

Introduction
By now, we all know the fact that indexes are one of the most powerful tools for speeding up database queries. However, designing the right index is actually an art.
In this article, we will learn on how to create a Python script to inspect slow queries and suggest us (or optionally create) optimized PostgreSQL indexes. We will analyze slow queries, propose index definitions using simple heuristics (EXPLAIN and ANALYZE), and create (or suggest) indexes that can be run in the actual environment without much risk.
Since this is just a learning exercise, we will keep it simple, practical, and safe.
Advantages of Automatic Index Suggestions
First, let us try to understand why we need and how we benefit from having a utility that helps suggest indexes. Normally, developers often add indexes on an ad-hoc basis. As a result, they leave behind redundant or ineffective indexes.
Assume that initially we decided to have a query to fetch some records. To make it optimize performance, we introduced various indexes that are based on the column combinations being used in the filtering conditions. Now, after code review, we decided to change the query and, accordingly, we created a few more indexes to help this new query. We are leaving behind the earlier indexes we created that may not be relevant anymore. With the evolution of our queries, indexes keep changing and should be monitored for updates or removal. In such a situation, having a tool that observes slow and frequent queries and suggests to us useful indexes, benefits us in avoiding guesswork and over-indexing.
We will slowly move on to create a simple tool that focuses on the WHERE clause, JOIN conditions, ORDER BY, and sometimes GROUP BY, since these are the main areas where indexes help us the most to improve query performance.
Inner Workings of the Tool
Let's shortly have a high level discussion on how the tool will work that we will be creating next.
- Collect candidate queries to analyze:
- Queries will be collected from pg_stat_statements (we recommend so), or
- From a log file of slow queries
- For each query collected:
- Run EXPLAIN (ANALYZE, BUFFERS) to. see if sequential scans are used or if the cost is high,
- Parse such queries to extract the columns used in WHERE, JOIN or ORDER BY clauses,
- Generate one or more index suggestion(s) (single column, multi column or similar)
- Optionally:
- Create the index CONCURRENTLY
- Re-run the EXPLAIN (ANALYZE) and report the improvement achieved
- Finally, output a human readable report and SQL snippets.
Python Code Snippet
A few requirements to get started:
- Python version 3.8+
- pip install psycopg2-binary sqlparse
Before we start with the python script provided below, let us also understand in brief what the code snippet does. Once you understand it, you can copy it to a file and save it with any name of your choice with extension as .py. We will name our file as auto_indexer.py.
Here is the flow for the tool:
- Import statements provided that would be needed for the tool functionality:
- subprocess - runs psql commands
- csv - parses csv returned by psql --csv commands
- argparse - CLI arguments
- re - regex for parsing SQL
- typing - type hints
- DB_CFG - configures the parameters needed to connect to the local database
- def psql_conn_str(cfg): - Creates the postgreSQL connection string
- def run_psql_sql(sql_text, cfg, csv_mode=False) - runs the SQL query using the psql -c command.
- def queries_from_pg_statstatements(...) - get queries from the pg_stat_statements:
- Runs SELECT query, calls, total_time FROM pg_stat_statements using CSV mode
- Filters out BEGIN, vacuum, BEGIN queries
- Sort by total_time DESC
- Returns list of (query_text, calls, total_time).
- def queries_from_file(path) - Read queries from the file:
- Tries sqlParse.split() for correct SQL splitting
- Falls back to simple ; operator
- Returns (query, 1, 0.0) for each query
- def run_explain_via_psql(query, cfg) - Runs EXPLAIN via psql:
- Wraps query inside EXPLAIN(ANALYZE, BUFFERS)
- Use psql to execute EXPLAIN
- Returns raw text plan as string
- def extract_columns_from_where_and_joins(query) - Extract Columns (WHERE/JOIN/ORDER BY):
- Looks into WHERE, JOIN ON, ORDER BY clauses
- Extracts tokens like table.col or "col"
- Strips table prefixes and returns distinct list of column names
- def suggest_indexes(query, cols) - Suggest Indexes:
- Single column indexes - for each detected column
- Multi-column indexes - using first row columns
- Each suggestion includes - index name, type (single/multiple), columns, SQL string, reason.
- def detect_primary_table(query) - detect the primary table
- Searches for: FROM table, INTO table, UPDATE table
- Extracts the table name removing the schema, if present
- def analyze_and_propose(query, apply_indexes=False, dry_run=True) - Analyze query and propose indexes:
- Prints the query
- Runs the EXPLAIN before index creation
- Extract the columns and builds index suggestions
- Replace table placeholder in SQL
- Prints the suggested indexes
- Optionally apply indexes using psql
- Optionally show EXPLAIN after indexes are created
Finally, comes the CLI main function
import os
import re
import csv
import shlex
import time
import argparse
import subprocess
from typing import List, Tuple
# ---------------------------
# Database / psql configuration
# ---------------------------
DB_CFG = {
"host": "localhost",
"port": 5432,
"dbname": "localdb",
"user": "sabyasachimukherjee",
"password": "",
}
def psql_conn_str(cfg: dict) -> str:
"""Return a libpq connection string for use with psql -c."""
parts = []
for k in ("host", "port", "dbname", "user"):
v = cfg.get(k)
if v:
parts.append(f"{k}={v}")
return " ".join(parts)
def run_psql_sql(sql_text: str, cfg: dict, csv_mode: bool = False, timeout: int = 30) -> str:
"""
Run a SQL statement via psql and return stdout. If csv_mode=True, use --csv.
"""
conn = psql_conn_str(cfg)
cmd = ["psql", "--no-align", "--pset", "format=unaligned"]
if csv_mode:
cmd = ["psql", "--csv"]
cmd += ["-c", sql_text, conn]
env = os.environ.copy()
if cfg.get("password"):
env["PGPASSWORD"] = cfg["password"]
proc = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE,
env=env, text=True, timeout=timeout)
if proc.returncode != 0:
raise RuntimeError(f"psql failed: {proc.stderr.strip()}")
return proc.stdout
# -------------------------------------------------------------------
# AUTO-DETECT pg_stat_statements column names for all PG versions
# -------------------------------------------------------------------
def detect_pgstat_columns() -> dict:
"""
Detect correct column names for pg_stat_statements
depending on PostgreSQL version.
Works for PG 10–16+.
"""
q = """
SELECT column_name
FROM information_schema.columns
WHERE table_name = 'pg_stat_statements';
"""
out = run_psql_sql(q, DB_CFG, csv_mode=True)
rows = list(csv.DictReader(out.splitlines()))
cols = {r["column_name"] for r in rows}
mapping = {}
# Calls always exists
mapping["calls"] = "calls"
# total execution time changed in PG 13+
if "total_exec_time" in cols:
mapping["total"] = "total_exec_time"
mapping["mean"] = "mean_exec_time"
else:
mapping["total"] = "total_time"
mapping["mean"] = "mean_time"
# query column also changed (query vs queryid sometimes)
if "query" in cols:
mapping["query"] = "query"
elif "queryid" in cols:
mapping["query"] = "queryid"
else:
mapping["query"] = "query"
return mapping
# ---------------------------
# Query collection
# ---------------------------
def queries_from_pg_statstatements(limit: int = 20) -> List[Tuple[str, int, float]]:
cols = detect_pgstat_columns()
q = f"""
SELECT
{cols['query']} AS query,
{cols['calls']}::bigint AS calls,
{cols['total']}::double precision AS total_time
FROM pg_stat_statements
WHERE query NOT ILIKE 'EXPLAIN %'
AND query NOT ILIKE 'vacuum%'
AND query NOT ILIKE 'BEGIN%'
ORDER BY {cols['total']} DESC
LIMIT {int(limit)};
"""
out = run_psql_sql(q, DB_CFG, csv_mode=True)
rows = []
reader = csv.DictReader(out.splitlines())
for r in reader:
rows.append((r["query"], int(r["calls"]), float(r["total_time"])))
return rows
def queries_from_file(path: str, limit: int = 100) -> List[Tuple[str, int, float]]:
try:
import sqlparse
except Exception:
sqlparse = None
text = open(path, "r", encoding="utf-8").read()
if sqlparse:
statements = sqlparse.split(text)
else:
statements =
return [(s.strip(), 1, 0.0) for s in statements][:limit]
# ---------------------------
# EXPLAIN
# ---------------------------
def run_explain_via_psql(query: str, cfg: dict, timeout: int = 60) -> str:
wrapped = "EXPLAIN (ANALYZE, BUFFERS, FORMAT TEXT) " + query
return run_psql_sql(wrapped, cfg, csv_mode=False, timeout=timeout).strip()
# ---------------------------
# Column extraction
# ---------------------------
def extract_columns_from_where_and_joins(query: str) -> List[str]:
ql = query.lower()
candidates = set()
# WHERE extraction
for m in re.findall(r'\bwhere\b(.*?)(\bgroup|\border|\blimit|$)', ql, flags=re.S):
part = m[0]
for c in re.findall(r'([A-Za-z_][A-Za-z0-9_\."]*)\s*(=|>|<|>=|<=|like|\bin\b|\silike)', part):
col = c[0].split('.')[-1].replace('"', '')
candidates.add(col)
# JOIN extraction
for m in re.findall(r'\bon\b(.*?)(\bwhere\b|\bjoin\b|\bgroup\b|\border\b|\blimit|$)', ql, flags=re.S):
part = m[0]
for c in re.findall(r'([A-Za-z_][A-Za-z0-9_\."]*)\s*=', part):
col = c.split('.')[-1].replace('"', '')
candidates.add(col)
# ORDER BY
for m in re.findall(r'\border by\b(.*?)(\blimit\b|$)', ql, flags=re.S):
part = m[0]
for c in re.findall(r'([A-Za-z_][A-Za-z0-9_\."]*)', part):
col = c.split('.')[-1].replace('"', '')
candidates.add(col)
return list(candidates)
# ---------------------------
# Index suggestion
# ---------------------------
def sanitize(name: str) -> str:
return re.sub(r'\W+', '_', name)
def quote_ident(name: str) -> str:
if re.match(r'^[a-z_][a-z0-9_]*$', name):
return name
return '"' + name.replace('"', '""') + '"'
def suggest_indexes(query: str, cols: List[str] = None) -> List[dict]:
if cols is None:
cols = extract_columns_from_where_and_joins(query)
suggestions = []
# Single-column indexes
for c in cols:
idx = f"idx_auto_{sanitize(c)}"
sql_text = f"CREATE INDEX CONCURRENTLY IF NOT EXISTS {idx} ON <table> ({quote_ident(c)});"
suggestions.append({
"name": idx,
"type": "single",
"columns": [c],
"sql": sql_text,
"reason": f"{c} appears in WHERE/JOIN/ORDER BY"
})
# Multi-column index from first two
if len(cols) >= 2:
first_two = cols[:2]
idx = "idx_auto_" + "_".join(sanitize(x) for x in first_two)
sql_text = (
f"CREATE INDEX CONCURRENTLY IF NOT EXISTS {idx} ON <table> "
f"({', '.join(quote_ident(x) for x in first_two)});"
)
suggestions.append({
"name": idx,
"type": "multi",
"columns": first_two,
"sql": sql_text,
"reason": "multi-column index for combined filters"
})
return suggestions
def detect_primary_table(query: str) -> str:
for kw in ("from", "into", "update"):
m = re.search(rf'\b{kw}\s+([A-Za-z_][A-Za-z0-9_\."]*)', query, flags=re.I)
if m:
t = m.group(1)
if "." in t:
t = t.split(".")[-1]
return t.replace('"', '')
return None
# ---------------------------
# Analysis
# ---------------------------
def analyze_and_propose(query: str, apply_indexes: bool = False, dry_run: bool = True):
table = detect_primary_table(query) or "<table>"
print("=" * 72)
print("Query:")
print(query)
print("-" * 72)
try:
explain_text = run_explain_via_psql(query, DB_CFG)
print("EXPLAIN (before):")
print(explain_text)
except Exception as ex:
print("EXPLAIN failed:", ex)
explain_text = None
cols = extract_columns_from_where_and_joins(query)
print("Detected columns:", cols)
suggestions = suggest_indexes(query, cols)
# Replace table placeholder
for s in suggestions:
s["sql"] = s["sql"].replace("<table>", quote_ident(table))
print("\nIndex suggestions:")
for s in suggestions:
print("-", s["type"], s["columns"], "->", s["sql"])
print(" reason:", s["reason"])
if apply_indexes and not dry_run:
for s in suggestions:
print("Applying:", s["name"])
try:
run_psql_sql(s["sql"], DB_CFG)
print("OK:", s["name"])
except Exception as e:
print("Failed:", e)
if explain_text:
time.sleep(0.7)
print("\nEXPLAIN (after):")
print(run_explain_via_psql(query, DB_CFG))
# ---------------------------
# CLI
# ---------------------------
def main():
p = argparse.ArgumentParser(prog="auto-index-psql")
p.add_argument("--source", choices=["pgstat", "file"], default="pgstat")
p.add_argument("--file", help="SQL file if source=file")
p.add_argument("--limit", type=int, default=10)
p.add_argument("--apply", action="store_true")
p.add_argument("--dry-run", action="store_true", default=True)
args = p.parse_args()
# Check psql availability
try:
subprocess.run(["psql", "--version"], stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL, check=True)
except Exception:
print("psql not found on PATH.")
return
if args.source == "pgstat":
rows = queries_from_pg_statstatements(limit=args.limit)
else:
if not args.file:
print("Provide --file when source=file")
return
rows = queries_from_file(args.file, limit=args.limit)
for query, calls, total_time in rows:
analyze_and_propose(query, apply_indexes=args.apply, dry_run=args.dry_run)
if __name__ == "__main__":
main()
Pre-requisite for table creation, data insertion and tool execution
Let us create the tables and insert bulk data into it for the queries to actually take time in fetching data from the tables:
-- sample_data.sql
CREATE TABLE IF NOT EXISTS customers (
id SERIAL PRIMARY KEY,
name TEXT
);
CREATE TABLE IF NOT EXISTS orders (
id SERIAL PRIMARY KEY,
customer_id INTEGER REFERENCES customers(id),
status TEXT,
created_at TIMESTAMP WITHOUT TIME ZONE,
amount NUMERIC
);
-- populate small amounts for demo. For real testing populate millions.
INSERT INTO customers (name) SELECT 'Customer ' || g FROM generate_series(1,100) g;
INSERT INTO orders (customer_id, status, created_at, amount)
SELECT floor(random()*100)::int + 1,
(array['new','shipped','canceled','returned'])[ (random()*3 + 1)::int ],
getdate() - (random()*10000)::int * interval '1 second',
random()*1000
FROM generate_series(1, 50000);
Once the above script is run, it will insert 100 records into customers table and 50,00 records into the orders table.
Next, we will run the following query a coup,e of times in our PostgreSQL query tool (you can use PGAdmin here) to make sure that the query takes time and also the same comes up in pg_stat_statements when the tool is run.
SELECT TOP 50 id, customer_id, status, amount FROM orders WHERE customer_id = 42 AND status = 'shipped' ORDER BY created_at DESC
Next, we will now run the auto_indexer.py tool script to see if the index needed here is suggested to us. To run the same, run the following command from the terminal opened from the location where you saved the python script.
Once the script is run successfully, you should see the details of the query that was run along with the EXPLAIN of the query before and after the index creation as follows:
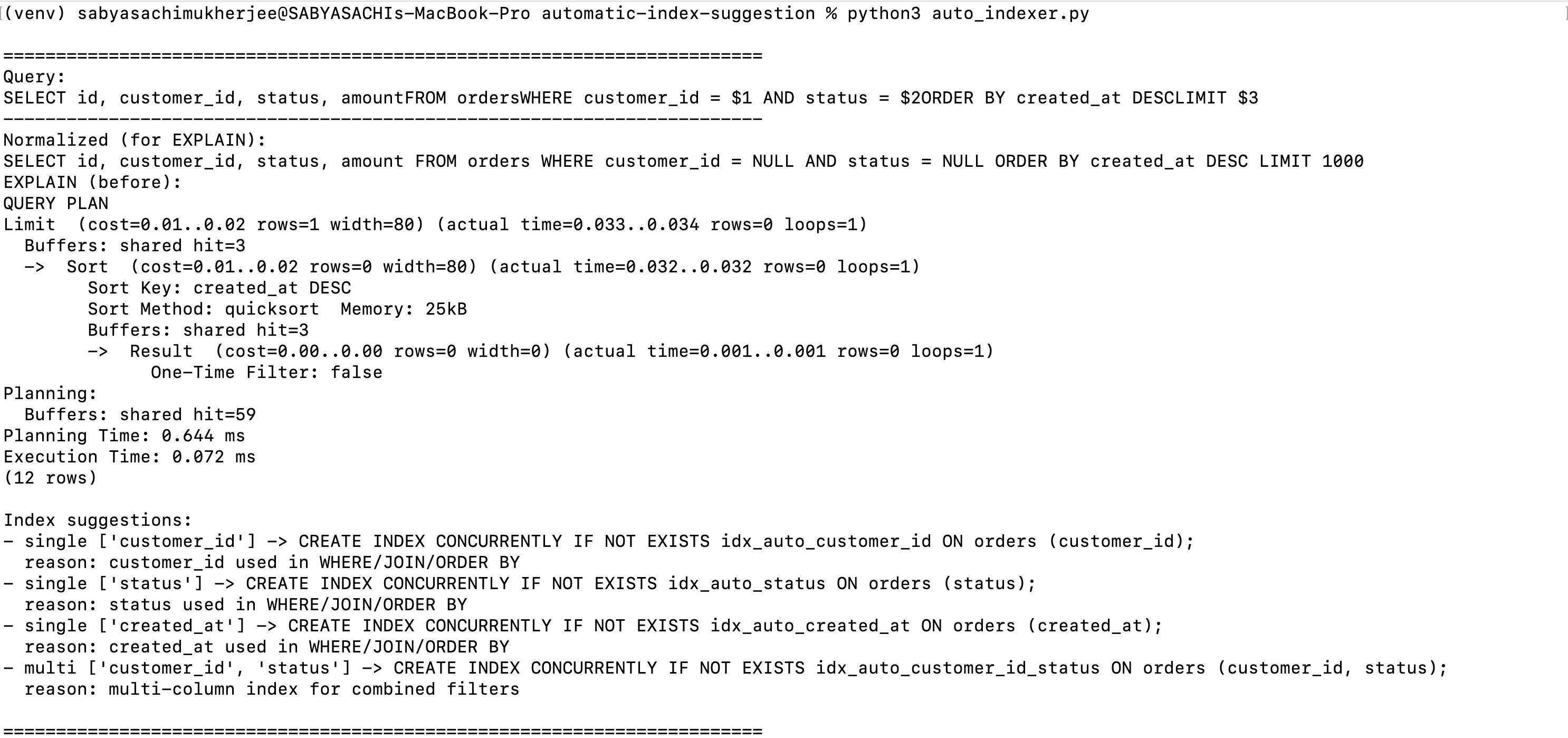
We can see the index suggestion against the query that was run and accordingly have the indexes created so that the query execution becomes faster and performance is improved in real time when the database will have real time data loaded to it.
Rules, Heuristics used, and Their Limitations
The basic index design rules used in our utility tool are:
- Single column index: helpful when that column is frequently used in equality filters or joins.
- Multi-column index: when queries filter on more than one column together; leftmost column(s) matter. If queries often filter by customer_id and then status, then (customer_id, status) helps.
- Order By: if your query does WHERE customer_id = X ORDER BY created_at DESC LIMIT N, an index on (customer_id, created_at DESC) avoids sorting and is ideal.
- Creating index concurrently: builds index without locking writes (but it is slower). Use CONCURRENTLY in production environment.
Heuristics limits apply to:
- The script uses simple regex extraction to find candidate columns — it can miss columns or misidentify them for complex SQL (subqueries, functions, expressions).
- It does not analyze selectivity (how many distinct values) or table size when proposing index order; in practice you should choose the most selective column first.
Conclusion
We have seen on how we can have a utility tool ( the Python script here) to read the frequently executed queries in our database, accordingly parse them, and suggest us relatable indexes on necessary tables to help our queries run in a more optimized fashion. This improves performance and helps us avoid unnecessarily creating redundant indexes on the database.