UTF8 and varchar lengths
-
Comments posted to this topic are about the item UTF8 and varchar lengths
WARNING: It appears SSC does not save
nvarchardata, and uses avarcharfor post body data, meaning the question is malformed. I can't post the character I used in a post here either, so here's a DB<>Fiddle with the actual character, where you can post characters out side of the standard code page.- This topic was modified 5 years, 8 months ago by .
- This topic was modified 5 years, 8 months ago by .
Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
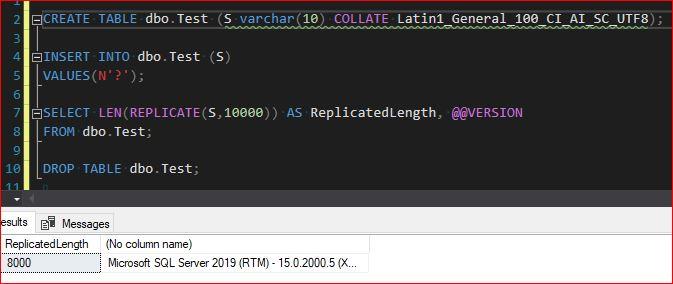
On my SQL 2019 instance, the behaviour does not match your explanation

-
Yep. I think this stems from the how the original character wasn't an actual question mark, but rather an extended character, which the font used to present the question couldn't reproduce.
Just because you're right doesn't mean everybody else is wrong. -
The result on my setup of SQL 2019 is also 8000, I have the same thought as Rune that the intended character is not the character in the question.
- DesNorton wrote:
On my SQL 2019 instance, the behaviour does not match your explanation
Yep the question I wrote doesn't have a question mark in it, it had a character that uses 3 bytes to be stored... Thanks SSC for making me look like an idiot and talking crazy...
Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
I've edited the initial post, nothing I can personally do about SSC's data choices unfortunately.
Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk -
Might be worth updating the question to use NCHAR to get the character. Code written in good old ASCII won't let you down 😉
DECLARE @val NCHAR = NCHAR(9688);
CREATE TABLE #Test (S varchar(10) COLLATE Latin1_General_100_CI_AI_SC_UTF8);
INSERT INTO #Test (S)
VALUES(@val);
SELECT LEN(REPLICATE(S,10000)) AS ReplicatedLength
FROM #Test; - Jon 0x7f800000 wrote:
Might be worth updating the question to use NCHAR to get the character. Code written in good old ASCII won't let you down 😉
True, though one would expect SSC to store data using an
nvarchar. I, unfortunately, can't edit it so I've emailed the WebMaster.Thom~
Excuse my typos and sometimes awful grammar. My fingers work faster than my brain does.
Larnu.uk - Thom A wrote:
True, though one would expect SSC to store data using an
nvarchar. I, unfortunately, can't edit it so I've emailed the WebMaster.Agreed. For what it's worth, I still enjoyed the question since I was glad my reasoning about the UTF8--VARCHAR interaction was correct. Encodings are a wild world!
-
Hi all. I have replied to Thom's forum post regarding storing data in
NVARCHAR. I mentioned in my reply that Unicode characters can be stored here, but that they need to be HTML-encoded since that sends only standard ASCII characters to the server (and if the article / post / question / etc is ever edited, all such characters need to be re-encoded else you will fall back into the original problem).Looking at the db<>fiddle, the character in question is: U+25D8
That can be stored here via: ◘
Which will stored as that encoded value, and sent to the browser like that, but displayed as the desired character: ◘
However, for the most stable / transportable representation (one that won't get altered either by a different encoding or being processed multiple times), you should have such characters generated at the server by using the
NCHAR()function (as Jon noted above). This goes for ALL non-standard ASCII characters (meaning: any character with a value above 127, or0x7Fin hex). For example:NCHAR(0x25D8). Please note that for Supplementary Characters, it's best to specify them in terms of surrogate pairs instead of their U+10000 through U+10FFFF scalar value (i.e. useNCHAR(0xD800) + NCHAR(0xDC00)instead ofNCHAR(0x10000)for that first value as the latter only works in DB's that have a default collation with_SCin the name).So, to recreate and expand on the original question, let's see if the following works:
CREATE TABLE dbo.Test (S VARCHAR(10) COLLATE Latin1_General_100_CI_AI_SC_UTF8);
DELETE FROM dbo.Test;
INSERT INTO dbo.Test (S)
VALUES (N'?'), -- 1 byte (standard ASCII)
(NCHAR(0x0102)), -- 2 bytes (Ă)
(NCHAR(0x25D8)), -- 3 bytes (◘)
(NCHAR(0xD83D) + NCHAR(0xDC30)); -- 4 bytes (🐰; all Supplementary characters)
SELECT S, LEN(REPLICATE(S,10000)) AS ReplicatedLength
FROM dbo.Test;For more details on UTF-8, please see my post:
Native UTF-8 Support in SQL Server 2019: Savior or False Prophet?
Take care,
Solomon...
SQL# — https://SQLsharp.com/ ( SQLCLR library ofover 340 Functions and Procedures)
Sql Quantum Lift — https://SqlQuantumLift.com/ ( company )
Sql Quantum Leap — https://SqlQuantumLeap.com/ ( blog )
Info sites — Collations • Module Signing • SQLCLR -
Just adding a little twist to the "shaky at the best" UTF-8 bodged support
😎
USE TEEST;
GO
SET NOCOUNT ON;
GO
CREATE TABLE dbo.Test (S varchar(10) COLLATE Latin1_General_100_CI_AI_SC_UTF8);
INSERT INTO dbo.Test (S)
VALUES(N'?');
SELECT LEN(REPLICATE(CONVERT(VARCHAR(MAX),S,0),100000)) AS ReplicatedLength
FROM dbo.Test;
SELECT REPLICATE(CONVERT(VARCHAR(MAX),S,0),100000) AS ReplicatedLength
FROM dbo.Test;
DROP TABLE dbo.Test;On SQL 2019, the results are 8000 and 65536 characters respectfully, starting to sound like some presidential election....
- Eirikur Eiriksson wrote:
On SQL 2019, the results are 8000 and 65536 characters respectfully, starting to sound like some presidential election....
What patch level are you using? I am testing your code on CU5 and the number for both rows is 100,000. It's possible (though I haven't seen such behavior myself) that something is amiss with the input parameter for the
LEN()function on a different CU ?However, for the 65,536 characters returned, that is simply an SSMS query option setting. Go to the Tools menu | Options | Query Results | SQL Server | Results to Grid | "Maximum Characters Retrieved" | "Non XML data" should be set higher than the default. I use "1000000".
Take care,
Solomon..
SQL# — https://SQLsharp.com/ ( SQLCLR library ofover 340 Functions and Procedures)
Sql Quantum Lift — https://SqlQuantumLift.com/ ( company )
Sql Quantum Leap — https://SqlQuantumLeap.com/ ( blog )
Info sites — Collations • Module Signing • SQLCLR - Solomon Rutzky wrote:Eirikur Eiriksson wrote:
On SQL 2019, the results are 8000 and 65536 characters respectfully, starting to sound like some presidential election....
What patch level are you using? I am testing your code on CU5 and the number for both rows is 100,000. It's possible (though I haven't seen such behavior myself) that something is amiss with the input parameter for the
LEN()function on a different CU ?However, for the 65,536 characters returned, that is simply an SSMS query option setting. Go to the Tools menu | Options | Query Results | SQL Server | Results to Grid | "Maximum Characters Retrieved" | "Non XML data" should be set higher than the default. I use "1000000".
Take care,
Solomon..
I realized the SSMS settings affecting the results as soon as I posted, got a fresh install on this laptop ("Vanilla") SQL Server Management Studio 15.0.18338.0
😎
The SQL Server is
Microsoft SQL Server 2019 (RTM-GDR) (KB4517790) - 15.0.2070.41 (X64) Oct 28 2019 19:56:59 Copyright (C) 2019 Microsoft Corporation Developer Edition (64-bit) on Windows 10 Pro 10.0 <X64> (Build 19041: )
-
He he, just changed the settings to 1000000 and still getting 65,536 characters returned
😎
- Eirikur Eiriksson wrote:
I realized the SSMS settings affecting the results as soon as I posted, got a fresh install on this laptop ("Vanilla") SQL Server Management Studio 15.0.18338.0
😎
The SQL Server is
Microsoft SQL Server 2019 (RTM-GDR) (KB4517790) - 15.0.2070.41 (X64) Oct 28 2019 19:56:59 Copyright (C) 2019 Microsoft Corporation Developer Edition (64-bit) on Windows 10 Pro 10.0 <X64> (Build 19041: )
Ok. I'm using nearly the same version of SSMS (18.7.1 == 15.0.18358.0). And, I downloaded a container to get the GDR patch-level:
Microsoft SQL Server 2019 (RTM-GDR) (KB4517790) - 15.0.2070.41 (X64)
Oct 28 2019 19:56:59
Copyright (C) 2019 Microsoft Corporation
Developer Edition (64-bit) on Linux (Ubuntu 16.04.6 LTS) <X64>
So, the SQL Server version is the same, only difference is running on Linux instead of Windows. I ran your test code and got back the expected 100,000. Not sure what is causing you to get back 8000. What is the DB's default collation?
Also, regarding changing the query result option to 1,000,000 but still getting back 65,536: that setting most likely only takes effect for new query windows, not existing ones.
Take care,
Solomon..
SQL# — https://SQLsharp.com/ ( SQLCLR library ofover 340 Functions and Procedures)
Sql Quantum Lift — https://SqlQuantumLift.com/ ( company )
Sql Quantum Leap — https://SqlQuantumLeap.com/ ( blog )
Info sites — Collations • Module Signing • SQLCLR
Viewing 15 posts - 1 through 15 (of 18 total)
You must be logged in to reply to this topic. Login to reply