

SQL Server 2017 has introduced several changes to the way that query plans work in SQL Server. This article is the third in a series that will cover these changes. The other articles in the series are:
- Automatic Plan Correction
- Adaptive Query Processing – Batch Mode Memory Grant Feedback
- Adaptive Query Processing – Batch Mode Adaptive Join (this article)
- Adaptive Query Processing – Interleaved Execution
Adaptive Query Processing
Adaptive Query Processing deals with means to improve query performance. Introduced in SQL Server 2017, Adaptive Query Processing currently includes these features:
- Batch Mode Memory Grant Feedback
- Batch Mode Adaptive Join
- Interleaved Execution
Generally speaking, query optimization generates a set of query plans, during which various plan options are considered and the plan with the lowest cost is used, and then the query runs the plan generated by the optimization process. Sometimes, the generated plan just isn’t an optimal plan for the query being run. At times a different number of rows being returned can drastically change the best plan for a query.
The Ideal Query Plan Join Operator
When a query joins data between two tables, a join operator is used. Which operator that is used depends upon the number of rows involved. If the input has a small amount of rows, a nested loop join operator would be a better choice than a hash join. However, if the input has more rows than a threshold, then the optimal join operator would be a hash join.
The query plan that gets put into the plan cache will have the join operator for the first query that is run. If a subsequent query comes along with a different parameter that would have a different optimal join operator, well, that’s just too bad. You’re going to be stuck using the one in the plan cache.
Your choices are pretty simple. Either force the query to create a query plan each time it is run, or use a query hint to force a specific join type that is the most suitable for your workload. If you do this, then your system ends up taking the performance hit for those parameters that end up using a less-than-optimal query plan.
Wouldn’t it be great if SQL Server would just pick the appropriate join operator at run time?
Batch Mode Adaptive Join
SQL Server 2017 introduces the Batch Mode Adaptive Join operator. And it does just that – it defers the choice of whether to use a hash join or a nested loop join under after the first input has been scanned, and it knows how many rows that it is dealing with. It then decides whether to use a hash join or a nested loop join operator.
As in the previous article on Batch Mode Memory Grant Feedback, the “Batch Mode” refers to processing the data in groups of rows, or in other words, it requires the query to utilize a ColumnStore index somewhere. Without a ColumnStore index, the query will run in Row Mode.
Seeing Batch Mode Adaptive Join in action
There’s not much else to say about the Adaptive Join operator, so it’s time to see it in action. For this demo, we will be using the WideWorldImportersDW database, available from Microsoft’s github for SQL Server samples. First, let’s set up the environment:
USE master; GO ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 140; GO ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE; GO USE WideWorldImportersDW; GO -- Inserting quantity row that doesn't exist in the table yet DELETE [Fact].[Order] WHERE Quantity = 361; INSERT [Fact].[Order] ([City Key], [Customer Key], [Stock Item Key], [Order Date Key], [Picked Date Key], [Salesperson Key], [Picker Key], [WWI Order ID], [WWI Backorder ID], Description, Package, Quantity, [Unit Price], [Tax Rate], [Total Excluding Tax], [Tax Amount], [Total Including Tax], [Lineage Key]) SELECT TOP 5 [City Key], [Customer Key], [Stock Item Key], [Order Date Key], [Picked Date Key], [Salesperson Key], [Picker Key], [WWI Order ID], [WWI Backorder ID], Description, Package, 361, [Unit Price], [Tax Rate], [Total Excluding Tax], [Tax Amount], [Total Including Tax], [Lineage Key] FROM [Fact].[Order];
Now we turn on Live Query Statistics, and then run this query:
-- Show live query stats
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;Which returns this query plan. I’ve highlighted a few areas that I’ll talk about next:
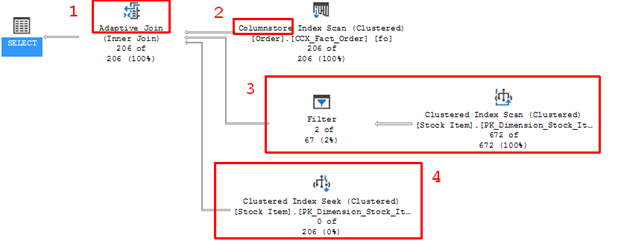
Item 1 shows the Adaptive Join operator. Item 2 shows that a ColumnStore index is being used. Item 3 shows the probe phase that a typical Hash join operation would use, and Item 4 shows the Clustered Index seek that would be used by a Nested Loop join operation. In this plan, it can be seen that the Hash join section has rows being processed, while the Nested Loop section does not (676 of 672 vs. 0 of 206). If we look at the Adaptive Join operator, we can see what type of join operator that it decided to use:
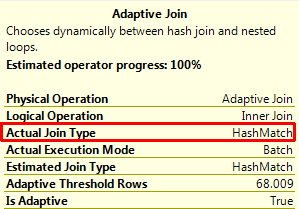
Let’s rerun this query with a different parameter:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;This produces a similar query plan:

Notice this time that the Nested Loop section was utilized instead of the Hash section. Looking at the adaptive join operator we can see that this time, it utilized a Nested Loop join operator:
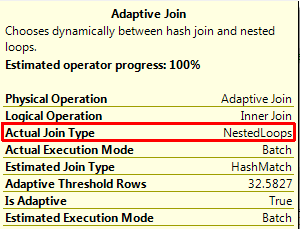
So there you go. The Batch Mode Adaptive Join changes the join operator at run time on parameter sensitive queries between using a nested loop or hash join operator, depending on the number of rows feeding into it. This lets you get away having to recompile the query every time it’s run to get the optimal plan, or forcing a specific join operator through a query hint.
Extended Events for Batch Mode Adaptive Join
If you want to monitor any of the new features being added to SQL Server, you have to use Extended Events (XE). For the Batch Mode Adaptive Join, one extended event was added: adaptive_join_skipped.

