Using LAG to return prior non null value
-
Crud... just not having a good week here. I just found a bug in my code and had to take it down. 🙁
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. I'm thinking that the LAST_VALUE and FIRST_VALUE functions may be a better choice here. I'll give that a try.
EDIT: I just tried them... Prior to SQL Server 2022, LAST_VALUE and FIRST_VALUE don't work correctly even using the CROSS APPLY that Drew used. They remind me of how things like SUM() OVER didn't work to create running totals when it first hit the streets until 2012 came out.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Ok... I believe I've got it this time. To summarize, the code solves the problem of NULLs being returned in the "Lag'n'Lead" columns if there is data outside of the desired date-reporting range to pull from. It also solves the problem of a single date where there is no data in the given data for that date.
Code Dependency
To commence, I'll advise you that I use the fnTally function (a simple numeric sequence generator that substitutes a Tally Table) in parts of the code. You can get fnTally from the article at the similarly named link in my signature line at the bottom of this post or you can substitute one of your own.
Calendar Table
I needed a much larger Calendar Table than what was originally provided by the OP. Like Drew Allen did, I've converted all work to occur in TempDB so that we don't overwrite any real tables by accident. Here's the code for the #Calendar table that I used.
This table is appropriately indexed.
--=====================================================================================================================
-- Create a Calendar Table.
-- Obviously, this isn't a full table. It's just for demo and so only contains a "CalendarDate" column.
--=====================================================================================================================
--===== If the table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS #Calendar;
GO
--===== Create the table with the expected Clustered PK.
CREATE TABLE #Calendar
(CalendarDate DATE NOT NULL PRIMARY KEY CLUSTERED)
;
--===== Insert all dates for the 20th and 21st Century for realism.
-- Includes all dates from 1900-01-01 up to and including 2100-01-01.
INSERT INTO #Calendar WITH (TABLOCK)
SELECT CalendarDate = DATEADD(dd,t.N,'1900')
FROM dbo.fnTally(0,DATEDIFF(dd,'1900','2100'))t
;
/*
--===== Show what we've got.
SELECT *
FROM #Calendar
ORDER BY CalendarDate
;
*/GOTest Data
Up next, I wanted the flexibility to generate a lot more test data in a less than a heartbeat. The following creates the data in #MyDate like most of the posts have been doing. Details are in the comments but, just to say it, it creates data for ID = 1 and ID =2. The data for ID=1 is not missing any dates and is used as a "control case". The data for ID = 2 is identical except for the "random" test that I also did.
A small change to the code is documented for ever-increasing values, ever-decreasing values, and "random" values. The code is preset to generate ever-increasing values similar to the original post. Since we're using MIN and MAX, it's also important to test for both.
Here's that code and, yes, it has also been indexed.
--=====================================================================================================================
-- Create and populate a test table.
-- Creates two IDs (whatever they are) with identical data and then "wounds" ID = 2 by deleting rows.
--=====================================================================================================================
--===== If the table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS #MyData;
GO
--===== Create the data table with the expected Clustered PK
-- and possible Non-Clustered Covering Index.
CREATE TABLE #MyData
(
ID INT NOT NULL
,ReportDate DATE NOT NULL
,ReportValue INT NOT NULL
,PRIMARY KEY CLUSTERED (ReportDate,ID)
,INDEX Cover01 (ID,ReportDate,ReportValue)
)
;
--===== Populate the table with more than 1 ID and identical data for the non-random test.
-- Note the three possibilities for testing based on ReportValue.
-- It's absolutely necessary to test all 3 because we're using MIN and MAX.
-- For those that are curious, CRYPT_GEN_RANDOM will not generate negative numbers.
INSERT INTO #MyData WITH (TABLOCK)
SELECT ID = ca1.ID
,ReportDate = DATEADD(dd,t.N,'01 Jun 2022')
,ReportValue = t.N+70 --Test Increasing Order
--,ReportValue = 300-(t.N+70) --Test Decreasing Order
--,ReportValue = CHECKSUM(NEWID())%1001 --Random -1000 to 1000 possible
FROM dbo.fnTally(0,DATEDIFF(dd,'01 Jun 2022','01 Sep 2022'))t
CROSS APPLY (VALUES (1),(2))ca1(ID)
;
--===== "Wound" the data for ID = 2 to make "gaps" in the data.
DELETE FROM #MyData
WHERE ID = 2
AND ReportDate IN
(
'2022-07-02'
,'2022-07-03'
,'2022-07-04'
-------------
,'2022-07-09'
,'2022-07-10'
-------------
,'2022-07-16'
,'2022-07-17'
-------------
,'2022-07-23'
,'2022-07-24'
-------------
,'2022-07-30'
,'2022-07-31'
)
;
/*
SELECT *
FROM #MyData
WHERE Reportdate >= '01 Jul 2022'
AND Reportdate < '01 Aug 2022'
ORDER BY ID,ReportDate
;
*/GOProposed Solution
And now the solution code. In order to handle more than one ID at a time, the key lays in how we use the #Calendar table. To be brief, it finds all possible IDs in the desired range and generates an "in-flight" calendar "table" (as a CTE) that contains a mini-calendar table containing the CalendarDate AND the found ID for each ID.
From there and to further summarize, it uses the method that Drew Allen posted in his very first post on this thread. My mistake that caused me to take my previously posted code down was that I thought I found a shortcut so we wouldn't need to use the CROSS APPLY that he did. That worked find for ever-increasing values but crashed and burned for ever-decreasing values, which proved it was bad code. I added a similar CROSS APPLY and everything is fine now.
The rest of the details are in the comments in the code but, I will pause to tell you again, this solves for missing data at the start and end of the desired date range and solves for single dates (start date = end date) that may also be missing from the data.
One final word is that you can combine this code with the other two pieces of code above and be executed all together (makes testing real easy) provided that they are executed in the order presented on this post.
Drew... thanks a million again for the code you posted and the Itzik Ben-Gan article on the subject. The use of CROSS APPLY, as you did in your original code, is essential for handling multiple columns without serious repetition of code. Nicely done!
--=====================================================================================================================
-- Solution for all the requirements I am currently aware of.
-- Jeff Moden - Rev Eleventy-Bazillion :D - 14 Aug 2022
-- References:
--===== Itzik Ben-Gan's solution article referred to by Drew Allen.
-- https://www.itprotoday.com/sql-server/last-non-null-puzzle
--===== Drew Allen's post that introduced us to the Itzik Ben-Gans artical.
-- https://www.sqlservercentral.com/forums/topic/using-lag-to-return-prior-non-null-value#post-4072582
--=====================================================================================================================
--===== Define the range of dates the report is based on.
-- Note that is based on the assumption that there are no times in the source data. WHOLE date only!!
-- Also note that the @ExtendDays extends the search range before the @ReportStart and after the @ReportEnd
-- to solve the problems of start or ending on days where data doesn't exist and also solves the problem of
-- a single day lookup for a date with no data.
--===== This example has start and end sdates that don't exist
DECLARE @ReportStart DATE = '2022-07-02'
,@ReportEnd DATE = '2022-07-10'
,@ExtendDays INT = 30
;
----===== This example is for a single day lookup where no data exists.
-- -- Comment the above DECLARE out and uncomment this one to test.
--DECLARE @ReportStart DATE = '2022-07-03'
-- ,@ReportEnd DATE = '2022-07-03'
-- ,@ExtendDays INT = 30
--;
SET STATISTICS TIME,IO ON;
WITH cteIDs AS
(--==== Finds all the UNIQUE IDs for the given reporting period
-- Remove the WHERE if you want to report NULL's for IDs not in the reporting period
SELECT dspyID = d.ID
FROM #MyData d
WHERE d.ReportDate >= DATEADD(dd,-@ExtendDays ,@ReportStart)
AND d.ReportDate < DATEADD(dd,@ExtendDays+1,@ReportEnd)
GROUP BY d.ID
)
,cteDatedIDs AS
(--==== Generates a calendar for each ID and includes the ID with no missing dates. Saves a "smear" in the process.
-- ***** NOTE THAT THIS METHOD REQUIRES THE PRESENCE OF AN ACTUAL INDEXED CALENDAR TABLE. *****
-- The DATEADDs extend the search range to @ExtendDays before the start of the desired range and
-- @ExtendDays days after the desired range. This picks up "smear" values that aren't in the desired range.
SELECT i.dspyID
,c.CalendarDate
FROM #Calendar c
CROSS JOIN cteIDs i
WHERE c.CalendarDate >= DATEADD(dd,-@ExtendDays ,@ReportStart)
AND c.CalendarDate < DATEADD(dd, @ExtendDays+1,@ReportEnd)
)
,cteSmear AS
(--==== This does the "smears".
-- Read the comments for TOP and ORDER BY force materialization of data using a "Blocking Operator".
-- This contains the trick that Drew showed us based on an article that Itzik Ben-Gan wrote.
-- In this case, the OUTER APPLY provides much fewer "Work Table" reads than a CROSS APPLY does.
-- The RowNum is just to make it easy to identify a given row during discussion and may be removed.
-- Apologies for the long code lines. They're just easier to read and compare that way.
SELECT TOP 3000000000 --This top is necessary to do the ORDER BY. Easy to remember big number of 3 follwed by 9 zeros.
RowNum = ROW_NUMBER() OVER (ORDER BY dtid.dspyID,dtid.CalendarDate)
,ID = dtid.dspyID
,CalendarDate = dtid.CalendarDate
,ReportedValue = mdat.ReportValue
,LastReportedDate = CONVERT(DATE,SUBSTRING(MAX(v.Val) OVER (PARTITION BY dtid.dspyID ORDER BY dtid.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING),11,10))
,LastReportedValue = CONVERT(INT ,SUBSTRING(MAX(v.Val) OVER (PARTITION BY dtid.dspyID ORDER BY dtid.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING),21,10))
,NextReportedDate = CONVERT(DATE,SUBSTRING(MIN(v.Val) OVER (PARTITION BY dtid.dspyID ORDER BY dtid.CalendarDate ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING),11,10))
,NextReportedValue = CONVERT(INT ,SUBSTRING(MIN(v.Val) OVER (PARTITION BY dtid.dspyID ORDER BY dtid.CalendarDate ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING),21,10))
FROM cteDatedIDs dtid
LEFT JOIN #MyData mdat
ON mdat.ID = dtid.dspyID
AND mdat.ReportDate = dtid.CalendarDate
OUTER APPLY (VALUES(CONVERT(CHAR(10),dtid.dspyID) + CONVERT(CHAR(10),dtid.CalendarDate) + CONVERT(CHAR(10),mdat.ReportValue)))v(Val)
ORDER BY dtid.dspyID,dtid.CalendarDate --This ORDER BY is a "Blocking Operator" that forces the data to materialize
--to find "LAGs'n'LEADs" outside of the desired range.
)--==== And now we return just the data from inside the desired range of dates.
-- 1. If rows exist within the @ExtendedDays range outside the Desired Range,
-- there will be no NULL values in the Desired Range.
-- 2. If we had done the WHERE in the cteSmear, we'd have ended up with NULL "LAGs'n'LEADs" in this desired range.
-- Instead, this also solves the problem of a single date (like 2022-07-03) that doesn't exist in the original data.
SELECT *
FROM cteSmear
WHERE CalendarDate >= @ReportStart
AND CalendarDate <= @ReportEnd
--WHERE dspyID = 2 --Just for testing/verification
ORDER BY ID,CalendarDate
SET STATISTICS TIME,IO OFF;
GOResults
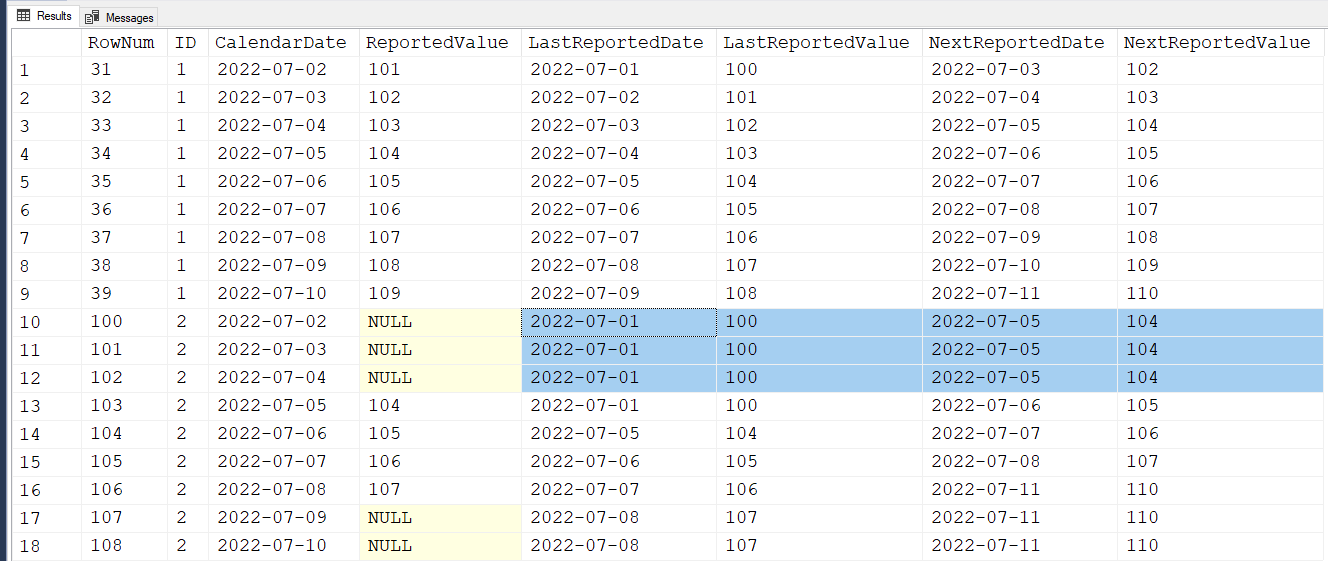
Here are the results if you run the code without making any changes. I've highlighted some of the rows to show that, even though there was no data (Reported Value) on those dates, we still have the Previous and Next ("Lag'n'Lead") data because there was data outside of the desired range that it picked up on (you see how that was done by reading the comments in the code).

Thank You!
I can't speak for anyone else but I learned a whole bunch of stuff from a lot of people and "phingering stuff out" by participating on this thread. Chrissy, thanks for the great question. Drew, thanks again for the great code introduction. And thanks to everyone else that posted. This ol' dude really appreciates it. It's a part of what makes this community so very valuable.
Performance Stats
Oh... almost forgot... there are the stats that got printed when I ran all 3 pieces as a single unit to get the results above.
(73050 rows affected)
(186 rows affected)
(11 rows affected)
SQL Server parse and compile time:
CPU time = 15 ms, elapsed time = 19 ms.
Warning: Null value is eliminated by an aggregate or other SET operation.
(18 rows affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table '#Calendar___________________________________________________________________________________________________________000000000168'.
Scan count 2, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table '#MyData_____________________________________________________________________________________________________________000000000169'.
Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.The indexes I added to each table are, indeed, important!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks Jeff this looks fantastic! I truly appreciate the time you took to put this together.
I am having some issues converting to my actual data structure. Apologies, I need to obfuscate my data but I should be doing a much better job of representing the actual scenario.
I have added ID2 (SMALLINT) to the key. I changed ReportValue to DECIMAL(38,10).
I updated the CTEs to the best of my understanding but I can not run with any errors.
If you or someone else who understands the code better could throw an eye on it that would be appreciated. Meanwhile I will continue troubleshooting. Thanks again.
CREATE OR ALTER FUNCTION [dbo].[fnTally]
/**********************************************************************************************************************
Purpose:
Return a column of BIGINTs from @ZeroOrOne up to and including @MaxN with a max value of 10 Quadrillion.
Usage:
--===== Syntax example
SELECT t.N
FROM dbo.fnTally(@ZeroOrOne,@MaxN) t
;
@ZeroOrOne will internally conver to a 1 for any number other than 0 and a 0 for a 0.
@MaxN has an operational domain from 0 to 4,294,967,296. Silent truncation occurs for larger numbers.
Please see the following notes for other important information
Notes:
1. This code works for SQL Server 2008 and up.
2. Based on Itzik Ben-Gan's cascading CTE (cCTE) method for creating a "readless" Tally Table source of BIGINTs.
Refer to the following URL for how it works.
https://www.itprotoday.com/sql-server/virtual-auxiliary-table-numbers
3. To start a sequence at 0, @ZeroOrOne must be 0. Any other value that's convertable to the BIT data-type
will cause the sequence to start at 1.
4. If @ZeroOrOne = 1 and @MaxN = 0, no rows will be returned.
5. If @MaxN is negative or NULL, a "TOP" error will be returned.
6. @MaxN must be a positive number from >= the value of @ZeroOrOne up to and including 4,294,967,296. If a larger
number is used, the function will silently truncate after that max. If you actually need a sequence with that many
or more values, you should consider using a different tool. ;-)
7. There will be a substantial reduction in performance if "N" is sorted in descending order. If a descending sort is
required, use code similar to the following. Performance will decrease by about 27% but it's still very fast
especially compared with just doing a simple descending sort on "N", which is about 20 times slower.
If @ZeroOrOne is a 0, in this case, remove the "+1" from the code.
DECLARE @MaxN BIGINT;
SELECT @MaxN = 1000;
SELECT DescendingN = @MaxN-N+1
FROM dbo.fnTally(1,@MaxN);
8. There is no performance penalty for sorting "N" in ascending order because the output is implicity sorted by
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
9. This will return 1-10,000,000 to a bit-bucket variable in about 986ms.
This will return 0-10,000,000 to a bit-bucket variable in about 1091ms.
This will return 1-4,294,967,296 to a bit-bucket variable in about 9:12( mi:ss).
Revision History:
Rev 00 - Unknown - Jeff Moden
- Initial creation with error handling for @MaxN.
Rev 01 - 09 Feb 2013 - Jeff Moden
- Modified to start at 0 or 1.
Rev 02 - 16 May 2013 - Jeff Moden
- Removed error handling for @MaxN because of exceptional cases.
Rev 03 - 07 Sep 2013 - Jeff Moden
- Change the max for @MaxN from 10 Billion to 10 Quadrillion to support an experiment.
This will also make it much more difficult for someone to actually get silent truncation in the future.
Rev 04 - 04 Aug 2019 - Jeff Moden
- Enhance performance by making the first CTE provide 256 values instead of 10, which limits the number of
CrossJoins to just 2. Notice that this changes the maximum range of values to "just" 4,294,967,296, which
is the entire range for INT and just happens to be an even power of 256. Because of the use of the VALUES
clause, this code is "only" compatible with SQLServer 2008 and above.
- Update old link from "SQLMag" to "ITPro". Same famous original article, just a different link because they
changed the name of the company (twice, actually).
- Update the flower box notes with the other changes.
**********************************************************************************************************************/ (@ZeroOrOne BIT, @MaxN BIGINT)
RETURNS TABLE WITH SCHEMABINDING AS
RETURN WITH
H2(N) AS ( SELECT 1
FROM (VALUES
(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)
)V(N)) --16^2 or 256 rows
, H4(N) AS (SELECT 1 FROM H2 a, H2 b) --16^4 or 65,536 rows
, H8(N) AS (SELECT 1 FROM H4 a, H4 b) --16^8 or 4,294,967,296 rows
SELECT N = 0 WHERE @ZeroOrOne = 0 UNION ALL
SELECT TOP(@MaxN)
N = ROW_NUMBER() OVER (ORDER BY N)
FROM H8
;
GO
--=====================================================================================================================
-- Create a Calendar Table.
-- Obviously, this isn't a full table. It's just for demo and so only contains a "CalendarDate" column.
--=====================================================================================================================
--===== If the table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS #Calendar;
GO
--===== Create the table with the expected Clustered PK.
CREATE TABLE #Calendar
(CalendarDate DATE NOT NULL PRIMARY KEY CLUSTERED)
;
--===== Insert all dates for the 20th and 21st Century for realism.
-- Includes all dates from 1900-01-01 up to and including 2100-01-01.
INSERT INTO #Calendar WITH (TABLOCK)
SELECT CalendarDate = DATEADD(dd,t.N,'1900')
FROM dbo.fnTally(0,DATEDIFF(dd,'1900','2100'))t
;
/*
--===== Show what we've got.
SELECT *
FROM #Calendar
ORDER BY CalendarDate
;
*/GO
--=====================================================================================================================
-- Create and populate a test table.
-- Creates two IDs (whatever they are) with identical data and then "wounds" ID = 2 by deleting rows.
--=====================================================================================================================
--===== If the table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS #MyData;
GO
--===== Create the data table with the expected Clustered PK
-- and possible Non-Clustered Covering Index.
CREATE TABLE #MyData
(
ID INT NOT NULL
,ID2SMALLINT NOT NULL
,ReportDate DATE NOT NULL
,ReportValue DECIMAL(38,10) NOT NULL
,PRIMARY KEY CLUSTERED (ReportDate,ID,ID2)
,INDEX Cover01 (ID,ID2,ReportDate,ReportValue)
)
;
--===== Populate the table with more than 1 ID and identical data for the non-random test.
-- Note the three possibilities for testing based on ReportValue.
-- It's absolutely necessary to test all 3 because we're using MIN and MAX.
-- For those that are curious, CRYPT_GEN_RANDOM will not generate negative numbers.
INSERT INTO #MyData WITH (TABLOCK)
SELECT ID = ca1.ID
,1 AS ID2
,ReportDate = DATEADD(dd,t.N,'01 Jun 2022')
,ReportValue = t.N+70 --Test Increasing Order
--,ReportValue = 300-(t.N+70) --Test Decreasing Order
--,ReportValue = CHECKSUM(NEWID())%1001 --Random -1000 to 1000 possible
FROM dbo.fnTally(0,DATEDIFF(dd,'01 Jun 2022','01 Sep 2022'))t
CROSS APPLY (VALUES (1),(2))ca1(ID)
;
--===== "Wound" the data for ID = 2 to make "gaps" in the data.
DELETE FROM #MyData
WHERE ID = 2
AND ReportDate IN
(
'2022-07-02'
,'2022-07-03'
,'2022-07-04'
-------------
,'2022-07-09'
,'2022-07-10'
-------------
,'2022-07-16'
,'2022-07-17'
-------------
,'2022-07-23'
,'2022-07-24'
-------------
,'2022-07-30'
,'2022-07-31'
)
;
INSERT INTO #MyData
SELECT ID,
ID2 + 1000,
ReportDate,
ReportValue + 1000
FROM #MyData
/*
SELECT *
FROM #MyData
WHERE Reportdate >= '01 Jul 2022'
AND Reportdate < '01 Aug 2022'
ORDER BY ID,ReportDate
;
*/GO
--=====================================================================================================================
-- Solution for all the requirements I am currently aware of.
-- Jeff Moden - Rev Eleventy-Bazillion :D - 14 Aug 2022
-- References:
--===== Itzik Ben-Gan's solution article referred to by Drew Allen.
-- https://www.itprotoday.com/sql-server/last-non-null-puzzle
--===== Drew Allen's post that introduced us to the Itzik Ben-Gans artical.
-- https://www.sqlservercentral.com/forums/topic/using-lag-to-return-prior-non-null-value#post-4072582
--=====================================================================================================================
--===== Define the range of dates the report is based on.
-- Note that is based on the assumption that there are no times in the source data. WHOLE date only!!
-- Also note that the @ExtendDays extends the search range before the @ReportStart and after the @ReportEnd
-- to solve the problems of start or ending on days where data doesn't exist and also solves the problem of
-- a single day lookup for a date with no data.
--===== This example has start and end sdates that don't exist
DECLARE @ReportStart DATE = '2022-07-02'
,@ReportEnd DATE = '2022-07-10'
,@ExtendDays INT = 30
;
----===== This example is for a single day lookup where no data exists.
-- -- Comment the above DECLARE out and uncomment this one to test.
--DECLARE @ReportStart DATE = '2022-07-03'
-- ,@ReportEnd DATE = '2022-07-03'
-- ,@ExtendDays INT = 30
--;
SET STATISTICS TIME,IO ON;
WITH cteIDs AS
(--==== Finds all the UNIQUE IDs for the given reporting period
-- Remove the WHERE if you want to report NULL's for IDs not in the reporting period
SELECT dspyID = d.ID,dspyID2 = d.ID2
FROM #MyData d
WHERE d.ReportDate >= DATEADD(dd,-@ExtendDays ,@ReportStart)
AND d.ReportDate < DATEADD(dd,@ExtendDays+1,@ReportEnd)
GROUP BY d.ID,d.ID2
)
,cteDatedIDs AS
(--==== Generates a calendar for each ID and includes the ID with no missing dates. Saves a "smear" in the process.
-- ***** NOTE THAT THIS METHOD REQUIRES THE PRESENCE OF AN ACTUAL INDEXED CALENDAR TABLE. *****
-- The DATEADDs extend the search range to @ExtendDays before the start of the desired range and
-- @ExtendDays days after the desired range. This picks up "smear" values that aren't in the desired range.
SELECT i.dspyID,i.dspyID2
,c.CalendarDate
FROM #Calendar c
CROSS JOIN cteIDs i
WHERE c.CalendarDate >= DATEADD(dd,-@ExtendDays ,@ReportStart)
AND c.CalendarDate < DATEADD(dd, @ExtendDays+1,@ReportEnd)
)
,cteSmear AS
(--==== This does the "smears".
-- Read the comments for TOP and ORDER BY force materialization of data using a "Blocking Operator".
-- This contains the trick that Drew showed us based on an article that Itzik Ben-Gan wrote.
-- In this case, the OUTER APPLY provides much fewer "Work Table" reads than a CROSS APPLY does.
-- The RowNum is just to make it easy to identify a given row during discussion and may be removed.
-- Apologies for the long code lines. They're just easier to read and compare that way.
SELECT TOP 3000000000 --This top is necessary to do the ORDER BY. Easy to remember big number of 3 follwed by 9 zeros.
RowNum = ROW_NUMBER() OVER (ORDER BY dtid.dspyID,dtid.dspyID2,dtid.CalendarDate)
,ID = dtid.dspyID
,ID2 = dtid.dspyID2
,CalendarDate = dtid.CalendarDate
,ReportedValue = mdat.ReportValue
,LastReportedDate = CONVERT(DATE,SUBSTRING(MAX(v.Val) OVER (PARTITION BY dtid.dspyID,dtid.dspyID2 ORDER BY dtid.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING),11,10))
,LastReportedValue = CONVERT(INT ,SUBSTRING(MAX(v.Val) OVER (PARTITION BY dtid.dspyID,dtid.dspyID2 ORDER BY dtid.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING),21,10))
,NextReportedDate = CONVERT(DATE,SUBSTRING(MIN(v.Val) OVER (PARTITION BY dtid.dspyID,dtid.dspyID2 ORDER BY dtid.CalendarDate ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING),11,10))
,NextReportedValue = CONVERT(INT ,SUBSTRING(MIN(v.Val) OVER (PARTITION BY dtid.dspyID,dtid.dspyID2 ORDER BY dtid.CalendarDate ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING),21,10))
FROM cteDatedIDs dtid
LEFT JOIN #MyData mdat
ON mdat.ID = dtid.dspyID
AND mdat.ID2 = dtid.dspyID2
AND mdat.ReportDate = dtid.CalendarDate
OUTER APPLY (VALUES(CONVERT(CHAR(10),dtid.dspyID) +CONVERT(CHAR(5),dtid.dspyID2) + CONVERT(CHAR(10),dtid.CalendarDate) + CONVERT(CHAR(38),mdat.ReportValue)))v(Val)
ORDER BY dtid.dspyID,dtid.dspyID2,dtid.CalendarDate --This ORDER BY is a "Blocking Operator" that forces the data to materialize
--to find "LAGs'n'LEADs" outside of the desired range.
)--==== And now we return just the data from inside the desired range of dates.
-- 1. If rows exist within the @ExtendedDays range outside the Desired Range,
-- there will be no NULL values in the Desired Range.
-- 2. If we had done the WHERE in the cteSmear, we'd have ended up with NULL "LAGs'n'LEADs" in this desired range.
-- Instead, this also solves the problem of a single date (like 2022-07-03) that doesn't exist in the original data.
SELECT *
FROM cteSmear
WHERE CalendarDate >= @ReportStart
AND CalendarDate <= @ReportEnd
--WHERE dspyID = 2 --Just for testing/verification
ORDER BY ID,CalendarDate
SET STATISTICS TIME,IO OFF;
GO - Chrissy321 wrote:
Thanks Jeff this looks fantastic! I truly appreciate the time you took to put this together.
I updated the CTEs to the best of my understanding but I can not run with any errors.
You're welcome but it's probably not going to be possible for anyone to troubleshoot any errors you may be having because you've not posted the actual errors.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Conversion failed when converting date and/or time from character string.
The modified script I posted updates the data structure and will generate the error when run.
-
You added "columns" to the CROSS APPLY and changed the width of some but you didn't change the substring values that look like this...
,11,10)
,21,10)
,11,10)
,21,10)--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
@Chrissy321...
Did that last hint help you succeed?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
@Chrissy321...
Did that last hint help you succeed?
I am moving ahead with technical review/testing of code based on what you provided so yes. Thanks. When I have a bit more time I do expect to follow up with with questions on how the code works. I also want to propose an enhancement that replaces @ExtendDays with specific dates.
-
Thank you for the feedback. And no problem on additional questions.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Following up.
My questions where really about the use of the SUBSTRING parameters start and length but after your hint and a little further study the use has become clear to me. They are needed to extract the correct data from the CROSS APPLY. In the following example I added the new field to the end of the CROSS APPLY such that changes were not required to the SUBSTRING parameters.
In the new script below I added @SmearStart parameter which I hope will allow more dynamic filtering of how far back it is necessary to to get the data that is 'smeared' forward.
Feedback of course welcome.
--=====================================================================================================================
-- Create a Calendar Table.
-- Obviously, this isn't a full table. It's just for demo and so only contains a "CalendarDate" column.
--=====================================================================================================================
--===== If the table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS #Calendar;
GO
--===== Create the table with the expected Clustered PK.
CREATE TABLE #Calendar
(CalendarDate DATE NOT NULL PRIMARY KEY CLUSTERED)
;
--===== Insert all dates for the 20th and 21st Century for realism.
-- Includes all dates from 1900-01-01 up to and including 2100-01-01.
INSERT INTO #Calendar WITH (TABLOCK)
SELECT CalendarDate = DATEADD(dd,t.N,'1900')
FROM dbo.fnTally(0,DATEDIFF(dd,'1900','2100'))t
;
/*
--===== Show what we've got.
SELECT *
FROM #Calendar
ORDER BY CalendarDate
;
*/GO
--=====================================================================================================================
-- Create and populate a test table.
-- Creates two IDs (whatever they are) with identical data and then "wounds" ID = 2 by deleting rows.
--=====================================================================================================================
--===== If the table exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS #MyData;
GO
--===== Create the data table with the expected Clustered PK
-- and possible Non-Clustered Covering Index.
CREATE TABLE #MyData
(
ID INT NOT NULL
,ID2 SMALLINT NOT NULL
,ReportDate DATE NOT NULL
,ReportValue DECIMAL(38,10) NOT NULL
,PRIMARY KEY CLUSTERED (ReportDate,ID,ID2)
,INDEX Cover01 (ID,ID2,ReportDate,ReportValue)
)
;
--===== Populate the table with more than 1 ID and identical data for the non-random test.
-- Note the three possibilities for testing based on ReportValue.
-- It's absolutely necessary to test all 3 because we're using MIN and MAX.
-- For those that are curious, CRYPT_GEN_RANDOM will not generate negative numbers.
INSERT INTO #MyData WITH (TABLOCK)
SELECT ID = ca1.ID
,1 AS ID2
,ReportDate = DATEADD(dd,t.N,'01 Jun 2022')
,ReportValue = t.N+70 --Test Increasing Order
--,ReportValue = 300-(t.N+70) --Test Decreasing Order
--,ReportValue = CHECKSUM(NEWID())%1001 --Random -1000 to 1000 possible
FROM dbo.fnTally(0,DATEDIFF(dd,'01 Jun 2022','01 Sep 2022'))t
CROSS APPLY (VALUES (1),(2))ca1(ID)
;
--===== "Wound" the data for ID = 2 to make "gaps" in the data.
DELETE FROM #MyData
WHERE ID = 2
AND ReportDate IN
(
'2022-07-02'
,'2022-07-03'
,'2022-07-04'
-------------
,'2022-07-09'
,'2022-07-10'
-------------
,'2022-07-16'
,'2022-07-17'
-------------
,'2022-07-23'
,'2022-07-24'
-------------
,'2022-07-30'
,'2022-07-31'
)
;
INSERT INTO #MyData
SELECT ID,
ID2 + 1000,
ReportDate,
ReportValue + 1000
FROM #MyData
/*
;
*/GO
--=====================================================================================================================
-- Solution for all the requirements I am currently aware of.
-- Jeff Moden - Rev Eleventy-Bazillion :D - 14 Aug 2022
-- References:
--===== Itzik Ben-Gan's solution article referred to by Drew Allen.
-- https://www.itprotoday.com/sql-server/last-non-null-puzzle
--===== Drew Allen's post that introduced us to the Itzik Ben-Gans artical.
-- https://www.sqlservercentral.com/forums/topic/using-lag-to-return-prior-non-null-value#post-4072582
--=====================================================================================================================
--===== Define the range of dates the report is based on.
-- Note that is based on the assumption that there are no times in the source data. WHOLE date only!!
-- Also note that the @ExtendDays extends the search range before the @ReportStart and after the @ReportEnd
-- to solve the problems of start or ending on days where data doesn't exist and also solves the problem of
-- a single day lookup for a date with no data.
--===== This example has start and end sdates that don't exist
DECLARE @ReportStart DATE = '2022-07-03'
,@ReportEnd DATE = '2022-07-10'
,@ExtendDays INT = 30
;
--My attempt to make the start date of the range of dates needed dynamic
--Find the latest date for each combination of IDs; Then get the earliest one
DECLARE @SmearStart DATE =
(
SELECT MIN(ReportDate) FROM
(
SELECT
MAX(ReportDate) AS ReportDate,
ID,
ID2
FROM #MyData
WHERE
ReportDate < @ReportStart
GROUP BY
ID,
ID2
) SmearStart
)
SELECT @SmearStart AS SmearStart
----===== This example is for a single day lookup where no data exists.
-- -- Comment the above DECLARE out and uncomment this one to test.
--DECLARE @ReportStart DATE = '2022-07-03'
-- ,@ReportEnd DATE = '2022-07-03'
-- ,@ExtendDays INT = 30
--;
SET STATISTICS TIME,IO ON;
WITH cteIDs AS
(--==== Finds all the UNIQUE IDs for the given reporting period
-- Remove the WHERE if you want to report NULL's for IDs not in the reporting period
SELECT dspyID = d.ID,dspyID2 = d.ID2
FROM #MyData d
WHERE
d.ReportDate >
@SmearStart--
--DATEADD(dd,-@ExtendDays ,@ReportStart)
AND d.ReportDate < DATEADD(dd,@ExtendDays+1,@ReportEnd)
GROUP BY d.ID,d.ID2
)
,cteDatedIDs AS
(--==== Generates a calendar for each ID and includes the ID with no missing dates. Saves a "smear" in the process.
-- ***** NOTE THAT THIS METHOD REQUIRES THE PRESENCE OF AN ACTUAL INDEXED CALENDAR TABLE. *****
-- The DATEADDs extend the search range to @ExtendDays before the start of the desired range and
-- @ExtendDays days after the desired range. This picks up "smear" values that aren't in the desired range.
SELECT i.dspyID,i.dspyID2
,c.CalendarDate
FROM #Calendar c
CROSS JOIN cteIDs i
WHERE c.CalendarDate >
@SmearStart
--DATEADD(dd,-@ExtendDays ,@ReportStart)
AND c.CalendarDate < DATEADD(dd, @ExtendDays+1,@ReportEnd)
)
,cteSmear AS
(--==== This does the "smears".
-- Read the comments for TOP and ORDER BY force materialization of data using a "Blocking Operator".
-- This contains the trick that Drew showed us based on an article that Itzik Ben-Gan wrote.
-- In this case, the OUTER APPLY provides much fewer "Work Table" reads than a CROSS APPLY does.
-- The RowNum is just to make it easy to identify a given row during discussion and may be removed.
-- Apologies for the long code lines. They're just easier to read and compare that way.
SELECT TOP 3000000000 --This top is necessary to do the ORDER BY. Easy to remember big number of 3 follwed by 9 zeros.
RowNum = ROW_NUMBER() OVER (ORDER BY dtid.dspyID,dtid.dspyID2,dtid.CalendarDate)
,ID = dtid.dspyID
,ID2 = dtid.dspyID2
,CalendarDate = dtid.CalendarDate
,ReportedValue = mdat.ReportValue
,LastReportedDate = CONVERT(DATE,SUBSTRING(MAX(v.Val) OVER (PARTITION BY dtid.dspyID,dtid.dspyID2 ORDER BY dtid.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING),11,10))
,LastReportedValue = CONVERT(CHAR(38) ,SUBSTRING(MAX(v.Val) OVER (PARTITION BY dtid.dspyID,dtid.dspyID2 ORDER BY dtid.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING),21,10))
,NextReportedDate = CONVERT(DATE,SUBSTRING(MIN(v.Val) OVER (PARTITION BY dtid.dspyID,dtid.dspyID2 ORDER BY dtid.CalendarDate ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING),11,10))
,NextReportedValue = CONVERT(CHAR(38) ,SUBSTRING(MIN(v.Val) OVER (PARTITION BY dtid.dspyID,dtid.dspyID2 ORDER BY dtid.CalendarDate ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING),21,10))
FROM cteDatedIDs dtid
LEFT JOIN #MyData mdat
ON mdat.ID = dtid.dspyID
AND mdat.ID2 = dtid.dspyID2
AND mdat.ReportDate = dtid.CalendarDate
OUTER APPLY (VALUES(CONVERT(CHAR(10),dtid.dspyID) + CONVERT(CHAR(10),dtid.CalendarDate) + CONVERT(CHAR(38),mdat.ReportValue)+ CONVERT(CHAR(5),dtid.dspyID2)))v(Val)
ORDER BY dtid.dspyID,dtid.dspyID2,dtid.CalendarDate --This ORDER BY is a "Blocking Operator" that forces the data to materialize
--to find "LAGs'n'LEADs" outside of the desired range.
)--==== And now we return just the data from inside the desired range of dates.
-- 1. If rows exist within the @ExtendedDays range outside the Desired Range,
-- there will be no NULL values in the Desired Range.
-- 2. If we had done the WHERE in the cteSmear, we'd have ended up with NULL "LAGs'n'LEADs" in this desired range.
-- Instead, this also solves the problem of a single date (like 2022-07-03) that doesn't exist in the original data.
SELECT *
FROM cteSmear
WHERE CalendarDate >= @ReportStart
AND CalendarDate <= @ReportEnd
--WHERE dspyID = 2 --Just for testing/verification
ORDER BY ID,CalendarDate
SET STATISTICS TIME,IO OFF;
GO -
Awesome news about the Substring parameters. And, I've not run it but it looks like your @SmearStart will likely do the trick.
All of that and your previous column additions means that you understand the code and aren't just going to blindly use it. Nice job, Chrissy!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hello Again,
Funny when you search for an answer and find your own thread. I added some additional fields to my data to make it more real world and also data-typed the temp table to eliminate some guesswork.
I added columns ReportType, AccountName and AccountAttribute (nullable)
I am looking at Drew's original response (#4072582) and trying to get it to work. I thought adding PARTITION BY would work.
Any help in making this technique work with the additional columns?
See code and my inline comments.
--Microsoft SQL Server 2019
--Build a temp calendar table
DROP TABLE IF EXISTS #Calendar
CREATE TABLE #Calendar (CalendarDate DATE)
DECLARE @Start DATE = '2022-07-01'
DECLARE @End DATE = '2022-07-31'
WHILE ( @Start < @End )
BEGIN
INSERT INTO #Calendar (CalendarDate) VALUES( @Start )
SELECT @Start = DATEADD(DAY, 1, @Start )
END
DROP TABLE IF EXISTS #MyData
CREATE TABLE #MyData
(
ReportDate varchar(10) NOT NULL,
ReportValue int NOT NULL,
ReportType VARCHAR(10) NOT NULL,
AccountID int NOT NULL,
AccountName VARCHAR(5) NOT NULL,
AccountAttribute VARCHAR(10)NULL
)
INSERT INTO #MyData (ReportDate, ReportValue,ReportType, AccountID,AccountName,AccountAttribute)
VALUES
( '2022-07-01', 100,'Summary', 1,'No.1','xyz' ),
( '2022-07-05', 101,'Summary', 1,'No.1','xyz' ),
( '2022-07-06', 102,'Summary', 1,'No.1','xyz' ),
( '2022-07-07', 103,'Summary', 1,'No.1','xyz' ),
( '2022-07-08', 104,'Summary', 1,'No.1','xyz' ),
( '2022-07-11', 105,'Summary', 1,'No.1','xyz' ),
( '2022-07-12', 106,'Summary', 1,'No.1','xyz' ),
( '2022-07-13', 107,'Summary', 1,'No.1','xyz' ),
( '2022-07-14', 108,'Summary', 1,'No.1','xyz' ),
( '2022-07-15', 109,'Summary', 1,'No.1','xyz' ),
( '2022-07-18', 110,'Summary', 1,'No.1','xyz' ),
( '2022-07-19', 111,'Summary', 1,'No.1','xyz' ),
( '2022-07-20', 112,'Summary', 1,'No.1','xyz' ),
( '2022-07-21', 113,'Summary', 1,'No.1','xyz' ),
( '2022-07-22', 114,'Summary', 1,'No.1','xyz' ),
( '2022-07-25', 115,'Summary', 1,'No.1','xyz' ),
( '2022-07-26', 116,'Summary', 1,'No.1','xyz' ),
( '2022-07-27', 117,'Summary', 1,'No.1','xyz' ),
( '2022-07-28', 118,'Summary', 1,'No.1','xyz' ),
( '2022-07-29', 119,'Summary', 1,'No.1','xyz' ),
( '2022-07-01', 100,'Summary', 2,'No.2',NULL ),
( '2022-07-05', 101,'Summary', 2,'No.2',NULL ),
( '2022-07-06', 102,'Summary', 2,'No.2',NULL ),
( '2022-07-07', 103,'Summary', 2,'No.2',NULL ),
( '2022-07-08', 104,'Summary', 2,'No.2',NULL ),
( '2022-07-11', 105,'Summary', 2,'No.2',NULL ),
( '2022-07-12', 106,'Summary', 2,'No.2',NULL ),
( '2022-07-13', 107,'Summary', 2,'No.2',NULL ),
( '2022-07-14', 108,'Summary', 2,'No.2',NULL ),
( '2022-07-15', 109,'Summary', 2,'No.2',NULL ),
( '2022-07-18', 110,'Summary', 2,'No.2',NULL ),
( '2022-07-19', 111,'Summary', 2,'No.2',NULL ),
( '2022-07-20', 112,'Summary', 2,'No.2',NULL ),
( '2022-07-21', 113,'Summary', 2,'No.2',NULL ),
( '2022-07-22', 114,'Summary', 2,'No.2',NULL ),
( '2022-07-25', 115,'Summary',2,'No.2',NULL ),
( '2022-07-26', 116,'Summary',2,'No.2',NULL ),
( '2022-07-27', 117,'Summary', 2,'No.2',NULL ),
( '2022-07-28', 118,'Summary', 2,'No.2',NULL ),
( '2022-07-29', 119,'Summary', 2,'No.2',NULL ),
( '2022-07-01', 100,'Detail', 2,'No.1',NULL ),
( '2022-07-11', 105,'Detail', 2,'No.1',NULL ),
( '2022-07-18', 110,'Detail', 2,'No.1',NULL ),
( '2022-07-21', 113,'Detail', 2,'No.1',NULL )
--SELECT * FROM #MyData
--Drew's original still good; Account 1 only
SELECT C.CalendarDate
, D.ReportDate
, D.ReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 1, 10) AS DATE) AS LagReportDate
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 11, 10) AS INT) AS LagReportValue
FROM #Calendar C
LEFT JOIN #MyData D
ON C.CalendarDate = D.ReportDate
AND AccountID = 1
CROSS APPLY (VALUES(CAST(C.CalendarDate AS CHAR(10)) + CAST(D.ReportValue AS CHAR(10)))) v(val)
ORDER BY C.CalendarDate
--Attempt to add additional columns for Account 1 only, Still good
SELECT C.CalendarDate
, D.ReportDate
, D.ReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 1, 10) AS DATE) AS LagReportDate
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 11, 10) AS INT) AS LagReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 21, 10) AS VARCHAR(10)) AS LagReportType
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 31, 1) AS INT) AS LagAccountID
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 32, 5) AS VARCHAR(5)) AS LagAccountName
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 37, 10) AS VARCHAR(10)) AS LagAccountAttribute
FROM #Calendar C
LEFT JOIN #MyData D
ON C.CalendarDate = D.ReportDate
AND AccountID = 1
CROSS APPLY (VALUES(CAST(C.CalendarDate AS CHAR(10)) + CAST(D.ReportValue AS CHAR(10)) + + CAST(D.ReportType AS CHAR(10)) + CAST(D.AccountID AS CHAR(1)) + CAST(D.AccountName AS CHAR(5))+ CAST(D.AccountAttribute AS CHAR(10)))) v(val)
ORDER BY C.CalendarDate
--Attempt to add AccountID 2; Where did account 2 go?
SELECT C.CalendarDate
, D.ReportDate
, D.ReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 1, 10) AS DATE) AS LagReportDate
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 11, 10) AS INT) AS LagReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 21, 10) AS VARCHAR(10)) AS LagReportType
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 31, 1) AS INT) AS LagAccountID
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 32, 5) AS VARCHAR(5)) AS LagAccountName
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 37, 10) AS VARCHAR(10)) AS LagAccountAttribute
,v.val
FROM #Calendar C
LEFT JOIN #MyData D
ON C.CalendarDate = D.ReportDate
CROSS APPLY (VALUES(CAST(C.CalendarDate AS CHAR(10)) + CAST(D.ReportValue AS CHAR(10)) + + CAST(D.ReportType AS CHAR(10)) + CAST(D.AccountID AS CHAR(1)) + CAST(D.AccountName AS CHAR(5))+ CAST(D.AccountAttribute AS CHAR(10)))) v(val)
ORDER BY C.CalendarDate
--AccountID 2 is here
SELECT *
FROM #Calendar C
LEFT JOIN #MyData D
ON C.CalendarDate = D.ReportDate
ORDER BY C.CalendarDate
--Attempt to Partition
SELECT C.CalendarDate
, D.ReportDate
, D.ReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(PARTITION BY ReportDate,ReportType,AccountID,AccountName,AccountAttribute ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 1, 10) AS DATE) AS LagReportDate
, CAST(SUBSTRING(MAX(v.val) OVER(PARTITION BY ReportDate,ReportType,AccountID,AccountName,AccountAttribute ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 11, 10) AS INT) AS LagReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(PARTITION BY ReportDate,ReportType,AccountID,AccountName,AccountAttribute ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 21, 10) AS VARCHAR(10)) AS LagReportType
, CAST(SUBSTRING(MAX(v.val) OVER(PARTITION BY ReportDate,ReportType,AccountID,AccountName,AccountAttribute ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 21, 1) AS INT) AS LagAccountID
, CAST(SUBSTRING(MAX(v.val) OVER(PARTITION BY ReportDate,ReportType,AccountID,AccountName,AccountAttribute ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 22, 5) AS VARCHAR(5)) AS LagAccountName
, CAST(SUBSTRING(MAX(v.val) OVER(PARTITION BY ReportDate,ReportType,AccountID,AccountName,AccountAttribute ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 27, 10) AS VARCHAR(10)) AS LagAccountAttribute
FROM #Calendar C
LEFT JOIN #MyData D
ON C.CalendarDate = D.ReportDate
CROSS APPLY (VALUES(CAST(C.CalendarDate AS CHAR(10)) + CAST(D.ReportValue AS CHAR(10)) + + CAST(D.ReportType AS CHAR(10)) + CAST(D.AccountID AS CHAR(1)) + CAST(D.AccountName AS CHAR(5))+ CAST(D.AccountAttribute AS CHAR(10)))) v(val)
ORDER BY C.CalendarDate -
Good Morning or Good Evening,
Long thread here so I thought I would simplify the problem and my questions.
When limiting the account to 1 (AccountID = 1) I get 30 records. When not applying a where to AccountID (2nd query) I get 50 records. Why? Can I rewrite the CROSS APPLY to get 60?
In the 2nd result see an AccountID of 2 in v.val but the LagReportAccountID is 1. Why are these not consistent?
Is there a different CROSS APPLY join that I need to make this technique work?
Thanks
--Microsoft SQL Server 2019
--Build a temp calendar table
DROP TABLE IF EXISTS #Calendar
CREATE TABLE #Calendar (CalendarDate DATE)
DECLARE @Start DATE = '2022-07-01'
DECLARE @End DATE = '2022-07-31'
WHILE ( @Start < @End )
BEGIN
INSERT INTO #Calendar (CalendarDate) VALUES( @Start )
SELECT @Start = DATEADD(DAY, 1, @Start )
END
DROP TABLE IF EXISTS #MyData
CREATE TABLE #MyData
(
ReportDate varchar(10) NOT NULL,
AccountID int NOT NULL,
ReportValue int NOT NULL
)
INSERT INTO #MyData (ReportDate, AccountID,ReportValue)
VALUES
( '2022-07-01',1, 100 ),
( '2022-07-05',1, 101 ),
( '2022-07-06',1, 102 ),
( '2022-07-07',1, 103 ),
( '2022-07-08',1, 104 ),
( '2022-07-11',1, 105 ),
( '2022-07-12',1, 106 ),
( '2022-07-13',1, 107 ),
( '2022-07-14',1, 108 ),
( '2022-07-15',1, 109 ),
( '2022-07-18',1, 110 ),
( '2022-07-19',1, 111 ),
( '2022-07-20',1, 112 ),
( '2022-07-21',1, 113 ),
( '2022-07-22',1, 114 ),
( '2022-07-25',1, 115 ),
( '2022-07-26',1, 116 ),
( '2022-07-27',1, 117 ),
( '2022-07-28',1, 118 ),
( '2022-07-29',1, 119 ),
( '2022-07-01',2, 200 ),
( '2022-07-05',2, 201 ),
( '2022-07-06',2, 202 ),
( '2022-07-07',2, 203 ),
( '2022-07-08',2, 204 ),
( '2022-07-11',2, 205 ),
( '2022-07-12',2, 206 ),
( '2022-07-13',2, 207 ),
( '2022-07-14',2, 208 ),
( '2022-07-15',2, 209 ),
( '2022-07-18',2, 210 ),
( '2022-07-19',2, 211 ),
( '2022-07-20',2, 212 ),
( '2022-07-21',2, 213 ),
( '2022-07-22',2, 214 ),
( '2022-07-25',2, 215 ),
( '2022-07-26',2, 216 ),
( '2022-07-27',2, 217 ),
( '2022-07-28',2, 218 ),
( '2022-07-29',2, 219 )
--SELECT * FROM #MyData ORDER BY ReportDate, AccountID
--Quick reality check; Accounts are equivalent except account number and account 2 values are in the 200 range
/*
SELECT ReportDate,AccountID,ReportValue FROM #MyData WHERE AccountID =1
EXCEPT
SELECT ReportDate,AccountID - 1,ReportValue - 100 FROM #MyData WHERE AccountID = 2
*/
SELECT
v.val
, C.CalendarDate
, D.ReportDate
, D.AccountID
, D.ReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 1, 10) AS DATE) AS LagReportDate
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 11, 10) AS INT) AS LagReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 21, 10) AS INT) AS LagReportAccountID
FROM #Calendar C
LEFT JOIN #MyData D
ON C.CalendarDate = D.ReportDate
AND AccountID = 1
CROSS APPLY (VALUES(CAST(C.CalendarDate AS CHAR(10)) + CAST(D.ReportValue AS CHAR(10)) + CAST(D.AccountID AS CHAR(10)) )) v(val)
ORDER BY C.CalendarDate,LagReportAccountID
SELECT
v.val
, C.CalendarDate
, D.ReportDate
, D.AccountID
, D.ReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 1, 10) AS DATE) AS LagReportDate
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 11, 10) AS INT) AS LagReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 21, 10) AS INT) AS LagReportAccountID
FROM #Calendar C
LEFT JOIN #MyData D
ON C.CalendarDate = D.ReportDate
--AND AccountID = 1
CROSS APPLY (VALUES(CAST(C.CalendarDate AS CHAR(10)) + CAST(D.ReportValue AS CHAR(10)) + CAST(D.AccountID AS CHAR(10)) )) v(val)
ORDER BY C.CalendarDate,LagReportAccountID -
I posted a follow-up an hour ago but I don't see it (yet)
Here's my latest, added CROSS JOIN to DISTINCT AccountID which returns the correct number of records.
My 'lag' columns still are returning data somewhat randomly
--Microsoft SQL Server 2019
--Build a temp calendar table
DROP TABLE IF EXISTS #Calendar
CREATE TABLE #Calendar (CalendarDate DATE)
DECLARE @Start DATE = '2022-07-01'
DECLARE @End DATE = '2022-07-31'
WHILE ( @Start < @End )
BEGIN
INSERT INTO #Calendar (CalendarDate) VALUES( @Start )
SELECT @Start = DATEADD(DAY, 1, @Start )
END
DROP TABLE IF EXISTS #MyData
CREATE TABLE #MyData
(
ReportDate varchar(10) NOT NULL,
AccountID int NOT NULL,
ReportValue int NOT NULL
)
INSERT INTO #MyData (ReportDate, AccountID,ReportValue)
VALUES
( '2022-07-01',1, 100 ),
( '2022-07-05',1, 101 ),
( '2022-07-06',1, 102 ),
( '2022-07-07',1, 103 ),
( '2022-07-08',1, 104 ),
( '2022-07-11',1, 105 ),
( '2022-07-12',1, 106 ),
( '2022-07-13',1, 107 ),
( '2022-07-14',1, 108 ),
( '2022-07-15',1, 109 ),
( '2022-07-18',1, 110 ),
( '2022-07-19',1, 111 ),
( '2022-07-20',1, 112 ),
( '2022-07-21',1, 113 ),
( '2022-07-22',1, 114 ),
( '2022-07-25',1, 115 ),
( '2022-07-26',1, 116 ),
( '2022-07-27',1, 117 ),
( '2022-07-28',1, 118 ),
( '2022-07-29',1, 119 ),
( '2022-07-01',2, 200 ),
( '2022-07-05',2, 201 ),
( '2022-07-06',2, 202 ),
( '2022-07-07',2, 203 ),
( '2022-07-08',2, 204 ),
( '2022-07-11',2, 205 ),
( '2022-07-12',2, 206 ),
( '2022-07-13',2, 207 ),
( '2022-07-14',2, 208 ),
( '2022-07-15',2, 209 ),
( '2022-07-18',2, 210 ),
( '2022-07-19',2, 211 ),
( '2022-07-20',2, 212 ),
( '2022-07-21',2, 213 ),
( '2022-07-22',2, 214 ),
( '2022-07-25',2, 215 ),
( '2022-07-26',2, 216 ),
( '2022-07-27',2, 217 ),
( '2022-07-28',2, 218 ),
( '2022-07-29',2, 219 )
--SELECT * FROM #MyData ORDER BY ReportDate, AccountID
--Quick reality check; Accounts are equivalent except account number and account 2 values are in the 200 range
/*
SELECT ReportDate,AccountID,ReportValue FROM #MyData WHERE AccountID =1
EXCEPT
SELECT ReportDate,AccountID - 1,ReportValue - 100 FROM #MyData WHERE AccountID = 2
*/
SELECT
v.val
, C.CalendarDate
, D.ReportDate
, D.AccountID
, D.ReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 1, 10) AS DATE) AS LagReportDate
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 11, 10) AS INT) AS LagReportValue
, CAST(SUBSTRING(MAX(v.val) OVER(ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 21, 10) AS INT) AS LagReportAccountID
FROM #Calendar C
CROSS JOIN
(
SELECT DISTINCT AccountID FROM #MyData
--WHERE AccountID = 1
) A
LEFT JOIN #MyData D
ON
C.CalendarDate = D.ReportDate AND
A.AccountID = D.AccountID
CROSS APPLY (VALUES(CAST(C.CalendarDate AS CHAR(10)) + CAST(D.ReportValue AS CHAR(10)) + CAST(D.AccountID AS CHAR(10)))) v(val)
ORDER BY C.CalendarDate,COALESCE(A.AccountID,CAST(SUBSTRING(MAX(v.val) OVER(PARTITION BY A.AccountID ORDER BY C.CalendarDate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING), 11, 10) AS INT))
Viewing 15 posts - 31 through 45 (of 45 total)
You must be logged in to reply to this topic. Login to reply