The place of SMALLDATETIME
- ScottPletcher wrote:
The business I'm at certainly doesn't require more than 200 gender "types." Neither does yours I'm sure, nor anyone else's at this point (I guess some ultra-woke colleges theoretically could, but ... likely nah).
Storage is still a valid concern. Particularly if you have 100Ms/Bs of rows. You have to remember that it also affects log writes/size. And data compression generally does not reduce log size requirements.
there don't need to be 256 types to use up 256 lookup values. I HAVE worked somewhere with about 50-60 entries (about half of them inactive) in the sex/gender lookup table that was rapidly growing with new attributes being added while ops figured out what it was they wanted to do reporting and analytics on while still recording basic attributes required for compliance. Add in a number of bureaucrats who decide something like 'undermined' is offensive and needs to be replaced with 'not disclosed,' which then leads to a compliance violation as the second one puts words in the mouth of a subject that were never said (or not said) and you end up with 3-4 historical attributes that are supposed to all mean 'unknown' but can't be modified since they possibly meant something slightly other than 'unknown,' which may have been interpreted by the user as that other "something" when the record was created.
even at 10 billion rows, 4 bytes of savings on foreign keys amounts to 37 gb. without putting a single bit of data into the table, the 64 bit integer primary key alone dwarfs the space savings of 4 bytes in all 10 billion rows.
- CreateIndexNonclustered wrote:ScottPletcher wrote:
The business I'm at certainly doesn't require more than 200 gender "types." Neither does yours I'm sure, nor anyone else's at this point (I guess some ultra-woke colleges theoretically could, but ... likely nah).
Storage is still a valid concern. Particularly if you have 100Ms/Bs of rows. You have to remember that it also affects log writes/size. And data compression generally does not reduce log size requirements.
there don't need to be 256 types to use up 256 lookup values. I HAVE worked somewhere with about 50-60 entries (about half of them inactive) in the sex/gender lookup table that was rapidly growing with new attributes being added while ops figured out what it was they wanted to do reporting and analytics on while still recording basic attributes required for compliance. Add in a number of bureaucrats who decide something like 'undermined' is offensive and needs to be replaced with 'not disclosed,' which then leads to a compliance violation as the second one puts words in the mouth of a subject that were never said (or not said) and you end up with 3-4 historical attributes that are supposed to all mean 'unknown' but can't be modified since they possibly meant something slightly other than 'unknown,' which may have been interpreted by the user as that other "something" when the record was created.
even at 10 billion rows, 4 bytes of savings on foreign keys amounts to 37 gb. without putting a single bit of data into the table, the 64 bit integer primary key alone dwarfs the space savings of 4 bytes in all 10 billion rows.
So you didn't have anything close to 255 values either: confirmed.
If you need a bigint you need it, as a pk or whatever. Space you need is not wasted, obviously, only space you don't need to use. Like allowing 4 billions values when the number of values will never exceed 60 or 80.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
No.
-
As in you are just not correct.
- CreateIndexNonclustered wrote:
No.
What a well thought out, respectful, and detailed argument!
I cannot believe that anybody would not take your position after such astonishing and convincing evidence.
-
The
Jeff Moden wrote:sean redmond wrote:The rounding up of the last 30 seconds to the next hour is not a problem. ... And as for space, if we have 100GB of data, then we have a 100GB of data.
If the dates/times in the column of those tables isn't consider to be "data" and the resolution of the dates and times can be so shoddy, then why even have the columns?
And, no... not looking for answer from you there. Just throwing another thought at you. 😉
Sorry for the late reply. I was out for a week and it slipped my mind afterwards.
Accuracy to within a minute in these cases has proved in the past to be sufficient. 'Shoddy' is the wrong word here. It does its job well. The primary use case of these columns are cases from help desk (or sometimes product managers): when was such-and-such created, last changed and so on. I have mentioned in the past that I could set up a more extensive system with temporal tables to track all changes in all tables but it is outside the range they are prepared to pay for (we use a system of internal accounting where I work). For example, the columns might reveal that user with the ID 3120021 created/changed this column on 2023-04-03 12:53 and this generally satisfies the person asking. Adding in milliseconds (2023-04-03 12:53:01.678) wouldn't add any more useful information. This is the difference between SMALLDATETIME & DATETIME2(3) and 4 bytes per row.
The initial reason to ask the question was the principle of using the smallest datatype that does the job. It brings me into conflict with the developers who are used to the default datatypes as used by Entity Framework. I had to ask one developer to change all of the versionuser columns from varchar(max) to varchar(30) recently.
This principle seemed self evident to me but now I see that I should not be strict with something so core in database design. Just because a design can have dense pages doesn't mean that it must. More hardware will solve the problem.
-
"Shoddy" is the correct term for the rounding of the SMALLDATETIME datatype.
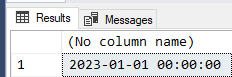
SELECT CONVERT(SMALLDATETIME,'31 Dec 2022 23:59:30.000');
Result... next day, week, month, and year.

Like I said, "Shoddy". If you want to tolerate that kind of thing, that's your business but you asked what are some thoughts on the subject are and my thoughts are that SMALLDATETIME is "Shoddy" and it's NOT worth saving the bytes that way.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Fair enough.
-
marking that as spam just because it sounds like a chatgpt bot
-
Hi,
Is your query resolved? I hope you have found your answer from so many experts here. If not then I can also cooperate.
For Quality Service of Balloon Decor: https://balloonslane.com/nyc-balloons/
- john_manson wrote:
Hi,
Is your query resolved? I hope you have found your answer from so many experts here. If not then I can also cooperate.
The answer lies in a matter of perspective. The general consensus is that I framed the question the wrong way and that I shouldn't be using SMALLDATETIME in the first place: resources are plentiful and not as precious as they once were.
There should be no real reason for me not to use DATETIME2(). Jeff Moden also pointed out that SMALLDATETIME's rounding leaves a lot to be desired.
Viewing 11 posts - 16 through 26 (of 26 total)
You must be logged in to reply to this topic. Login to reply