The goal of this Stairway series is to provide a brief, practical and systematic guide to source controlling your SQL Server databases, so that you can then manage your ongoing development and deployment from a known version, within source control.
The primary target audience is the database developer or DBA who has some familiarity with source control concepts and systems, perhaps from application development, and wishes to source control their databases. As such, I do not offer more than a brief, general introduction to source control concepts and operations, but throughout I do demonstrate practical examples of core source control operations such as updating, committing changes, branching, merging and so on specifically as they apply to developing databases.
In the interests of practical focus, I do not attempt to describe all possible options for source controlling a database. Instead, I offer a specific formula for effective database source control, based on the tools I use in my own development work, as follows:
- A centralized (client-server) source control system – all of the examples in Levels 1-4 use Subversion and in this first level we'll walk through the basic repository setup that you'll need to work through these examples.
- A distributed source control system – some of the examples in Levels 5 and later use Git, and explain the key differences when working with a distributed rather than centralized source control system. Level 5 will explain the basic setup required for the Git repository, in order to work through those examples.
- A source control plug-in for SQL Server Management Studio – this is a third-party tool, Redgate SQL Source Control, which integrates into SSMS to allow the developer team to work from within SSMS with database files stored in a source control repository and perform routine source control operations within SSMS, for example to update, edit, add, delete and commit database objects to the repository, without having to break workflow into a traditional client.
- A traditional source control client – for operations we may need to perform outside of SQL Source Control. In this case, I use TortoiseSVN, which integrates into Windows Explorer, or I execute the required operations directly against the source control server, from the command line.
It is certainly not the only possible approach, and I make no claims that it is the best, but only that it works very well for my development team. If you already use a different source control system, centralized or distributed, you should still be able to work through the examples reasonably easily, though you may encounter some inevitable differences in terminology between the systems described here and your own. Although several sections in the stairway will demonstrate how to work with and manage source controlled databases through the SQL Source Control tool, I will also provide a brief description of alternative manual techniques using only a native GUI client, or the command line.
Source Control: the inevitable but brief overview
A source control system stores and manages a set of course code files, tracking every revision to every file, assigning version numbers, and maintaining an audit history of all changes made by users. A source control system is essentially a version control system (VCS), designed specifically for managing code files. However, VCSs exist to manage a wide variety of different types of files and documents.
A VCS allows a team to see as a cohesive unit each set of revisions to the files that comprise their application, database, or documentation. It also provides a means for teams to work collaboratively on these source files. In most implementations, each file in the repository represents the latest version of a specific database object, but we will discuss this in more detail in later levels.
Two major components of any source control system are:
- The repository – stores an audit history of every change made by users, including metadata such as the user and date/time of the change
- Local working folder – each user retrieves copies of the files from the repository and saves them to a private working folder, usually on their local workstation, in order to edit them before saving them back into the repository
Source control systems fall broadly into two categories distributed and centralized (client-server). We'll discuss each type of system, and their differences, in much more depth in later levels but, in short, a centralized system consists of a single central repository that retains the full version history for all the files that comprise a project. Multiple users update their local working folder with copies of the latest files in the repository, edit them as necessary in their IDE of choice, and then commit the changes back to the repository, creating a new version of the file.
A centralized source control system, such as Subversion, stores primarily the deltas between the versions, which means that it may need to "rebuild" a particular version, on request, rather than simply retrieve it. The team can view the specific changes made to the code between one version and the next by performing a diff.
In a distributed source control system, all clients have both a local working folder and a local repository. Each user can pull a change set from a remote to a local repository, work offline while maintaining full version history, then push a change set from their local repository to a remote repository. In a distributed source control system, such as Git, each repository stores the full text of the object for every version.
Tip – Exploring the differences between Centralized and Distributed source control
This series will cover some of the nuances of the operational differences, but I don't attempt to offer a comprehensive dissection of distributed versus centralized source control systems. If you wish to compare source control systems, and know the features that you will require, Wikipedia provides a helpful, if slightly overwhelming comparison: http://en.wikipedia.org/wiki/Comparison_of_revision_control_software.
While commonplace in application development, source control remains, for various reasons we'll discuss, a relative rarity in database development. We'll discuss the advantages of source control, generally, and then focus in on why it is necessary to source control your databases, alongside your applications, and the challenges of database source control.
Advantages of Source Control
Most developers appreciate fully the benefits that version control brings to the application development. It allows multiple developers to work on a system in isolation, but sharing each change with the rest of the team by committing it to the repository. For certain sets of changes, the team can branch the code, make a cohesive set of changes, and merge those changes back in when the feature is completed. There are differences in the ways in which centralized and distributed systems support concurrent modifications and how they handle merging, in the case of conflicting changes to a file. However, we will not discuss branching and merging operations in full detail until Level 6 and beyond.
Tip – Commit frequently, Update frequently
It's never too early to start thinking about solid working practices with source control systems! It is a recommended practice, even when working on a branch, to commit to the repository often, ideally after each atomic change (i.e. each change that takes the database from one consistent, working state to another). In this way, you maintain a history of changes, back up your work to the repository, and can collaborate easily with others, for example for peer review. It's equally important to update your working folder frequently, and local repository, if applicable, with the changes of others. This will ensure your branch or local working copy doesn't drift too far apart from the latest version in the remote or central repository, and well help minimize painful merge operations.
The VCS offers a single location from which anyone in the team can extract the latest build of a product or feature, and trace a history of code changes across all versions and releases. It promotes a development methodology based on small, incremental updates and improvements, committing frequently to source control. With all code in source control, it becomes possible, or at least much easier, to maintain a full audit history for the project. We can, for example:
- Find out what has, and has not, changed in our code since a previous release
- Ensure all required code changes made are released, with no changes "left behind" on a developers workstation
- Avoid having one developer accidentally and irrevocably overwrite another's change
- Generate an upgrade script, and release notes, which reflect accurately all of the required changes
- Generate a script to roll back a change to any previous release of the code, say for bug fixing
- Create a separate branch for a project so that different development efforts can occur in parallel (e.g. bug fixing a current release whilst developing the next release)
- Mark releases of code and port specific changes, such as important bug fixes, to previous releases.
These benefits apply not only to the code, but also to important system data, such as reference data, or the configuration settings for an application.
For many teams, source control is the foundation for many further benefits. On each change committed to the VCS, they have automated tests to verify it. If the tests pass, an automated build process builds the new version, directly from source control, and deploys it to the build server, in a process known as Continuous Integration (CI). In this way, we can validate each atomic change and confirm that we always retain a working system. As a team gains experience and expertise, they can expand this process still further to include Continuous Deployment (CD), whereby if all the tests pass, the latest version deploys automatically to the target environment. We won't, be discussing the intricacies of CI or CD, in this series.
Why use Source Control for Databases?
A database is part of our application and it is natural to want to source control the application's data tier, in the same way that we would want to include any other key aspect of our application, and in so doing gain all the same benefits. Ask your application developers if they would choose to do away with source control for their application code, and see what the answer is! Yet too many teams fail to apply to their databases the same rigorous versioning and testing that they apply to application code.
There are a few reasons for this. Firstly, database source control presents difficult challenges (discussed shortly) and the source control tools that help handle them, and integrate well into the development workflow, are relatively new.Secondly, database development often sits in a different part of an organization to application code development.
In order to understand why having the database in source control is so important, let's explore briefly some of the difficulties commonly associated with developing, building and deploying databases without proper source control.
A situation I still encounter frequently is that developers all work on a single shared database (a model discussed in more detail in Level 2). Rather than build and deploy the database from a VCS (even if the database is scripted into VCS, for the sake of form), the team relies on regular database backups of the development environment to 'save' progress and allow them to deploy the database to a different environment (such as testing), and also to allow them to restore to a previous version, if required.
Unfortunately, this approach is fraught with difficulties. For example, the full database backup may take place halfway through a database change, such as after a developer changes a table definition but before he or she updates all of the corresponding stored procedures. This could mean that the application may not even run on that version of the database. Developers need to test backups regularly.
Tip – Restoring Development Databases
Most production databases operate using the FULL recovery model, which necessitates log backups as well as full database backups. However, this enables point in time restore operations, rolling forward through the log backups to restore to a very specific point in time that contains all the necessary changes. We almost never have this capability in development databases, which almost always operate in SIMPLE recovery model, allowing full database backups only and meaning we can only restore the most recent full backup.
Furthermore, there is no easy way to work out exactly what changed from one deployed version of the database to another, other than perhaps using a third party tool to compare the backups. When it comes time to deploy the database to a live production environment, this is when the DBA gets involved. He or she will often face the unenviable task of generating a script to deploy the new database, or update the existing database, from the 'moving target' of the shared development database, generating the scripts simply by comparing the current live development database with the current live production database. It's inevitable that, at some point, someone will change the source or target database after the DBA generates the script, rendering it "incomplete" or the new target database invalid. The task is even more onerous if the DBA needs to propagate a set of changes to multiple different environments.
In addition, without source control, there is also no proper, granular record of every change that constituted the new deployment, making it very difficult to track down and fix, or roll back, a breaking change. When the inevitable breaks happen, the viable path is simply to attempt to 'patch' the production server directly, which is hardly ideal.
It is only by versioning our databases, alongside the applications that rely on them, that we can know exactly what changed from one version of a database to the next. We get a complete record of changes to objects in deployed databases, making it much easier to identify when and why someone made a change.
By always deploying from a known version in source control, and never making live updates to a production server, we can test fully the scripts required to build the database in a new environment, as well as the script necessary to roll back the changes, if necessary.
In short, we get more reliable, repeatable deployments, and by storing the database alongside the application, in source control, it makes it much easier to build and deploy them together.
Database Source Control Challenges
One of the biggest challenges for change management of databases is that we must consider the data to be part of the final state of the database. Once we deploy a database to the business, we cannot simply "tear it down and rebuild it" but must perform the update in a way the preserves data integrity and continuity. This often involves use of various additional 'migration scripts' or 'change scripts' to enable existing data to fit in any changed schema. We will discuss approaches to mitigate this sort of complication, as we move up the levels in this stairway.
The mere fact of having our databases in source control does not necessarily make performing database deployments easy. Generating the required deployment scripts can still require some frustrating searching through Source Control to gather together all the required files and then working out how to apply all the necessary changes in the correct order. The database is still key to the business, and existing constraints and pressures around minimizing downtime will still apply. To address this, DBAs put a lot of planning and testing into deployments. Having the database in source control will give us confidence that all required changes are known and in place, forming a good basis for planning our deployment and minimizing risk.
As for applications, with our databases in source control, we can begin the process of automating our database deployments, implementing database testing and continuous integration processes that will help us move towards "click-button" deployments.
Furthermore, source controlling just the schema and database-scoped objects (tables, views, stored procedures and so on) doesn't necessarily make it easy to deploy the same database to different environments; there are likely to be differences in the database or SQL Server configurations, or differences in the security environments, that will inevitably mean that a deployment script that works perfectly for one environment fails for another environment.
In this Stairway, we'll focus largely on source controlling the data objects (tables, stored procedures, functions, etc.) and reference data. However, you may also, depending on your application, choose to store in source control other objects and files, such as:
- Database- and instance-level configuration settings – which can be gathered as described by Brad McGehee
- User and security configuration settings
- SQL Server and file-level configurations settings
By separating database code from database configuration/security, and storing both in source control, we make it much easier to deploy the same database to multiple environments.
Getting Started: the tools
In order to implement Source control for SQL Server databases, we will need to install some software. It's likely that most people reading this stairway will have some if not all of the required tools, but I'll step through each one for the benefit of anyone starting from scratch.
SQL Server
To develop and test the examples in this Stairway, I installed on my developer workstation SQL Server 2012 Developer Edition, which is functionally equivalent to Enterprise Edition but for non-production use only.
However, as long as you have a computer with SQL Server 2005 or later, any edition except Express Edition (SQL Source Control does not work with Express), then you should be able to follow along.
Source Control Server
You'll need to install and configure a Source Control Server. All of the examples in Levels 1-4 of this Stairway use Subversion (SVN), a revision control system created by Collabnet and provided as an open source Apache project. It remains, at time of writing (March, 2014), the most popular centralized source control system, in which one or more clients interact with a single, central repository. Of course, there are other centralized source control systems, such as Team Foundation Server, and if your team already uses one of them, you should still be able to work through the examples seamlessly.
Distributed source control systems such as Git or Mercurial, are becoming increasingly popular. Some of the examples in Level 5 and onwards use Git, a distributed source control system and highlight the key differences with regard to concurrent development with source controlled databases.
The type of source control system you choose may depend upon several factors, including the physical location of your developers. If the team is not all on the same network, there are many advantages to the distributed source control system, such as the built in tolerance for periodic connection to the network; we will cover these in more detail in Level 5.
However, the biggest deciding factor is usually existing investment in source control in the business i.e. what your developers are comfortable using, as any system that is not well respected will not be properly adopted. Further, if you have applications developed using source control there are considerable benefits to using the same system for associated database(s), as it means that you have both application and database code together at the same point in time. Politics can also come into play, for example, which team controls the source control system, and who has oversight over deployment, but this should not be a huge factor.
Using the same solution for application as database development is key to a smooth development process. In the circumstance where different application teams are using different source control systems within the same organization, I would suggest that it is better to put the database development into the source control used by the relevant application team, even if that means that your organization then has different source control systems for different databases. SQL Source Control provides a unifying interface so that developer workflow is broadly the same even when using different source control systems.
Source Control Client
We don't necessarily need a GUI client to work with our source control repository; we can (and I often do) execute commands against it directly from the command line. However, traditional source control clients, either standalone applications or integrated into Windows Explorer, allow developers a more visual way to perform the various required source control operations (update, commit and so on).
For example, when working with SVN, we can use TortoiseSVN. We create a working folder for the project in Windows Explorer, link it to the repository, and update it with the latest files. Developers then edit each file in their development environment, such as Visual Studio, save it back to the working folder and then, from there, commit the changes back to the repository.
For application files this is a natural way to work, and of course we can extend this to databases, scripting out all the files and working with them from source control. However, most database developers tend to work in a different environment (SSMS rather than VS), and are typically more used to working not with files but with "live" databases, containing data.
Integrating source control directly into the database development workflow brings productivity gains; not only can it take less time to do, making it less likely that committing code to source control will be forgotten, but it can also reduce task switching and so improve productivity.
Fortunately, there are a number of ways of integrating database source control into our developer workflow. If using SQL Server Data Tools (SSDT) for database development, we can exploit its built-in integration to Microsoft's Team Foundation Server to get all of the scripts that comprise our database into source control, from where we can build our database.
A second option, and the one I use, is Redgate's SQL Source Control tool (SQL Source Control), an SSMS add-in. All developers link their local copy of the database to the same project directory, in the VCS. Developers modify their local databases, as required, and then commit the changes to the VCS, directly from within SSMS. Behind the scenes, SQL Source Control uses the SQL Compare engine to compare the schema of the developer's local database with the current version in the VCS and generates the change script. In a similar fashion, developers can update their local database with the latest database object versions from the repository, as other users make their changes.
Out of the box, SQL Source Control links to SVN, TFS, Git and Mercurial, and to other source control servers with a small amount of configuration. Note though that SQL Source Control does not support all features for all source control systems, although the situation changes quickly, so check the latest documentation. For example, at the time of writing SQL Source Control supported use of migration scripts only for centralized, and not distributed, VCSs.
Tip – Migration scripts
If we're deploying a database upgrade, we need to ensure we preserve the existing data, and for some changes the tool needs some help in describing the change accurately. For example, if we rename a table, the tool has no way to know we did this, as opposed to dropping a table with the old name and creating a new table. On such occasions, we use migration scripts to define exactly how we wish the change to proceed. We'll use migration scripts later in the Stairway.
This stairway, as a whole, will demonstrate how to use SQL Source Control to tie our database into our source control system. As we'll discuss further as we progress, a tool such as SQL Source Control alters some of the traditional workflow. For example, we can link a database to source control without the need to create explicitly a working folder or load it with all the source files. Through SQL Source Control, we perform most of the common operations such as getting the latest updates from the repository, and committing changes, but for others, we'll still need to work with a native client (or command line).
Setting up the SVN Repository
If you already have SVN, or some other centralized Source Control Server, then you can skip much of this section, though it may still be worth reading the sections on Security and especially on Creating a Repository, to set up the example repository for this Stairway.
There are several available distributions of SVN Server. Purely because it is the tool with which I am familiar, I use Collabnet's SVN Edge, which is a stack that provides SVN Server as well as the Apache web server and a repository viewer (ViewVC). Other options include Visual SVN Server, exclusively for the Windows platform.
Warning – SVN Edge requires Java
Before you install, note that SVN Edge requires a specific version of Java (at the time of writing – March 2014 - Java 6). If this is a problem, you should be able to follow along using a different SVN server, although some source control operations will be a little different, procedurally.
The install process for SVN Edge is straightforward and described clearly in the Install Subversion Edge section of the documentation, so I won't repeat those details here. I accept the default options, although if your target server already runs a web server, such as IIS, then you will need to assign Apache server to a different port. Note also that the installer displays a ReadMe file at the beginning of the installation, which includes the default credentials; you will need these once you have installed the software.
When the install process completes a browser opens. When the SVN Server starts up you'll see the word "Ready", and you can click on the link to login (or browse to the link provided in the ReadMe). Once logged in, you will see the status information page, from which you can manage repositories, start and stop the SVN server, as well as configure more advanced features, such as LDAP authentication (to tie into a Windows Active Directory Domain).
Security
By default, you'll log in for the first time as a "Super Administrator" and you should immediately change the default security settings for this account. Click on the "Super Administrator" user and then the "Edit" button, to reveal a "Change Password" link.
Next, we need to create a new user that doesn't have administrative privileges and so can't accidentally change the server's configuration. Click on Users, in the title row, and then Add. Give the user a name and assign it the ROLE_ADMIN_REPO and ROLE_USER permissions to allow the user to make changes to repositories. Finally, log out and log back in as the new user.
Creating a Repository
Back on the status page, we are confronted with a currently-empty repository list. We need to create a repository, so click Create.
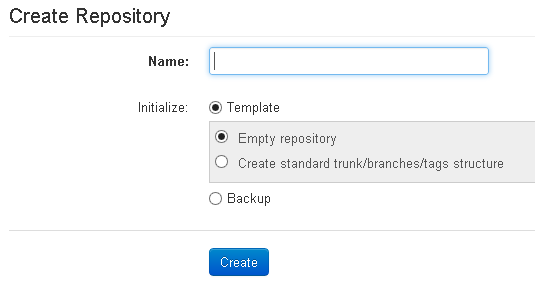
Figure 1.1: The Create Repository screen
Give the new repository a name, in this case AdventureWorks, since we're going to put the AdventureWorks database into source control.
Tip – Repositories per project
It is not necessary to have a new repository for each database, although I do that here for demonstration purposes. I find a good balance is to have a repository for each separated project, which may comprise application, a number of databases, and any related documentation held in source control, all within their own directory structure. It is perfectly valid, however, to have one repository for all the development your team does. Define your repository structure carefully, based on the structure and workflow of your team.
We have the option either to create an empty repository, or to create what is known as a trunk/branches/tags structure, in other words with a specified directory for each:
- Trunk – your "mainline" development. It is generally regarded as best practice to ensure this is always in a usable state for other developers to check out.
- Branches – we can create a branch for each separate stream of development work, for example a branch for each major feature, a branch for bug-fixes, a branch or 'special' code, under development for the future, but not part your main development effort, and so on
- Tags – a tag is like a branch but intended to be a read-only copy of a particular repository revision. These are often used to mark specific releases of the code.
Commonly, database development and application development could both sit within the trunk, and be branched together. This makes sense where the two are developed in parallel, as it we means we can branch a given feature, comprising both database and application code, as a single operation.
Using an empty repository, with all the objects in the root, may work fine for simple projects, but will limit future branching options. I prefer to use the established standard, which is the trunk/branches/tags structure, since it forces the team to plan out how they will manage development over time. However, you can use an empty repository and impose your own structure should that suit your workflow better.
In my team, for example, we do most of our development in trunk, and only branch when necessary (the Branch-When-Needed approach), for example if someone needs to make a very substantial change that may disrupt the work of others on the trunk.
When the whole team mainly work on branch, it instils in each member the discipline of committing small, atomic changes frequently, so that others can review the change quickly, and the trunk remains in a stable, working state. For example, if we rename a column in a table, we would also update any objects reference that column and then perform a single atomic commit for all these changes. Our Continuous Integration engine then uses the latest versions of the application and database, in trunk, to perform unit, and other, testing to confirm that we have no breaking changes. Of course, we should be performing a level of testing before committing to trunk anyway, but the CI engine performs a backup check. It's also possible to set up the CI engine to merge changes from a branch only when they pass tests, guaranteeing that trunk is always working.
To create our repository, select the option Create standard trunk/branches/tags structure option and click Create. The default setup gives all users permissions to read from and write to each repository, but limits access to administrative functions. Obviously, we can adapt users and permissions as required, but for simplicity here we simply accept the default settings.
Having created the repository, click back on Repository List to see it in the list of the repositories in the system, along with the URL which you will need to link to source control in client tools, such as SQL Source Control or TortoiseSVN.

Figure 1.2: Repository list
Setting up the Source Control clients
Setting up SQL Source Control, our SSMS-integrated client, is very simple and entails little more than running the installer, which you can download from the Redgate website (current version at time of writing was v3.5). On launching SSMS, you should see a SQL Source Control tab, plus an entry for the tool on the Redgate toolbar as well as in the Tools menu of SSMS.
Finally, we need to install the native client, TortoiseSVN, which lets us interact with the SVN repository through Windows Explorer, and set up a working folder, linked to our AdventureWorks repository.
For the TortoiseSVN installation, simply select the 64-bit or 32-bit version as appropriate for your version of Windows, follow the onscreen prompts and accept all the default settings. It's a good idea to reboot your machine at this point, otherwise certain functionality such as the appearance of icons to denote that a folder is under version control, may not appear.
To define your local working folder, the first step is simply to create a normal folder (For example, C:\SVN) on the client machine. Bear in mind that Windows has a limit of 256 characters for the path and file name. Therefore, I recommend putting the local working folder as close to the root of a drive as possible to avoid running into naming issues, particularly where you have long schema and object names, which can be up to 128 characters each, as these are reflected in the names of scripted objects.
Our last task is to link our working folder to the AdventureWorks repository. Since we're set up to have one database per repository, we're also going to have one working folder per repository. The alternative, if for example we have one repository called something like "Acme" (for all Acme-related projects), is to link the Acme repository to the C:\SVN folder and then create sub-folders for each project within the trunk.
In our example, we'll create a subfolder, C:\SVN\Adventureworks, right-click on the folder and select SVN Checkout.
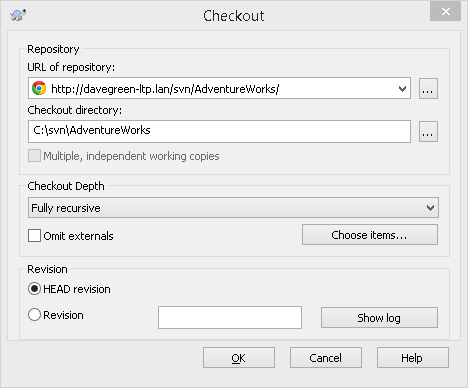
Figure 1.3: Checkout repository
When we click OK, TortoiseSVN contacts the SVN server and requests a copy of the current repository (you may be prompted for your username and password at this stage; they are the SVN credentials we defined earlier).
Once this process is complete, our new working folder, in this case, C:\SVN\Adventureworks, and the branches, tags and trunk sub-directories, have green ticks (you may need to refresh). These denote that our working folder is now tracked by the source control server, and that it contains no uncommitted changes.
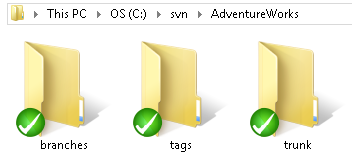
Figure 1.4: The AdventureWorks repository checked out
Summary
This first level introduced, briefly, some of the core source control concepts, and why it's so important that we develop, build and deploy our databases from source control. We installed the tools and services we need to source control our databases, and created our initial repository structure and working folder.
We're now all set up for Level 2, where we will put the AdventureWorks database into source control.
 SQL Source Control Basics
SQL Source Control Basics
If you're looking to continue along the path of database source control, this eBook gives a detailed walkthrough of the concepts, complete with code samples.