Tempdb: is it being used?
-
hi
so i have a really old application that is used to process data into our ERP system
long story short, it sporadically works really slow. Generally large transactions kick off the slow process,
so i have been digging around sql to see what could be the issue - i run decent index routines nightly and in general operation sql is no issues
then i notice this

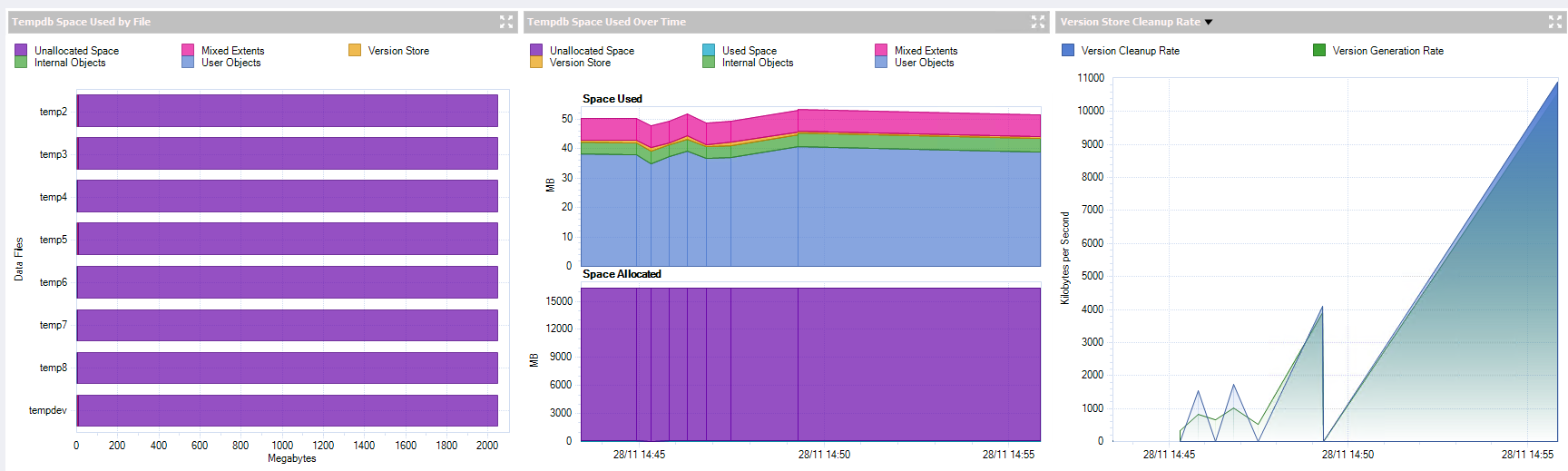
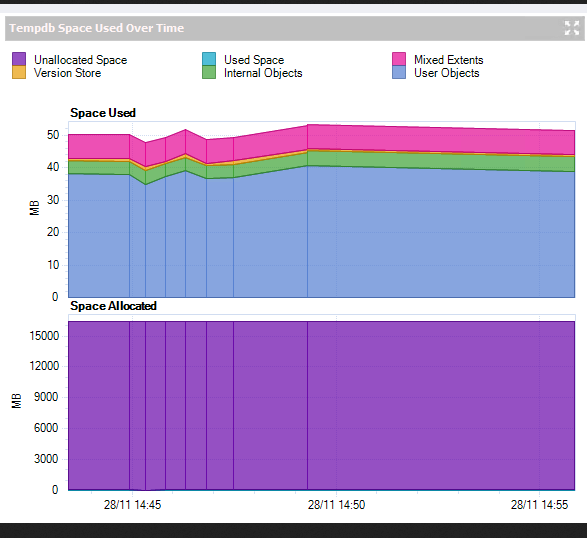
despite tempdb being used quite a lot - to me it looks like it is not using the allocated space?
am i reading this correctly?
thank
mal
-
tempdb is used for all temporary storage required by a query. Temp tables and table variables are the big things that fill it up, but other things can be stored in there too.
You can shrink tempdb, but if it grew to that size for some reason, there is a pretty good chance it will grow again. BUT once the session is closed, the temporary objects are cleaned up.
Now, looking at the used space, I would recommend looking at something larger than a 10 minute time slice. If possible, I would look back to the last reboot or last time tempdb was shrunk so that I could see when the grow occurred. Then, if I had access to the data, I would look at what was running around that time to see what caused the growth.
My guess is that you have 1 or 2 queries that use a lot of tempdb space but once they complete, the space is released. What can be interesting though is to watch for the tempdb growth. It MAY be a once per year thing that causes the growth and you may want to schedule a shrink at some point. Alternately, it may be a once per day thing (ETL may be using tempdb for a bunch of stuff for example), and shrinking may not be desirable. If you can narrow down the culprit of the growth, then you can tweak your grow/shrink patterns too and pre-grow before the large query runs and then shrink once complete. Be careful with shrinking though as it does lock things up, so if you can shrink with the truncate only parameter, that is going to be your best bet. Another risk with shrinking though is your free disk space. If this is (for example) a once per year thing and it uses 16 GB of tempdb space and you shrink it after it is complete, you will need to remember to check for free disk space before that process kicks off.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
hi Brian
my query is more - why is no space ever being being used beyond 50mb? it has the most transactions/sec
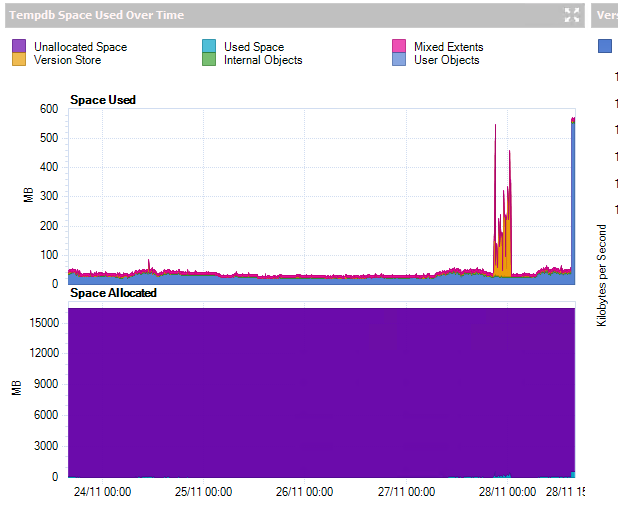
below shows past 5 days, top chart is space used, bottom is space available
the only system spikes are last night when i done some archival work and today, when i ran a script to test tempdb
the rest of the time it seems dormant from a growth perspective
this server has many DBS, largest of which is 300GB - our main ERP system, lots of transactions, queries, reports etc being ran
should tempdb not be utilised more than this? and it could it pinpoint an issue?
-
You're looking at a 10 minute span of time for TempDB. Was that span of time during your long winded run?
You also say that "i run decent index routines nightly". This is no slam on you because the world has been misled about index maintenance "Best Practices" for more than 2 decades but there's a good chance that your nightly "decent index routines" are causing more problem than they're fixing. Could you post the "settings" that you're using for those?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff
look at my reply above , thats a five day window!
the scripts i use for indexing are just the standard ola hallengren scripts
And as i said, normal erp sql activity is pretty good
im probably looking at something thats irrelevant, but its just something i thought was peculiar?
-
EXECUTE [dbo].[IndexOptimize]
@Databases = 'Kinetic,Doclink2,ESCDB',
@FragmentationLow = NULL,
@FragmentationMedium = 'INDEX_REORGANIZE,INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE',
@FragmentationHigh = 'INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE',
@FragmentationLevel1 = 5,
@FragmentationLevel2 = 30,
@SortInTempdb = 'Y',
@UpdateStatistics = 'ALL',
@FillFactor = 90,
@OnlyModifiedStatistics = 'Y',
@LogToTable = 'Y' -
Only 50 MB is being used in the 10 minute timeframe. Looking at the longer time frame we can see more is used, jumping up to nearly 600 MB at the highest point.
So my guess as to what happened is one of the following 3 scenarios:
1- you HAD a heavy query or multiple large queries run at some point that needed tempdb space and you got up to the 16 GB mark
2- whoever set up that SQL instance had no idea how much tempdb space you needed and just typed in a large number
3- someone set it to a large number for some reason
Now, number of transactions has nothing to do with how much space is used. If I write a query that creates 100 temp tables, that's 100 writes to tempdb. Then if I put 1 row in each table, that is another 100 writes to tempdb. If that works out to be 1 MB total data written, that's 1 MB written to tempdb. Then I clean it up by dropping the temp tables, and more writes to tempdb. BUT the space used is only 1 MB.
Having a LOT of transactions per second does not equate to more space used. Heck, it could be I create 1 temp table and insert 1 row of data but I do a SELECT on it 100 separate times in my stored procedure; that would come out as 100+ "transactions" against tempdb, but it's not much data going in so the space used will be small.
As for the index maintenance that Jeff is leading up to, that's one of those things where index maintenance can hurt performance. If your inserts and updates are happening frequently in the middle of a page, index maintenance will only help create more page splits which are a slow operation. Index maintenance is best performed on SELECT heavy indexes, not INSERT/UPDATE heavy indexes, and even then, with the advancement of computer technology, the improvements from index maintenance are often pretty small. Plus, SELECT heavy indexes rarely need maintenance as they don't get as fragmented. There are exceptions (like with everything in SQL server), but the general rule is to "test stuff yourself on your environment". Someone may say "I never rebuild indexes and performance increased 10 fold" and in your environment it is the opposite. There are a lot of things like that, and to make it more fun, things can change between SQL versions. Upgrading from 2008 to 2022 may require no settings tweaks to maintain current performance or you may need to turn on the legacy cardinality estimator to make things behave nicely (for example).
The favorite phrase of a DBA is "it depends" because there is always more than one answer to a question about DBA work. Like with your question, my first 2 thoughts are either "something made it grow" or "someone made it grow" or a combination of the two. The combo would be if the autogrow settings were very very wrong. If you have your autogrow set to 16 GB (for example) but the default size is 50 MB, SQL will autogrow to 16GB once that database is full. This would be a really weird setup, but I know at one point a former DBA was changing all of our instances from percent in autogrow to hard values and had MEANT to set one of the databases to grow by 4096 MB but accidentally set it to grow by 4096%. This was a 400 GB database, so growing by 4096% was a pretty big jump and set off our disk alerts and I looked into what happened. Lucky for us we had free disk for that grow at the time. Easy fix, but not a fun surprise when a former DBA set something up so wrong by simply clicking the wrong button. And the best part - the former DBA wasn't even working with the company when that happened. You may be in a similar scenario...
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - dopydb wrote:
Jeff
look at my reply above , thats a five day window!
the scripts i use for indexing are just the standard ola hallengren scripts
And as i said, normal erp sql activity is pretty good
im probably looking at something thats irrelevant, but its just something i thought was peculiar?
Not the one I was originally looking at, which was this one... I posted without refreshing my screen and so didn't see your additional post.
On that subject (TempDB usage) and also looking at the 5 day graph you're talking about, you don't have the indications of a problem there no does it indicate the you don't have problems.
On the Subject of Index Maintenance
Shifting gears to the indexing... Ola's code is fantastic. The way people use it is not. You're doing the same wrong thing that 99% of the world does. Even the guy that "invented" those settings denounced them way back in 2009. Read the last 2 paragraphs of the following article... especially the very last sentence of the article.
As many before me have said, "Index maintenance is a really expensive way to rebuild your statistics", which is usually the real savior when it comes to performance, especially if most of your Clustered Indexes are based on an "Ever Increasing" key such as an IDENTITY/SEQUENCE or some form of DATETIME column.
REORGANIZE is a serious problem. People use it without knowing what it actually does and how little it actually does. I know you don't know what it does because you wouldn't be using it if you did. It will NOT, for example, set your pages to the FILL FACTOR because it will NOT create pages to reduce page density to the FILL FACTOR like REBUILD will. In fact, REORGANIZE will decrease page density UP to the FILL FACTOR, which is the worst thing you can do when most of your page densities have filled to above the FILL FACTOR.
Also, take a month of Sundays like I have and find any form of BBFAATT (pronounced as "bee-bee-fat" and can be bleated like a goat when sarcasm is intended and stands for Books, Blogs, Forums, AI, Articles, 'Tubes, and Talks) where it say that logical fragmentation CAN cause performance issues and then find even one where they demonstrate that is true. No one has proven it and I'm working on an article (it's taking a while to simplify it to keep it from being a hefty tome) with real, live, repeatable demonstrations that prove that it's usually not true and is so small that it doesn't matter in most cases. I also prove where it can actually make performance worse. I also prove that it's better to do NO index maintenance than to do it wrong and that, if you're using REORGANIZE in a generic fashion, then your doing it wrong.
I DO have a 'Tube out there that proves that GUID Fragmentation is mostly because of people using REORGANIZE And, it's not just about GUID fragmentation. A lot of indexes fall into the very similar "even random distribution" pattern and REORGANIZE puts the screws to those, as well. Here's the link to the 'Tube. Like it says in the 'tube, it's not just about GUIDs. We're just using those because they're the "poster child" for index fragmentation.
https://www.youtube.com/watch?v=rvZwMNJxqVo
In other words, the 5/30 method is actually a WORST practice. On April 2oth of 2021, even Microsoft changed the page where the 5/30 myth was published on. What they replaced it with is just as bad because no one has the time to manually evaluate every one of the indexes. I've pretty much got that beat, as well... I'm just not ready to publish it yet.
I'll also tell you that defaulting to a 90% FILL FACTOR is nearly a complete waste. You're just wasting space for most of your "ever increasing" indexes that fragment in the hot-spot and for the rest because you're using REORGANIZE.
In the meantime, stop killing yourself with index maintenance every night and just rebuild stats that need it. You may see an improvement right away because you won't actually be perpetuating and making your page splits worse every day. If you want to do index maintenance, then only do it for space recovery or to selectively prevent fragmentation on evenly distributed fragmenting indexes until you know a lot more about the individual indexes.
I did zero index maintenance on my production box for 4 years without performance issue. In fact, performance got a little better each day for the first 3 months. I don't recommend you go that long without some "space recovery" of low page density indexes but I wanted to let you know that I do practice what I preach. I also NEVER use REORGANIZE on rowstore indexes because I DO know what is does and does not do.
As for your occasionally slow code...
It's not TempDB. It sounds like it could be a form of parameter sniffing. You're going to have to bite the bullet and ad some code that reports how long and how many reads each section took unless you can somehow catch an "actual" execution plan for it.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
hi folks
really appreciate the feedback here guys, although i am now in a state of, what the hell do i do now - which is no bad thing, lets revise what i know, and start again!
is there a guide out there that you guys would recommend so that i could start to get indexing basics right? i have obviously been reading to many generic posts !
mal
-
My opinion - there is a TON to learn. Heck, I know very little about SQL. Every time I think I know something, someone posts something that contradicts what I thought I knew. Then I do my own research and try to find out what is "true" in my specific scenario. I've read things that I think "no way that is true..." then I test it and learn I was wrong. One example is if you create a table that is 100% empty, 0 rows, how many rows would the query optimizer estimate are in the table? Statistics should say 0, so I thought "it HAS to be 0, right?" but nope - it estimates 1 row. Which means that if you do something like selecting a distinct result set from the table, you get the seek plus a sort and a filter all happening in the execution plan. Obviously not the most optimal plan for a table with 0 rows, or even with 1 row, but the query optimizer gave that plan back to me.
But I 100% agree with Jeff about the random slowness - 90% of the time that is related to parameter sniffing and if it is a single stored procedure that goes slow, then you could look at adding some query options such as "OPTIMIZE FOR UNKNOWN" if the parameters are rarely the same between SP runs. If the parameters are USUALLY a specific value, then you can change that to optimize for a known common value. The other 10% of the time I see random performance issues is due to OS level issues (scheduled process kicks off like the antivirus or check disk or defrag), autogrow kicks in (this is a slow operation, so if possible, it is better to pre-grow), autoshrink is turned on (this should VERY RARELY be on... there are some use cases, but they are rare), or blocking. All of these are pretty easy to fix, but you first need to determine the cause of the random slowness.
My first steps to determine issues with random slowness is to look at what is the cause of the slowness. If it is a scheduled process, you will notice a pattern when it is slow such as at 1 PM on Tuesdays it is slow, then it is likely a scheduled process. If it is 100% random, then I'd be looking at autogrow, autoshrink, and blocking. If you have a SQL monitor tool (such as RedGate SQL Monitor, there are others, that is just the one I use), then you can see long blocking queries and can take appropriate action.
Now as for what to read, there is a LOT... My preference is this site! There is a ton of good, quick articles you can read about things. Otherwise, there are a TON of bloggers out there with tons of good info. Brent Ozar and Pinal Dave are big ones in my mind, but I know there are tons out there. Other things you can look at are looking at the official Microsoft documentation (often referred to as "BOL" or "Books online" as that was the name of that stuff from AGES back). What is fun though is that advice for SQL 2008 may be different than 2012 or 2022... Like if you asked me how you watch what is running on your SQL instance, in 2008 R2 I'd say profiler, but for 2022 I would say extended events. Both support XE (extended events), but they improved a lot in since 2008 R2... now that being said, I still load up Profiler when connecting to 2017 as I find it "faster". On the other hand, I would be hesitant to turn on either of those on a "busy" production box as they do have a performance hit.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - dopydb wrote:
hi folks
really appreciate the feedback here guys, although i am now in a state of, what the hell do i do now - which is no bad thing, lets revise what i know, and start again!
is there a guide out there that you guys would recommend so that i could start to get indexing basics right? i have obviously been reading to many generic posts !
mal
Right now is a bit of a "transition" period in the world of SQL Server Index Maintenance. That's the polite way of saying that most of the world is still stuck on doing it the wrong way using the classic 5/30 method. There's also virtually no documentation on what effects REORGANIZE actually has on data in tables except in the Microsoft Documentation and it leaves a whole lot to be desired as does the 20 April 2021 update to where the old 5/30 documentation used to be provided. It does have one thing right, though... in the absence of all other information, only rebuild indexes where it has been clearly demonstrated in-situ that it helps performance and it's not just because of the fact that a REBUILD also rebuilds the stats with the equivalent of a FULL SCAN.
To start with, shift to just rebuilding stats. Once per week should be more than enough, in most cases. Personally, I don't shortcut... I use FULL SCAN, always.
Then, look for indexes that have an average page density of something less than 82 and only rebuild them to recover space and only if it's actually worth it (I just rebuilt one to recover a quarter Tera Byte and that wasn't affecting performance or memory because only the 'hot-spot" at the end of the index was actually being used).
One of the best introductions to indexes and "index fragmentation" and page splits I've seen is by none other than Paul Randal. Here's the link to his the presentation that he did for PASS years ago. All of the information is still pertinent. Seriously, this is a "must see", especially for newbies but also for pros as an awesome refresher.
https://www.youtube.com/watch?v=p3SXxclj_vg&t=3275s
Th only problem with a reduced Fill Factor is when it comes to indexes with "Ever Increasing Keys"... A typical pattern is to do an INSERT, which goes into the end of the index at (ultimately) 100%, leaving no room because it ignored the Fill Factor. Then, someone does an "ExpAnsive" UPDATE, cause a row or a few rows to grow and, WHAM!!! Massive fragmentation. Lowering the Fill Factor on such indexes is a complete waste of time and space... so figure out what those are and RBUILD them using a 97% Fill Factor so that you know what they are in the future just by looking at the Fill Factor.
If you haven't watched the 'tube of mine that I provided a link for, watch that because it's not just about GUIDs. Watch Paul's tube first, though.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
guys, thanks so much for the replies and detail given. time for me to renew some knowledge (Busy IT Manager/Jack of all trades/Master of none issue)
think i eventually got my issue though, the application used to post specific transactions actually uses an Erp license per active .net call to the application, busy times, more people logged in, more transactions, end result application waits for free licenses - old architecture that needs pulled down and rebuilt!
i have now cancelled the nightly index rebuilds/reorgs, but will keep the stats updated at the weekend. until i get this right and get time to read your posts correctly and listen to the links,
your gents for being willing to share so much! funny how 1 conversation has moved onto something else, and now i have another job to do 🙂
thanks
MAl


Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply