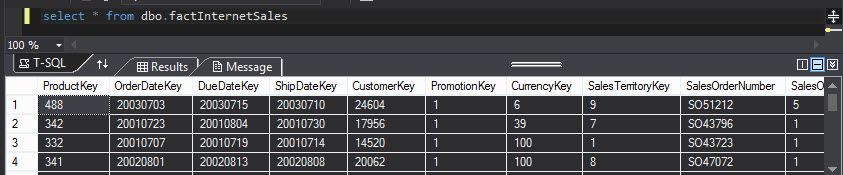
As you can see, the fact table is composed of keys to relate to the dimensions. For example, ProductKey will related the fact table with the product dimension and customerkey with the customer dimension.
Finally, we will create a new table:
CREATE TABLE FactSales (
id bigint,
altid bigint,
geographyid bigint,
timeid bigint,
quantity decimal(15,2),
price decimal(15,2),
discount decimal(15,2),
tax decimal(15,2)
)
WITH
(
DISTRIBUTION = HASH (id),
CLUSTERED COLUMNSTORE INDEX,
PARTITION ( id RANGE LEFT FOR VALUES (10, 20, 30, 40 ))
); You could create a simple table, but we wanted to teach you 3 typical options:
- Distribution
- Columnstore
- Partition
These 3 options are used in big tables. The fact tables can have Gigabytes or Terabytes of data. As we explained in our common questions about Data Warehouses article, the Azure Data Warehouse was designed to run with Massive Parallel Processing. Queries that usually take too long to execute in other environments can be executed in less time in Azure Data Warehouse.
Distribution
There are two types of distribution:
- Round Robin
- Hash Distributed
Use Round Robin (set by default) if there is no obvious joining key or if it is a temporary table and use Hash Distributed if you have a joining key.
ColumnStore
In a Data Warehouse, it is a best practice to use columnstore indexes to reduce the execution time. Usually, when you have more than 10 million of rows, you will notice a better performance with this feature. ColumnStore store the information by column instead of doing by row, which is the storage by default.
For more information about ColumnStore, refer to our Stairway to ColumnStore Index Series.
Partitioning
Partitioning can help a lot to load data and it can improve the query performance. However, you must be careful because an excessive number of partitions can decrease the performance. Try to have 10-100 partitions. A higher number can be counterproductive.
Once created the table, you can refresh the SQL Server Object Explorer and verify that the new table dbo.FactSales was created successfully:
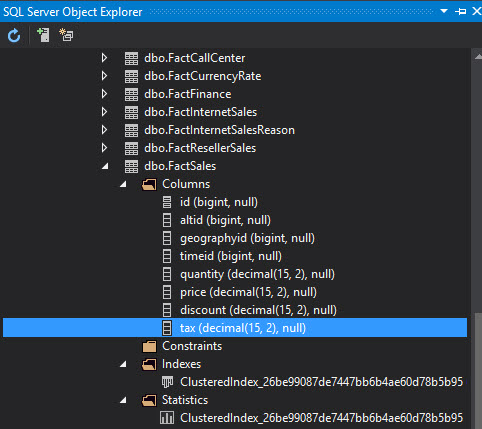
As you can see, it is not hard to create Data Warehouse tables in Azure.
Conclusions
In this article, we learned how to connect to our Azure SQL Data Warehouse using Visual Studio. We learned that we need to enable a rule for our local IP to access to the Data Warehouse Database. We created queries and learned basic concepts about Fact and Dimensions. We also learned that it is easy to create Data Warehouse tables. We just need to understand partitions, ColumnStore Indexes and Distributions.
References
For more information, refer to these links: