

Sometimes the schema of a replicated table needs altering. There are many reasons this might be the case eg possibly the datatype has been incorrectly chosen, or a default is missing, or we want to rename a column. Attempting to change the table schema directly will result in the error
"Cannot alter/drop the table 'tablename' because it is being published for replication".
So, how to change an existing column without breaking replication? Consider if we wanted to make the following schema change:
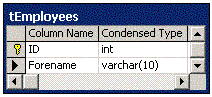 to
to 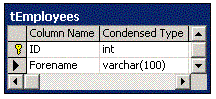
The method we choose depends in part on the replication type and size of the table, but there are 2 main options:
(a) altering the subscriptions
exec sp_dropsubscription @publication = 'tTestFNames'
, @article = 'tEmployees'
, @subscriber = 'RSCOMPUTER'
, @destination_db = 'testrep'
exec sp_droparticle @publication = 'tTestFNames'
, @article = 'tEmployees'
alter table tEmployees alter column Forename varchar(100) null
exec sp_addarticle @publication = 'tTestFNames'
, @article = 'tEmployees'
, @source_table = 'tEmployees'
exec sp_addsubscription @publication = 'tTestFNames'
, @article = 'tEmployees'
, @subscriber = 'RSCOMPUTER'
, @destination_db = 'testrep'
For snapshot replication this is the obvious choice. We drop the subscription to this article,
drop the article, then change the table. Afterwards the process is reversed. The next time the snapshot
agent is run, it'll pick up the new schema without any issues.
For transactional replication we may choose to proceed using the script above. However, we must be more
careful in this case. By default, an insert, update or delete statement performed on the publisher is propagated
to the subscriber in the form of a stored procedure call. By changing the column definition, we may need to change
the related stored procedures on all the subscribers. Addition of a default would be fine, but changing the datatype
itself as above would require the stored procedure arguments to be modified. For the example table above, these 3 procedures
exist on the subscriber in the form:
sp_MSins_tEmployees,
sp_MSupd_tEmployees,
sp_MSdel_tEmployees.
They can be generated at the publisher using sp_scriptpublicationcustomprocs but this would of course require the system to be quiesced, i.e. during this (quick) change there shouldn't be any alterations made to the publisher's data and all the subscribers should be completely synchronized.
This is not ideal, and there is also a hidden problem here waiting to be discovered. Usually, when you add a new article to an existing publication in transactional replication, running the snapshot agent will create a snapshot of just the new article. In our case, it'll also create a snapshot of the 'tEmployees' table. So, to avoid all the issues and complications mentioned above,
it's simplest to run the snapshot agent immediately after executing sp_addsubscription and then synchronize.
In merge replication, there is no possibility of dropping the subscription on a per article basis using the script above, as there is in transactional and snapshot replication.
If we drop the subscription entirely including all other articles (sp_dropmergesubscription),
then try to run sp_dropmergearticle there will be an error if the snapshot has
already been run, so we have to set @forceinvalid_snapshot to 1, make the table change on the publisher then read the
article and subscriptions and initialize which would necessitate a new snapshot generation of
all articles in this publication. A nosync initialization is possible,
but this can be extremely restrictive for future changes, and I'll leave that
for another article.
(b) altering the table in-place
OK, in some cases the table is large and we don't want to run a new snapshot - either of the individual table (transactional) or of the whole publication (merge) - so there is an alternative method. We might use the built in stored procedures sp_repladdcolumn and sp_repldropcolumn to make the changes (note that these procedures limit the subscribers to be SQL Server 2000 only). Using these procedures we can add a dummy column to hold the data, remove the old column, add in the correct definition of the original column
then transfer back the data. Now the script becomes:
exec sp_repladdcolumn @source_object = 'tEmployees'
, @column = 'TempForename'
, @typetext = 'varchar(100) NULL'
, @publication_to_add = 'tTestFNames'
update tEmployees set TempForename = Forename
exec sp_repldropcolumn @source_object = 'tEmployees'
, @column = 'Forename'
exec sp_repladdcolumn @source_object = 'tEmployees'
, @column = 'Forename'
, @typetext = 'varchar(100) NULL'
, @publication_to_add = 'tTestFNames'
update tEmployees set Forename = TempForename
exec sp_repldropcolumn @source_object = 'tEmployees'
, @column = 'TempForename'
Although the above script can be used for transactional replication or merge replication, the internal methodology is different due to
the differing nature of these 2 techniques. For merge replication, details of the rows updated are kept in MSmerge_contents,
and if a particular row has been changed once or a hundred times, there will still only be one entry in this system table, while in
transactional replication, 100 updates to a row is propagated as 100 subscriber updates. This means merge has an advantage over
transactional because we need to perform 2 updates to each row to make the schema change.
Paul Ibison, SQL Server MVP, 2005, http://ssisblog.replicationanswers.com/
