

When SQL CLR functions were added to SQL Server 2005 my interest was piqued by the possibility of introducing new aggregate functions. I quickly realised that most of the aggregate activity I wanted to do was better handled by T-SQL and/or extremely dangerous within a CLR function. For example, if we wanted to use an aggregate to work out the median (middle value) from a set you could write a CLR aggregate however on a large data set you would run the risk of consuming a huge amount of memory.
Judging by the examples (the lack of) on the Internet it seems that most people reached the same conclusion. In fact most examples seem entirely academic exercises or face the same problem as my Median example. The CLR aggregate examples I have seen are:
- Concatenate strings (lots of plagiarism for this one)
- A baker's dozen example (when would I ever use it?)
- A weighted average calculation (interesting, but of limited use)
Characteristics of a good candidate for a CLR Aggregate
An aggregate operates over a set of data, which could be zero rows to whatever the limit is for rows in a SQL Server table. Potentially the aggregate could be performing a huge volume of work therefore poor candidates for aggregate have the following characteristics:
- Require a substantial portion of the set to be held in memory (median and mode calculations)
- Require string manipulation
- Require the instantiation of many objects
- Produce output that is of little use in the real world
A good candidate would be one that does something simple like COUNT, SUM, AVG, STDEV, STDEVP, VAR, VARP, RANK, NTILE etc but as these functions already exist in T-SQL I couldn't think of a genuinely useful, safe to run aggregate, so I put CLR aggregates to the back of my mind. Academically interesting but not useful in the real world.
A game changer for aggregates, SQL2008
All this changed when SQL2008 introduced the ability for an aggregate to take more than one argument. In the world of statistics there are a number of functions that take a set of pairs of data and calculate a figure to say how closely related they are.
For example if you look at trend lines in Microsoft Excel you have the ability to look at the formula of the trend line and also the R2 value revealing how a good a fit that trend line is. If we look at the formulae used for linear regression we can see that it meets all the criteria for being a good candidate for a CLR aggregate
- Only requires a few primitive variables to be maintained
- Does not instantiate many objects
- Does not involve string manipulation
- Produces genuinely useful output
- Offers a "better" solution that T-SQL for these reasons:
- May be a T-SQL implementation is not possible
- May be a T-SQL implementation is more complex
- May be a T-SQL implementation is less efficient.
Linear Regression
The formula for a straight line is y = mx+c
- m = the slope of the graph
- c = a constant
R2 is a figure that indicates how close the calculated trend line is to the real data.
Linear regression allows us to calculate the slope and goodness of fit of a trend line for a set of data.
The formulae below show the mathematical representation and the T-SQL equivalent.
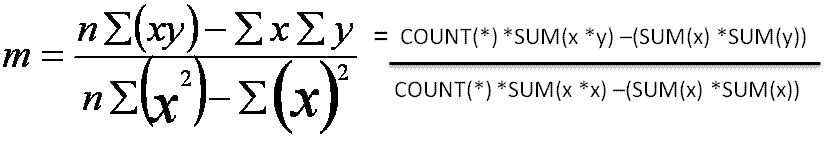
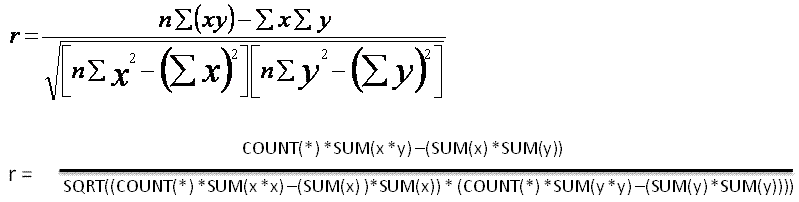
First steps
My first step was to create a very simple test table in the Adventureworks database and populate it with some dummy values.
CREATE TABLE dbo.test_table(
col1 FLOAT NOT NULL ,
col2 FLOAT NOT NULL
)
GO
INSERT INTO dbo.test_table
SELECT TOP 30000 ROW_NUMBER() OVER(ORDER BY s1.id DESC),ROW_NUMBER() OVER(ORDER BY s1.id ASC)
FROM sysobjects,sysobjects s1
I deliberately limited the test values to 30,000 because I wanted to test my CLR aggregate and T-SQL equivalents against the Microsoft Excel equivalent trend lines.
The Excel chart appears as shown below.
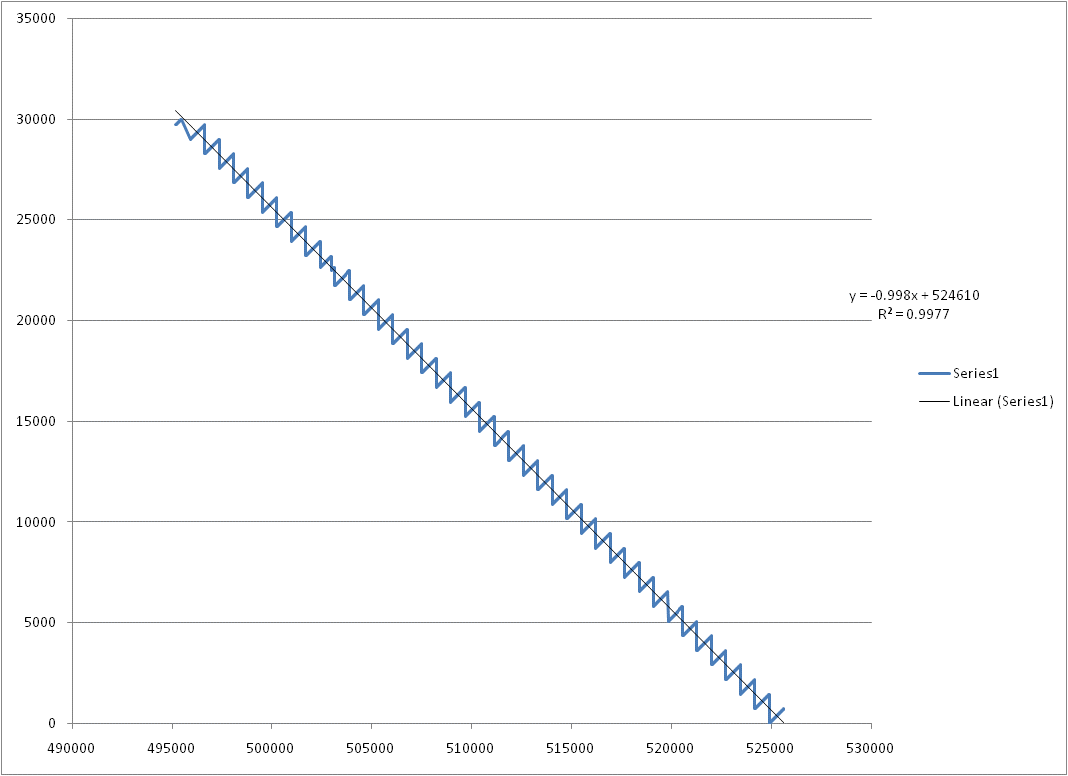
The T-SQL solution
The next stage was to write a traditional query which, if correct, should give me exactly the same values as the Excel equivalent.
DECLARE
@x FLOAT,
@y FLOAT,
@xy FLOAT,
@x2 FLOAT,
@n FLOAT
SELECT
@n = COUNT(*),
@x = SUM(col1),
@y = SUM(col2),
@xy = SUM(col1 * col2),
@x2 = SUM(col1*col1)
FROM dbo.test_table
SELECT ((@n * @xy) - (@x*@y)) / (@n * @x2 - (@x*@x))
This produced exactly the same value as the Excel equivalent but I was curious to see if amalgamating the two selects into a single formula would make any difference to the execution plans.
SELECT ( COUNT(*) * SUM(col1*col2) - ( SUM(col1) * SUM(col2)))/( COUNT(*)* SUM(col1*col1)-( SUM(col1)* SUM(col1))) FROM dbo.test_table
I also tested both queries with SET STATISTICS TIME ON
These both produced identical execution plans. However over several runs the CPU time for the former query was marginally lower than the latter. Realistically the difference ranged from 0 to 16ms.
Beginning my first CLR Aggregate
My first port of call was to do some basic background research and the principal articles I found were as follows
http://www.mssqltips.com/tip.asp?tip=2022
http://blog.effiproz.com/2010/06/multi-parameter-clr-user-defined.html
A basic CLR aggregate has four methods
| Method | Purpose |
|---|---|
| Init | This is called when the aggregate is first fired up. It is a bit like a constructor. |
| Accumulate | As the name suggests this is where the data for the aggregate accumulates up. In my case I was counting valid entries, summing up the arguments, squares of arguments and multiples of arguments |
| Merge | If SQL Server decides to parallelise the query using the aggregate this method is what brings the different streams back together again. |
| Terminate | This is where the aggregate actually returns its data and ends. |
The basic aggregate also has four attributes which are described in Andy Novak's article.
| Attribute | Comment |
|---|---|
| Format | This is a compulsory enum with options Native, Unknown and UserDefined. In my case I used Native |
| IsInvariantToNulls | Setting this to true tells the aggregate that it doesn't care whether or not values are null or not, it will always produce the same result. An example of an aggregate where the value for this is false is COUNT(field) which only counts instances that are NOT NULL |
| IsInvariantToDuplicates | Setting this to true tells the aggregate that it will produce the same results even if there are duplicate entries. MAX() is a good example of this as no matter how many duplicates there are the MAX value will still be the MAX value. |
| IsInvariantToOrder | Setting this to true affects how SQL Server calls the Merge method of the aggregate. If you had a string concatenation aggregate that was parallelised then it is vitally important that the streams merge back together in the correct order. |
As well as affecting the way that the aggregate behaves these attribute values will also affect the performance of the aggregate.
So with a bit of basic knowledge I fired up Visual C# 2008, created a database project called Regression and began.
The aggregate header
When you first add an aggregate to a Visual Studio solution you get the C# equivalent of include files
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
[Serializable]
[SqlUserDefinedAggregate(
Format.Native, //use clr serialization to serialize the intermediate result
IsInvariantToNulls = false, //optimizer property
IsInvariantToDuplicates = false, //optimizer property
IsInvariantToOrder = true //optimizer property
)]
public struct Slope
{
private long count;
private SqlDouble SumY;
private SqlDouble SumXY;
private SqlDouble SumX2;
private SqlDouble SumY2;
private SqlDouble SumX;
As you can see I have used a struct and my aggregate is called "Slope" but it doesn't really matter if you use structs or classes.
The private variables are simply those that I am going to use within my aggregate. Notice that I am explicitly using the CLR Sql types.
The Init method
The init function is the simplest part of the aggregate. All I do is set my private member variables to zero.
public void Init()
{
count = 0;
SumX = SumY = SumXY = SumX2 = SumY2 = 0;
}
The Accumulate method
This is the engine room for my aggregate. All I am doing here is counting the iterations, summing x, y and their squares and their multiple.
public void Accumulate(SqlDouble x, SqlDouble y )
{
if (!x.IsNull && !y.IsNull){
count++;
SumX += (SqlDouble)x;
SumY += (SqlDouble)y;
SumXY += (SqlDouble)x * (SqlDouble)y;
SumX2 += (SqlDouble)x * (SqlDouble)x;
SumY2 += (SqlDouble)y * (SqlDouble)y;
}
}
The Merge method
public void Merge(Slope other){ count += other.count; SumY += other.SumY; SumXY += other.SumXY; SumX2 += other.SumX2; SumY2 += other.SumY2; SumX += other.SumX; }
As stated earlier the Merge method is simply to bring the different streams together when SQL Server decides to parallelise the query. If you get this method wrong and the query parallelises you will get strange results.
If SQL server does parallise a query with a CLR aggregate it is worth testing to see if the query produces the same results when MAXDOP=1. If it doesn't then you have probably got something wrong.
The Terminate Method
Finally the terminate method takes your accumulated data and returns a value back to SQL Server.
public SqlDouble Terminate(){ if (count > 0) { SqlDouble value = (count * SumXY - (SumX * SumY)) / ((count * SumX2) - (SumX * SumX)); return value; } else { return 0; } }
At this point I should like to offer a big thank you to Bob Beauchemin, the MVP who helped me to get the aggregate up and running.
I also set up a 2nd struct called RSquared that was identical apart from the Terminate function which was as follows
public SqlDouble Terminate()
{
if (count > 0)
{
SqlDouble value = (count * SumXY - (SumX * SumY)) / Math.Sqrt((double)((count * SumX2) - (SumX * SumX)) * (double)((count * SumY2) - (SumY * SumY)));
return value*value;
}
else
{
return 0;
}
Deploying the Aggregate
Visual Studio 2008 will happily compile a multi-parameter CLR aggregate but it won't deploy it. If you try it then you will get a message warning that a user defined aggregate should have only one parameter.
To deploy the aggregate you need to use SQL Server Management Studio. My deployment script is as shown below.
USE AdventureWorks2008
GO
IF EXISTS(SELECT * FROM INFORMATION_SCHEMA.ROUTINES 'LINEARREGRESSION')
BEGIN
DROP ASSEMBLY LINEARREGRESSION
END
GO
CREATE ASSEMBLY LinearRegression FROM 'C:\Documents and Settings\David\My Documents\Visual Studio 2008\Projects\Regression\Regression\bin\Debug\Regression.dll'
GO
CREATE AGGREGATE Slope(@x FLOAT, @y FLOAT)
RETURNS FLOAT
EXTERNAL NAME LinearRegression.Slope;
Testing the CLR Aggregate
To run my aggregate I simply executed the query below
SELECT dbo.Slope(col1,col2) FROM dbo.test_table GO
This produced exactly the same results as for my T-SQL Equivalent
My next step was to compare the execution plans.
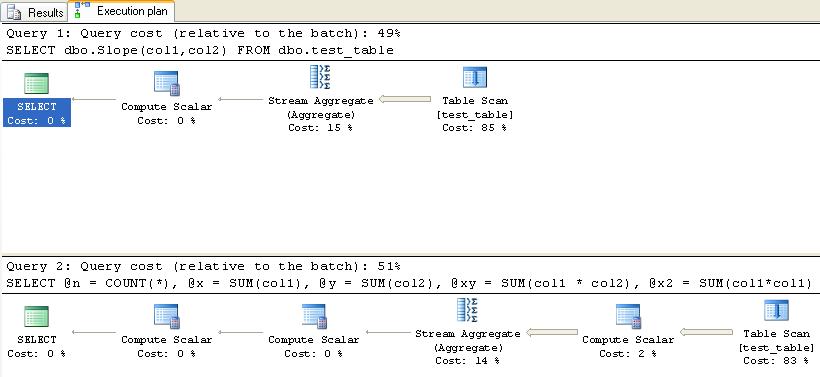
As you can see the CLR function has a marginally better execution plan. This difference was maintained when the number of test records was increased to 500,000
| Query type | 30,000 records | 500,000 records |
|---|---|---|
| CLR | 0.122431 | 2.10203 |
| T-SQL | 0.125431 | 2.15459 |
However looking at the CPU time the results are considerably less encouraging. I found that the aggregate consistently required more CPU time and this got worse as the sample size got larger.
| Query type | 30,000 records | 500,000 records |
|---|---|---|
| CLR | 62 | 1,400 |
| T-SQL | 47 | 767 |
My next test was to add a field to my table by which I could do some grouping. I simply called my field GroupingColumn and populated it with CAST(Col1 AS DECIMAL(18,5))%10
The results from this provided a shock.
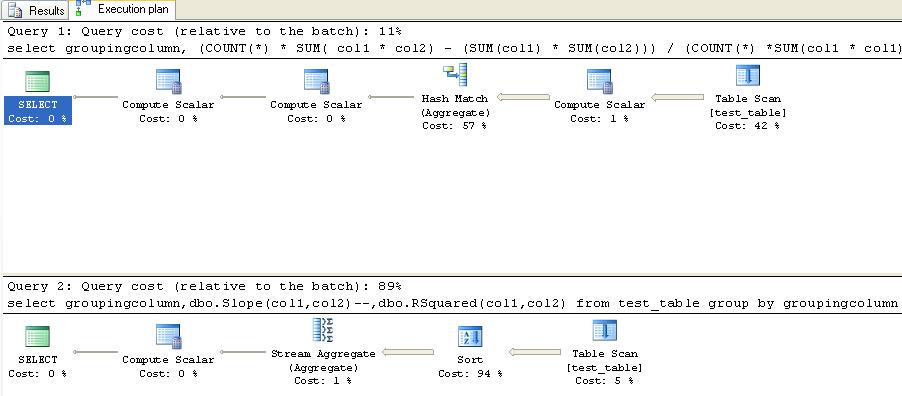
For whatever reason my CLR Aggregate has decided to throw a SORT into the mix which accounts for 94% of the query cost. Without that sort the CLR function would have been substantially cheaper than the T-SQL equivalent. Even if an ORDER BY is added to the T-SQL result there is a slight change to the execution plan however the ordering is done after the aggregation where as the CLR aggregate performs its work before the aggregation!
At first I thought it might be something to do with the IsInvariantToOrder setting however rebuilding and re-creating the aggregate didn't make any difference.
Playing with indexes
The first thing I tried after seeing the sort was to create an index on my grouping column.
IF EXISTS(SELECT * FROM sys.indexes OBJECT_ID(N'dbo.test_table') AND name = N'idx_test_table_groupingcolumn')
DROP INDEX idx_test_table_groupingcolumn ON dbo.test_table
GO
CREATE CLUSTERED INDEX idx_test_table_groupingcolumn ON dbo.test_table (Groupingcolumn)
GO
This suceeded in reverting the execution plan back to the original 49:51 CLR:T-SQL proportions. However I may want to correlate figures grouped by a number of different columns either singly or in combinations so a single clustered index per table is not going to get me very far.
Conclusions
There is a distinct absence of good CLR Aggregate examples on the web and not a massive amount of reference material to help a beginner. It is quite possible that I have missed something fundamental that would eliminate the CLR sort from the aggregate.
At the heart of it my linear regression example is possible to write to execute efficiently using T-SQL. The T-SQL may appear convoluted but at its heart it is really doing something fairly simple.
There is clearly a significant overhead in using CLR aggregates but in the real world linear regression functions fall more into the data warehousing space than OLTP. In my particular case the penalty is (just) bearable because the aggregate is not something that will be run many times a second. I would be nervous about running the CLR aggregate against a multi-million row dataset.
To be capable of running the aggregate safely you would need a sizable TEMPDB on fast disks however I would regard this as a pre-requisite for a DB server supporting analytics functions.
What the CLR aggregate does offer is simplicity to the data analyst who is at heart a statistician who is perfectly capable of writing complex T-SQL but frankly more interested in what the data tells them than in the mechanics of retrieving it.
Such a person is more likely to use a statistics tool to retrieve huge volumes of data and then grind it all up in their favourite stats package. This being the case providing them with some simple CLR aggregates to carry out core stats functions may still have less impact than retrieving huge volumes of data.
