What queries to tune first?
-
Hi All,
This is in regards to server slowness. If I had to tune top 10 resource consuming queries which ones has to be targeted first and why?
-Long running queries / Blocked queries / High Duration
-I/O consuming queries / memory consuming queries
-CPU consuming queries
-User specific chosen queries
Also, what high values we need to consider for thresholds to determine for long running . high cpu , high reads/high writes?
Regards,
Sam
-
Hello Sam,
I would start with User specific chosen queries ( as you get paid for those )
As tuning can be a lengthy process , you can stop when it's good enough. No fixed thresholds as each application/user is different
If there is a troublesome interval when the DB isn't very responsive you could look for blocking / waits and focus on which queries are attributing to it
Most likely it's statitics and sargeable queries
sp_WhoIsActive and sp_BlitzFirst make a good starting point
https://www.brentozar.com/sql/sql-server-performance-tuning/
-
pick the one your consumer complaints most about.
After all, "slow" is a consumer experience.
Johan
Learn to play, play to learn !Dont drive faster than your guardian angel can fly ...
but keeping both feet on the ground wont get you anywhere :w00t:- How to post Performance Problems
- How to post data and code to get the best help- How to prevent a sore throat after hours of presenting ppt
press F1 for solution, press shift+F1 for urgent solution 😀
Who am I ? Sometimes this is me but most of the time this is me
-
To add to what Johan posted, your worst performing queries will NOT usually be your longest running queries and it may not be the queries themselves, at all... it could be the associated compile time for the queries.
An example of this is that the users were having to wait for a long time to have a screen return on one of the screens our folks had built. No one could figure it out because every time they ran the associated stored procedure, it ran in "only" 100 ms (which was still horrible for what it did IMHO).
The performance issue turned out to be the time it took for the proc to recompile and because of the "string literal/non-parameterized" method they were using to call the proc, it recompiled nearly EVERY time it got called and the recompile was taking anywhere from 2 to 22 SECONDS!
I had the Devs change the code that was calling the proc to be parameterized (which also solved the inherent SQL Injection problem that was also built in) and a minor tweak to the proc caused the proc to run in 1-2 ms and seriously reduced the I/O, which was important because the proc was called ten of thousands of time per hour.
So, here's my order of priority of what to fix...
- Anything and everything that is perceived as being slow by the front-end users.
- Reporting code. Typically it's horrible for the system and the users excuse the time it takes to run because "it's processing a lot of data", right? Yeah... those damned things are also stealing CPU and I/O time from the front-end users.
- Batch processing jobs (tied with #2 in priority) that may be causing general system slowdowns when running as perceived by the users.
- Batch processing jobs that have to run overnight or during supposed "quiet" times. A lot of people dismiss these because they don't interfere with the user perception BUT... eventually, you're going to run out of "overnight" and "quiet" times. Such things can also have problems because of the size of log file backups and deadlocks and timeouts and even steal time from the nightly backups and other tasks such as corruption checks, etc, etc, ad infinitum. This could actually bubble to the top of the priory list when it overruns the allotted time and becomes an issue for user perception. ("The database is slow).
In all cases, my mantra is "Make it work, make it fast, make it pretty... and it ain't done 'til its pretty". 😉
The real problem is when people don't write code with performance in mind to begin with. Then you end up with the "Death by a Thousands Cuts" where there is no easy fix to fix a performance issue and you have to fix sometimes dozens of little things to get the adequate performance. This is usually the case after you've fixed the first 3 to 10 performance issues that are large problems. Everything else is frequently "small stuff" and, in the case of databases and other code, "the small stuff actually DOES matter sow sweat it ALL the time".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
One place to start is reviewing the "Top 10 Avg I/O Queries". See if anything stands out there.
Next I'd review the index stats. Looking particularly at missing indexes and the clustered indexes, to see if they match what is really needed. Most often they will not. Personally I'd correct that even as you were reviewing individual queries. If the clus index is wrong, that will affect almost the whole range of queries against that table. Do this in descending size order, since obviously the larger the table/index, the more overall effect it will have on the system.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jeff Moden wrote:
To add to what Johan posted, your worst performing queries will NOT usually be your longest running queries and it may not be the queries themselves, at all... it could be the associated compile time for the queries.
An example of this is that the users were having to wait for a long time to have a screen return on one of the screens our folks had built. No one could figure it out because every time they ran the associated stored procedure, it ran in "only" 100 ms (which was still horrible for what it did IMHO).
The performance issue turned out to be the time it took for the proc to recompile and because of the "string literal/non-parameterized" method they were using to call the proc, it recompiled nearly EVERY time it got called and the recompile was taking anywhere from 2 to 22 SECONDS!
I had the Devs change the code that was calling the proc to be parameterized (which also solved the inherent SQL Injection problem that was also built in) and a minor tweak to the proc caused the proc to run in 1-2 ms and seriously reduced the I/O, which was important because the proc was called ten of thousands of time per hour.
So, here's my order of priority of what to fix...
- Anything and everything that is perceived as being slow by the front-end users.
- Reporting code. Typically it's horrible for the system and the users excuse the time it takes to run because "it's processing a lot of data", right? Yeah... those damned things are also stealing CPU and I/O time from the front-end users.
- Batch processing jobs (tied with #2 in priority) that may be causing general system slowdowns when running as perceived by the users.
- Batch processing jobs that have to run overnight or during supposed "quiet" times. A lot of people dismiss these because they don't interfere with the user perception BUT... eventually, you're going to run out of "overnight" and "quiet" times. Such things can also have problems because of the size of log file backups and deadlocks and timeouts and even steal time from the nightly backups and other tasks such as corruption checks, etc, etc, ad infinitum. This could actually bubble to the top of the priory list when it overruns the allotted time and becomes an issue for user perception. ("The database is slow).
In all cases, my mantra is "Make it work, make it fast, make it pretty... and it ain't done 'til its pretty". 😉
The real problem is when people don't write code with performance in mind to begin with. Then you end up with the "Death by a Thousands Cuts" where there is no easy fix to fix a performance issue and you have to fix sometimes dozens of little things to get the adequate performance. This is usually the case after you've fixed the first 3 to 10 performance issues that are large problems. Everything else is frequently "small stuff" and, in the case of databases and other code, "the small stuff actually DOES matter sow sweat it ALL the time".
Thanks everyone for sharing your inputs.
Sometimes we are seeing below patterns
"Application runs a query every 10 mins without any good reason."
There is a MERGE statement which does some data consolidation is being run very 10-15 mins. I dont know why. They are giving weird reasons saying its a business decision. The first MERGE is still running other one starts. After 10 mins another starts. Seeing huge blocking chains at certain times. We have configured blocking alert to be triggered if blocking happening for more than 5 mins. When the app team receives that alert. eventually we had to kill the whole process and they restart the app servers again. I don't know why they are doing that stuff. May be lack of knowledge of the vendor specific app/db and many people has made their hands dirty . Many consultants come in and leave within 6-8 months. The data types are very horrible nchar, nvarchar, text, GUIDS as clustered idx's, too many heap tables, unnecessary indexes created. if we see the usage stats of those indexes/duplicate ones, its very minimal. If we collect that data and send it dev folks, they say, its vendor specific database called MDM (Master Database Management) from Informatica and they say they don't have any control over the code or db design. We dont even know whether they are telling lies or truth. However, we see a lot of code push happening every 2 weeks. Really having a hard time with that specific project team.
Regards,
Sam
- vsamantha35 wrote:
Thanks everyone for sharing your inputs.
Sometimes we are seeing below patterns
"Application runs a query every 10 mins without any good reason."
There is a MERGE statement which does some data consolidation is being run very 10-15 mins. I dont know why. They are giving weird reasons saying its a business decision. The first MERGE is still running other one starts. After 10 mins another starts. Seeing huge blocking chains at certain times. We have configured blocking alert to be triggered if blocking happening for more than 5 mins. When the app team receives that alert. eventually we had to kill the whole process and they restart the app servers again. I don't know why they are doing that stuff. May be lack of knowledge of the vendor specific app/db and many people has made their hands dirty . Many consultants come in and leave within 6-8 months. The data types are very horrible nchar, nvarchar, text, GUIDS as clustered idx's, too many heap tables, unnecessary indexes created. if we see the usage stats of those indexes/duplicate ones, its very minimal. If we collect that data and send it dev folks, they say, its vendor specific database called MDM (Master Database Management) from Informatica and they say they don't have any control over the code or db design. We dont even know whether they are telling lies or truth. However, we see a lot of code push happening every 2 weeks. Really having a hard time with that specific project team.
Regards,
Sam
To be honest, it sounds like the Development Team needs to get their act together and fix some a lot of stuff, as well. That's not a problem we can help you with. We can only sympathize we you because a lot of us have similar issues. Know that you're not alone here and even the best shops run into such issues. How it is handled unfortunately starts with DBA... you have to make "nice-nice" but point out the issues that you, as the DBA, cannot fix and the "team" needs to fix some things without everyone breaking out large hammers to blame the other group(s).
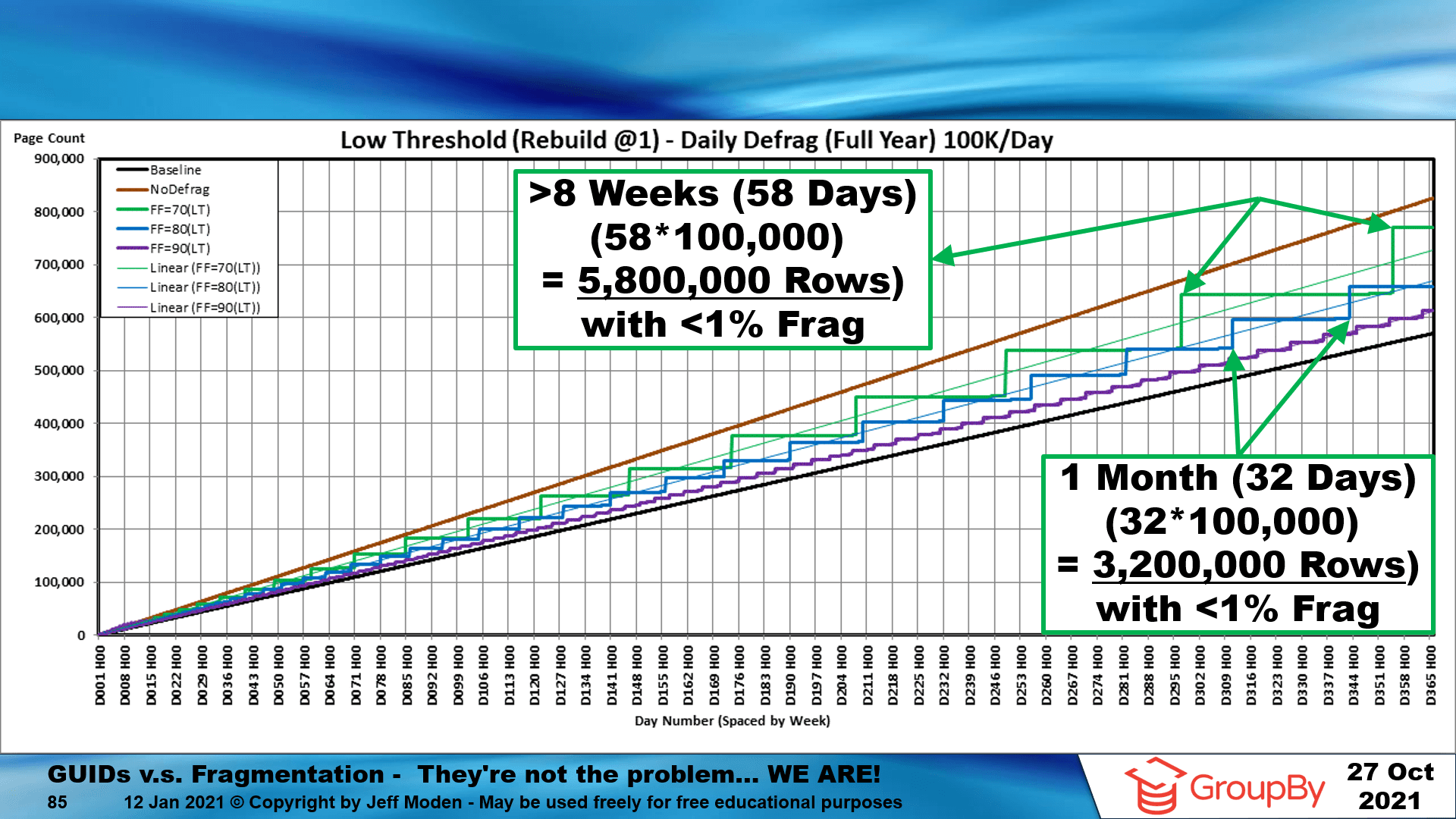
I'll also tell you that GUIDs as Clustered Indexes are a problem only in the fact that range scans on on the GUID are pretty useless and they bloat the Non-Clustered Indexes. However, they can be absolutely fantastic in multiple ways and the idea of them fragmenting a lot is actually a more than 2 decade old myth perpetuated by insufficient demonstrations/testing and belief in another more than 2 decade old myth known as "Best Practice" Index Maintenance.
For proof that both those issues are a myth and what the 2 simple fixes are, please see the following video and may close attention to everything including the section AFTER the Q'n'A because I also prove that GUIDs fix the insertion hot-spot, actually PREVENT fragmentation due to inserts and "ExpAnsive" updates and that you can go literally MONTHs with a regularly inserted Random GUID based Clustered Index with less than 1% logical fragmentation and no index maintenance for those same months. On large tables over time, that will be true for quarters and that the larger the table gets, the better all of that is.
AND, the lessons learned about GUIDs in the video, can be applied to other types of indexes, as well.
Here's the link. If you don't watch it, you'll just continue to suffer. 😀 😉
https://www.youtube.com/watch?v=rvZwMNJxqVo

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - vsamantha35 wrote:
There is a MERGE statement which does some data consolidation is being run very 10-15 mins. I dont know why. They are giving weird reasons saying its a business decision. The first MERGE is still running other one starts. After 10 mins another starts. Seeing huge blocking chains at certain times. We have configured blocking alert to be triggered if blocking happening for more than 5 mins. When the app team receives that alert. eventually we had to kill the whole process and they restart the app servers again.
Is the target table of the MERGE statement also changed by other procedures?
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
- Jeff Moden wrote:vsamantha35 wrote:
Thanks everyone for sharing your inputs.
Sometimes we are seeing below patterns
"Application runs a query every 10 mins without any good reason."
There is a MERGE statement which does some data consolidation is being run very 10-15 mins. I dont know why. They are giving weird reasons saying its a business decision. The first MERGE is still running other one starts. After 10 mins another starts. Seeing huge blocking chains at certain times. We have configured blocking alert to be triggered if blocking happening for more than 5 mins. When the app team receives that alert. eventually we had to kill the whole process and they restart the app servers again. I don't know why they are doing that stuff. May be lack of knowledge of the vendor specific app/db and many people has made their hands dirty . Many consultants come in and leave within 6-8 months. The data types are very horrible nchar, nvarchar, text, GUIDS as clustered idx's, too many heap tables, unnecessary indexes created. if we see the usage stats of those indexes/duplicate ones, its very minimal. If we collect that data and send it dev folks, they say, its vendor specific database called MDM (Master Database Management) from Informatica and they say they don't have any control over the code or db design. We dont even know whether they are telling lies or truth. However, we see a lot of code push happening every 2 weeks. Really having a hard time with that specific project team.
Regards,
Sam
To be honest, it sounds like the Development Team needs to get their act together and fix some a lot of stuff, as well. That's not a problem we can help you with. We can only sympathize we you because a lot of us have similar issues. Know that you're not alone here and even the best shops run into such issues. How it is handled unfortunately starts with DBA... you have to make "nice-nice" but point out the issues that you, as the DBA, cannot fix and the "team" needs to fix some things without everyone breaking out large hammers to blame the other group(s).
I'll also tell you that GUIDs as Clustered Indexes are a problem only in the fact that range scans on on the GUID are pretty useless and they bloat the Non-Clustered Indexes. However, they can be absolutely fantastic in multiple ways and the idea of them fragmenting a lot is actually a more than 2 decade old myth perpetuated by insufficient demonstrations/testing and belief in another more than 2 decade old myth known as "Best Practice" Index Maintenance.
For proof that both those issues are a myth and what the 2 simple fixes are, please see the following video and may close attention to everything including the section AFTER the Q'n'A because I also prove that GUIDs fix the insertion hot-spot, actually PREVENT fragmentation due to inserts and "ExpAnsive" updates and that you can go literally MONTHs with a regularly inserted Random GUID based Clustered Index with less than 1% logical fragmentation and no index maintenance for those same months. On large tables over time, that will be true for quarters and that the larger the table gets, the better all of that is.
AND, the lessons learned about GUIDs in the video, can be applied to other types of indexes, as well.
Here's the link. If you don't watch it, you'll just continue to suffer. 😀 😉
https://www.youtube.com/watch?v=rvZwMNJxqVo
Don't be sorry. Even I am learning through hard way. I don't feel bad about it.
Thanks a ton for providing inputs without judging people like me but still offering suggestions in whatever best possible way.
Yes, I know sometimes I may be asking some weird questions but I don't want to keep those in my mind. At least, in that way I come to know whether I am asking a good or bad question based on the responses. Pardon me.
People like me learn more from these type of forums and getting suggestions for the REAL WORLD issues. A BIG THANKS for these type of technical communities.
Sir, a followup question.
What is meant by knowing your workload.?
Does it mean , queries that we run on the server, maintenance jobs and other app jobs that we run on the server and knowing at what schedules what processes are running? Is my understanding correct?
-
Dammit. I know I typed up a long explanation this morning of what "WorkLoad" means and now it's gone. Maybe I forgot to hit SUBMIT or something. Whatever. 🙁 I don't have the time to rewrite so I'll summarize...
Like I said in my now missing previous explanation, "What is a 'WorkLoad'" is a great question.
When it pertains to database servers, a "WorkLoad" is anything and everything that makes demands on the server and how it affects network traffic at the NICs, how much CPU, Memory, I/O it uses (including things like writing to the transaction logs, how many page splits writes may be causing, etc, etc)..
More finite, it can also be interpreted as how it's using a table and the indexes.
A lot of people boil it down to "What are your queries doing?", which is a stupendous over-simplification of the term, IMHO, especially when it comes to trying to figure out what the "WorkLoads" are that affect any given table/index/etc. In such cases, people really mean "Total WorkLoad" affecting the given resource meaning any and all queries and actions that may affect the give resource.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Just to add my bit:
In the Query Store you my want to look at regressed quries. In fact look at your Query Store overall from many views,... I/O, cpu, running times.... and see if there common stored procedures among these.
Look at your stored procedures highlighted here .I would not be suprised if the stored procedures have a generic desing that involves 'branching'. Meaning >
If this.
Select form this table
If that
Select from this other table
If this again
Do some more stuff where by joining one set of tables and a table valued function
Do the same thing again for a slightly different where clause
.. and so on and so on
The bottom line, is that with complex logic in one procedure where there could be many paths about what 'tables/recordsets' get used... you are likely to find inconsistent query plans. Sometimes they will regress and that could be when you notice things.
----------------------------------------------------
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply