Using ROW_NUMBER() to increment every time a value occurs
-
Hello folks,
I have some rather unstructured data coming into a staging column from a file. I can guarantee the order of the data on load using a column I am calling RowNumber. I like to group the data using ROW_NUMBER() every time the value 'CreateDate' occurs. Here is current my effort. Thanks if you can help.
DROP TABLE IF EXISTS #Test
CREATE TABLE #Test (RowNumber INT,RowType VARCHAR(10),DelimitedColumn VARCHAR(MAX))
--Should all have a GroupingIdentifier of 1
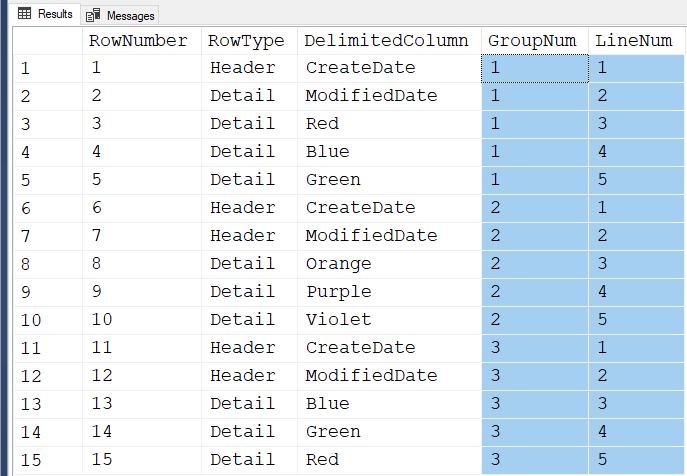
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (1,'Header','CreateDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (2,'Detail','ModifiedDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (3,'Detail','Red')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (4,'Detail','Blue')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (5,'Detail','Green')
--Should all have a GroupingIdentifier of 2
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (6,'Header','CreateDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (7,'Header','ModifiedDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (8,'Detail','Orange')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (9,'Detail','Purple')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (10,'Detail','Violet')
--Should all have a GroupingIdentifier of 3
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (11,'Header','CreateDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (12,'Header','ModifiedDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (13,'Detail','Blue')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (14,'Detail','Green')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (15,'Detail','Red')
SELECT
ROW_NUMBER() OVER (PARTITION BY DelimitedColumn,IIF(DelimitedColumn = 'CreateDate',1,0) ORDER BY RowNumber) AS GroupingIdentifier
,*
FROM #Test
ORDER BY RowNumber -
It would be easier if the first row were numbered "0" instead of 1 so that we could use modulo all by itself to do this but, it can still be done with a little math and no need for ROW_NUMBER(). Here's the code using your readily consumable data that you provided (and thank you for that!)... You've just gotta love "Integer Math" (Integer Division, in this case). If you've never used "Modulo" before, it returns the remainder of the division and the "%" operator is the "Modulo" operator in SQL Server. All the rest is "Integer Math".
SELECT *
,GroupNum = ((RowNumber-1)/5)+1 -- This is what I think you're asking for.
,LineNum = ((RowNumber-1)%5)+1 -- You didn't ask for this but included it.
FROM #Test
ORDER BY GroupNum,LineNum
;Results:

p.s. If you need to convert the groups to actual rows in a table, that would be an easy thing to do using a nice high performance CROSSTAB based on the GroupNum and LineNum columns we've just created.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks Jeff, Here is more realistic data. Won't work when there are more than 5 rows.
DROP TABLE IF EXISTS #Test
CREATE TABLE #Test (RowNumber INT,RowType VARCHAR(10),DelimitedColumn VARCHAR(MAX))
--Should all have a GroupingIdentifier of 1
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (1,'Header','CreateDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (2,'Detail','ModifiedDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (3,'Detail','Red')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (4,'Detail','Blue')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (5,'Detail','Green')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (6,'Detail','Black')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (7,'Detail','White')
--Should all have a GroupingIdentifier of 2
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (8,'Header','CreateDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (9,'Header','ModifiedDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (10,'Detail','Orange')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (11,'Detail','Purple')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (12,'Detail','Violet')
--Should all have a GroupingIdentifier of 3
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (13,'Header','CreateDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (14,'Header','ModifiedDate')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (15,'Detail','Blue')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (16,'Detail','Green')
INSERT INTO #Test (RowNumber,RowType,DelimitedColumn) VALUES (17,'Detail','Red') -
I have NOT uber-tuned this, just trying to get something that works (so many people here obsess over every microsecond). If you have a lot of rows, more tuning might be needed, of course (or perhaps not), but checking first to verify that your results are good:
;WITH cteCreateDates AS (
SELECT RowNumber, ROW_NUMBER() OVER(ORDER BY RowNumber) AS GroupingIdentifier,
ISNULL(LEAD(RowNumber) OVER(ORDER BY RowNumber), 2147483647) AS NextRowNumber
FROM #Test
WHERE DelimitedColumn = 'CreateDate'
)
SELECT t.*, cd.GroupingIdentifier
FROM #Test t
INNER JOIN cteCreateDates cd ON t.RowNumber BETWEEN cd.RowNumber AND cd.NextRowNumber
ORDER BY t.RowNumberSQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Thanks Scott. Definitely looks good initially.
The row count will be in the hundreds. Let me bounce this against my actual data and see if that brings up any complexities.
-
Actually getting some duplicate CreateDate rows in GroupingIdentifiers 2 and 3 using my sample data.
-
This should do it
ON t.RowNumber >= cd.RowNumber AND t.RowNumber < cd.NextRowNumber
Have a great weekend!
-
OOPS, quite right, I should have used ">=" and "<" rather than "BETWEEN".
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
so many people here obsess over every microsecond
It's frequently obvious when code is not written by such folks when the OP comes back in a few months saying that, while the code works, it's causing a performance problem. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Chrissy321 wrote:
Thanks Jeff, Here is more realistic data. Won't work when there are more than 5 rows.
Ah... My apologies, Chrissy. When you said you could "guarantee the order", I mistook that to also mean the 5 rows shown in all the groups in the test data. I should have asked.
Scott's code works a treat with one condition... if there are a lot of duplicate groups in the #Test table, an accidental Many-to-Many join forms and that causes his code to comparatively run very slow (about 10 times slower) and drive logical reads to to more than a quarter million in a small test of just 25000 rows where 5 groupings were duplicated.
The fix is wicked easy though... just make sure that you have a machine named clustered primary key on the Row_Number column and all of that goes away. It needs to be "machine named" because such constraints need to be named uniquely in the database. In tempdb, other people could be running the code and that would cause a concurrency problem if not left to the machine to name it.
@scott... Nicely done. A lot of folks would have gone with a WINDOWING function to create the groups and that causes an even more serious problem with READs whether there's a Clustered PK on the RowNumber column or not.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Just so people can play if they want, here's all the code I played with.
My findings are that if you can have a Clustered Index on the RowNumber column of the #Test table, and there aren't a lot of duplicate groupings, use Scott's method to keep the number of READs way down.
If you can't have a Clustered Index on the #Test table or there are a lot of duplicate groups, use the Windowing method to keep the CPU and duration down by a factor of 9 or 10.
-- SUMMARY: Groupings by a particular row content
-- https://www.sqlservercentral.com/forums/topic/using-row_number-to-increment-every-time-a-value-occurs
/**********************************************************************************************************************
The following is an expansion of the original problem but have had a 4th and 5th grouping added.
**********************************************************************************************************************/
DROP TABLE IF EXISTS #Test;
GO
CREATE TABLE #Test
(
RowNumber INT IDENTITY(1,1) PRIMARY KEY CLUSTERED --Not included in original but recommended.
,RowType VARCHAR(10)
,DelimitedColumn VARCHAR(MAX)
)
GO
--Should all have a GroupingIdentifier of 1 for answer
INSERT INTO #Test (RowType,DelimitedColumn)
VALUES
('Header','CreateDate')
,('Detail','ModifiedDate')
,('Detail','Red')
,('Detail','Blue')
,('Detail','Green')
,('Detail','Black')
,('Detail','White')
--Should all have a GroupingIdentifier of 2 for answer
,('Header','CreateDate')
,('Header','ModifiedDate')
,('Detail','Orange')
,('Detail','Purple')
,('Detail','Violet')
--Should all have a GroupingIdentifier of 3 for answer
,('Header','CreateDate')
,('Header','ModifiedDate')
,('Detail','Blue')
,('Detail','Green')
,('Detail','Red')
--Should all have a GroupingIdentifier of 4 for answer
,('Header','CreateDate')
,('Header','ModifiedDate')
,('Detail','Blue')
,('Detail','Green')
,('Detail','Red')
--Should all have a GroupingIdentifier of 5 for answer
,('Header','CreateDate')
,('Detail','ModifiedDate')
,('Detail','Red')
;
GO 1000 --This was not in the original. It duplicates the data 1000 times for some heft.
--It also shows a problem with Scott's code coming up and how to fix it later.
--===== This is just to get a read on the number of reads in the table above.
-- 100 Page Heap, 101 page Cluster Table.
SET STATISTICS TIME,IO ON;
SELECT * FROM #Test;
SET STATISTICS TIME,IO OFF;
-------------------------------------------------------------------------------
GO
--===== Scott's solution has an accidental Many-to-Many Join in it. ===================================================
-- For a small number of rows, it appears that it may be better than a pure windowing function
-- but it's not once things gets larger if there's no clustered index. Works great if there is.
-- Note that I redacted the code for readability and indentation.
DBCC FREEPROCCACHE;
GO
SET STATISTICS TIME,IO ON;
WITH
cteCreateDates AS
(
SELECT RowNumber
,GroupingIdentifier = ROW_NUMBER() OVER (ORDER BY RowNumber)
,NextRowNumber = ISNULL(LEAD(RowNumber) OVER (ORDER BY RowNumber), 2147483647)
FROM #Test
WHERE DelimitedColumn = 'CreateDate'
)
SELECT t.*
,cd.GroupingIdentifier
FROM #Test t
JOIN cteCreateDates cd ON t.RowNumber >= cd.RowNumber AND t.RowNumber < cd.NextRowNumber
ORDER BY t.RowNumber
;
SET STATISTICS TIME,IO OFF;
GO 3
--***** 1st Run Performance for Scott's code *****
--===== With HEAP...
--Table 'Worktable'. Scan count 25000, logical reads 241326
--Table '#Test. Scan count 14, logical reads 200
--SQL Server Execution Times:
-- CPU time = 12609 ms, elapsed time = 2423 ms.
--===== With CLUSTER...
--Table 'Worktable'. Scan count 0, logical reads 0
--Table '#Test. Scan count 5001, logical reads 10843
--SQL Server Execution Times:
-- CPU time = 31 ms, elapsed time = 268 ms.
--===== Windowing Method ==============================================================================================
DBCC FREEPROCCACHE;
GO
SET STATISTICS TIME,IO ON;
SELECT RowNumber
,RowType
,DelimitedColumn
,GroupingIdentifier = SUM(IIF(DelimitedColumn = 'Creat eDate', 1, 0)) OVER (ORDER BY RowNumber)-- ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROw)
FROM #Test
ORDER BY RowNumber;
SET STATISTICS TIME,IO OFF;
GO 3
--***** 1st Run Performance for Windowing method *****
--===== With HEAP...
--Table 'Worktable'. Scan count 25001, logical reads 151547
--Table '#Test. Scan count 13, logical reads 100
--SQL Server Execution Times:
-- CPU time = 407 ms, elapsed time = 341 ms.
--===== With CLUSTER...
--Table 'Worktable'. Scan count 25001, logical reads 151365 -- Bleah!!!
--Table '#Test. Scan count 5001, logical reads 102
--SQL Server Execution Times:
-- CPU time = 172 ms, elapsed time = 230 ms.
/**********************************************************************************************************************
The following is a huge expansion of the problem using randomized data and little possibility of duplicated groups.
**********************************************************************************************************************/
--===== Build and populate the table that holds the unique sample data for the RowType and DelimitedColumn.
DROP TABLE IF EXISTS #RowInfo;
GO
CREATE TABLE #RowInfo
(
InfoNumber INT --PRIMARY KEY CLUSTERED
,RowType VARCHAR(10) NOT NULL
,DelimitedColumn VARCHAR(MAX) NOT NULL
)
;
INSERT INTO #RowInfo
(InfoNumber, RowType, DelimitedColumn)
VALUES ( 1,'Header','CreateDate')
,( 2,'Detail','ModifiedDate')
,( 3,'Detail','Red')
,( 4,'Detail','Orange')
,( 5,'Detail','Yellow')
,( 6,'Detail','Green')
,( 7,'Detail','Blue')
,( 8,'Detail','Indigo')
,( 9,'Detail','Violet')
,(10,'Detail','Black')
,(11,'Detail','Grey')
,(12,'Detail','White')
;
GO
--===== Build an populate a table that holds many random numbers for 1 to 12
-- to randomly distribute the unique rows above more than one time.
DROP TABLE IF EXISTS #InfoNumberRand;
GO
SELECT TOP (25000-1)
InfoNumberRand = ABS(CHECKSUM(NEWID())%12)+1
INTO #InfoNumberRand
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
OPTION (MAXDOP 0)
;
GO
--===== Create and populate the large #Test table by joining the two tables above.
DROP TABLE IF EXISTS #Test;
GO
CREATE TABLE #Test
(
RowNumber INT IDENTITY(1,1) --PRIMARY KEY CLUSTERED
,RowType VARCHAR(10) NOT NULL
,DelimitedColumn VARCHAR(MAX) NOT NULL
)
GO
INSERT INTO #Test WITH (TABLOCK)
(RowType, DelimitedColumn)
SELECT RowType = 'Header', DelimitedColumn = 'CreateDate'
UNION ALL
SELECT info.RowType, info.DelimitedColumn
FROM #InfoNumberRand rnd
JOIN #RowInfo info
ON rnd.InfoNumberRand = info.InfoNumber
OPTION (MAXDOP 1) --Seriously increases the performance.
;
GO
SELECT * FROM #Test
ORDER BY RowNumber
;
---------------------------------------------------------------
--===== Scott's solution has an accidental Many-to-Many Join (3*17 here) in it. =======================================
-- For a small number of rows, it appears that it may be better than a pure windowing function
-- but it's not once things gets larger.
DBCC FREEPROCCACHE;
SET STATISTICS TIME,IO ON;
WITH
cteCreateDates AS
(
SELECT RowNumber
,GroupingIdentifier = ROW_NUMBER() OVER (ORDER BY RowNumber)
,NextRowNumber = ISNULL(LEAD(RowNumber) OVER (ORDER BY RowNumber), 2147483647)
FROM #Test
WHERE DelimitedColumn = 'CreateDate'
)
SELECT t.*
,cd.GroupingIdentifier
FROM #Test t
JOIN cteCreateDates cd ON t.RowNumber >= cd.RowNumber AND t.RowNumber < cd.NextRowNumber
ORDER BY t.RowNumber
OPTION (MAXDOP 0)
;
SET STATISTICS TIME,IO OFF
;
GO 3
--===== With HEAP...
--Table 'Worktable'. Scan count 25000, logical reads 120064
--Table '#Test. Scan count 14, logical reads 192
--SQL Server Execution Times:
-- CPU time = 3798 ms, elapsed time = 1982 ms.
--===== With CLUSTER...
--Table 'Worktable'. Scan count 0 , logical reads 0
--Table '#Test. Scan count 2148 , logical reads 4773
--SQL Server Execution Times:
-- CPU time = 31 ms, elapsed time = 252 ms.
--===== Windowing Method ==============================================================================================
DBCC FREEPROCCACHE
SET STATISTICS TIME,IO ON;
SELECT RowNumber
,RowType
,DelimitedColumn
,GroupingIdentifier = SUM(IIF(DelimitedColumn = 'CreateDate', 1, 0)) OVER (ORDER BY RowNumber)
FROM #Test
ORDER BY RowNumber
OPTION (MAXDOP 0)
;
SET STATISTICS TIME,IO OFF;
;
GO 3
--===== With HEAP...
--Table 'Worktable'. Scan count 25001, logical reads 151344
--Table '#Test. Scan count 13, logical reads 96
--SQL Server Execution Times:
-- CPU time = 375 ms, elapsed time = 362 ms.
--===== With CLUSTER...
--Table 'Worktable'. Scan count 25001, logical reads 151344
--Table '#Test. Scan count 1, logical reads 98
--SQL Server Execution Times:
-- CPU time = 156 ms, elapsed time = 275 ms.
GO--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply