

Creating a query is easy. Writing a well performing query can be a challenge. Application developers are taught specific patterns for writing efficient, easily maintainable code. Patterns like: an overarching routine should perform a series of steps and compartmentalizing code will allow for reusability. These patterns create a top-down approach to writing code, but it may not be the best pattern for writing T-SQL. Let’s take a look in the second part of this series.
Compartmentalizing code will allow for reusability
When I was an application developer, I prided myself on reusable code. I had been taught that every function should perform only one task and not be very lengthy. As I began to write more complicated SQL queries, I used this same approach.
SQL Server provides several ways to create discrete SQL objects that will return a table or a single piece of data. They include scalar functions, in-line table functions, multi-line table functions, stored procedures, and views. You could include Common Runtime Libraries (CLRs) in this group, but that is whole other discussion. When concise queries are written, that play to the strengths of the particular SQL object type, they perform well and can be a great asset to a database. However, if they are used like building blocks to create complicated queries that are N levels deep, then performance problems will start to arise and those problems can be difficult to troubleshoot quickly.
Let’s consider this example
A view was created for a report to provide phone numbers for all of the Sales Associates to contact the Purchasing Agents of each business. It was also requested that the report could be sorted on country, postal code and state. There were two views that already existed that had the information needed, so a new view was created for the report. Below is the view that was created.
CREATE VIEW StoreSlaesPerosnInformation_01
AS
SELECT
ssp.*
,si.ContactType AS StoreContactType
,si.Title AS ContactTitle
,si.FirstName AS StoreContactFirstName
,si.MiddleName AS StoreContactMiddleName
,si.LastName AS StoreContactLastName
,si.Suffix AS StoreContractSuffix
,si.PhoneNumber AS StoreContactPhoneNumber
,si.EmailAddress AS StoreContactEmailAddress
,si.EmailPromotion AS StoreContactEmailPromotion
,si.AddressType AS StoreContactAddressType
,si.AddressLine1 AS StoreContactAddressLine1
,si.AddressLine2 AS StoreContactAddressLine2
,si.City AS StoreContactCity
,si.StateProvinceName AS StoreContactStateProvinceName
,si.PostalCode AS StoreContactPostalCode
,si.CountryRegionName AS StoreContactCountryRegionName
FROM
dbo.StoreSalesPerson AS ssp
JOIN StoreInformation AS si ON si.BusinessEntityID = ssp.StoreBusinessEntityID;
GO
There are several issues when you first look at this view and some that are not so obvious.
Issue 1
The first problem I see is the asterisk being used to return all the fields from dbo.StoreSalesPerson, which is a view itself. This is not a good idea. Why? Longevity of this view. At some point other fields might be added to the underlying tables. That will change which fields are returned from the parent view as well and can break applications and some reporting software.
Issue 2
More fields were returned than necessary. Only the fields needed should ever be returned. This allows for better index selection. By returning all the fields narrower indexes can’t be used to find the data.
Issue 3
StoreSalesPerson and StoreInformation are not the only views being used here. What you can’t see might just hurt your performance. Andy Yun (b|t) built a wonderful stored procedure to help determine all the underlying objects a view is using. It’s called sp_helpExpandView. At the time of this writing, you could download it from here.
(Note: Remember to always test code you have downloaded from the internet in your development environment before using it in your production environment.)
When I ran sp_helpExpandView, I found that there were five views and the same scalar function referenced in two different views being used. They were nested four levels deep and there were 25 table references to 15 unique tables.
Issue 4
Upon additional investigation, I found that the scalar function was querying two tables. Since the scalar function was called twice for every row and there are 765 rows in my data set. The scalar function was executed 1530 times. This is not apparent in the execution plan since the contents of a scalar function are obfuscated and are only represented by a Compute Scalar icon. Note: If you use Profiler, you can see how many reads occur each time the scalar function is executed.
Rewrite Two Ways
The first rewrite, I omitted the fields I didn’t need and added a where statement to only include the Purchasing Agents. This did improve the performance of the query, but not completely. It also didn’t eliminate the use of the scalar functions since they were called by the underlying views.
CREATE VIEW StoreSlaesPerosnInformation_02
AS
SELECT
ssp.BusinessEntityID
,ssp.FirstName
,ssp.LastName
,ssp.PhoneNumber
,ssp.City
,ssp.StateProvinceName
,ssp.PostalCode
,ssp.CountryRegionName
,ssp.TerritoryName
,ssp.TerritoryGroup
,ssp.StoreBusinessEntityID
,ssp.Name AS StoreName
,si.FirstName AS StoreContactFirstName
,si.LastName AS StoreContactLastName
,si.PhoneNumber AS StoreContactPhoneNumber
,si.City AS StoreContactCity
,si.StateProvinceName AS StoreContactStateProvinceName
,si.PostalCode AS StoreContactPostalCode
,si.CountryRegionName AS StoreContactCountryRegionName
FROM
dbo.StoreSalesPerson AS ssp
JOIN StoreInformation AS si ON si.BusinessEntityID = ssp.StoreBusinessEntityID
WHERE
si.contactType = 'Purchasing Agent';
GOI rewrote the entire query for the second rewrite and only used the tables that were needed. I didn’t use any other views or functions. This gave me 17 table references of 11 unique tables.
CREATE VIEW StoreSlaesPerosnInformation_03
AS
SELECT
sp.BusinessEntityID
,p.FirstName
,p.LastName
,pp.PhoneNumber
,a.City
,stp.Name AS StateProvinceName
,a.PostalCode
,cr.Name AS CountryRegionName
,st.Name AS TerritoryName
,st.[Group] AS TerritoryGroup
,s.BusinessEntityID AS StoreBusinessEntityID
,s.Name AS StoreName
,cp.FirstName AS StoreContactFirstName
,cp.LastName AS StoreContactLastName
,cpp.PhoneNumber AS StoreContactPhoneNumber
,ca.City AS StoreContactCity
,csp.Name AS StoreContactStateProvinceName
,ca.PostalCode AS StoreContactPostalCode
,ccr.Name AS StoreContactCountryRegionName
FROM
Sales.SalesPerson sp
JOIN Sales.Store AS s ON sp.BusinessEntityID = s.SalesPersonID
JOIN Person.Person p ON p.BusinessEntityID = sp.BusinessEntityID
JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = sp.BusinessEntityID
JOIN Person.Address a ON a.AddressID = bea.AddressID
JOIN Person.StateProvince stp ON stp.StateProvinceID = a.StateProvinceID
JOIN Person.CountryRegion cr ON cr.CountryRegionCode = stp.CountryRegionCode
JOIN Sales.SalesTerritory st ON st.TerritoryID = sp.TerritoryID
JOIN Person.BusinessEntityContact bec ON bec.BusinessEntityID = s.BusinessEntityID
JOIN Person.ContactType ct ON ct.ContactTypeID = bec.ContactTypeID
JOIN Person.Person cp ON cp.BusinessEntityID = bec.PersonID
JOIN Person.BusinessEntityAddress cbea ON cbea.BusinessEntityID = s.BusinessEntityID
JOIN Person.Address ca ON ca.AddressID = bea.AddressID
JOIN Person.StateProvince csp ON csp.StateProvinceID = ca.StateProvinceID
JOIN Person.CountryRegion ccr ON ccr.CountryRegionCode = csp.CountryRegionCode
LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID = p.BusinessEntityID
LEFT JOIN Person.PersonPhone cpp ON cpp.BusinessEntityID = cp.BusinessEntityID
WHERE
cpp.PhoneNumberTypeID = 3
AND pp.PhoneNumberTypeID = 3
AND bec.ContactTypeID = 14;
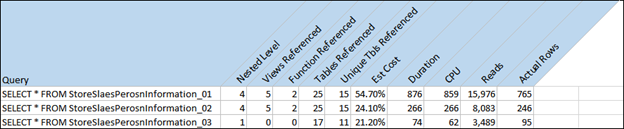
GOBelow is a comparison of each of the views I wrote above. You can see that not only did the third view perform better, but returned less rows. Why was that? The first query didn’t do any filtering. It left all the filtering to the report. The second view filtered on the contact type “Purchasing Agent”, but it ignored the fact that 1 or more addresses were being provided for each Sales Associate and each Purchasing Agent. This data was ignored since addresses weren’t the focus of the report. The third view only retrieved the data that was needed to build the report.
Conclusion
These types of patterns are not bad, but they need to be used correctly. Instead of nesting views or other objects several levels deep, consider duplicating code. While I agree, rewriting the same SQL statement is as fun as reinventing the wheel, our goal is not to write less SQL, but to write efficient SQL. Comments can always be added to let other teammates know there is duplicate SQL statements in the database. In the end, we need to find the balance of writing the best performing queries with the fewest SQL statements while still making it easy to maintain.
