Tally OH! An Improved SQL 8K “CSV Splitter” Function
-
I'd prefer to split the file normally, with simple delimiter '|'.
After it's done we can manipulate the resulting data set to shuffle the items into proper slots, defined by the given key words.
Here is my quick and nasty attempt on code:
DECLARE @FileString nvarchar(8000)
SET @FileString= '|System| |Sean Colley|06/02/2015 05:28:55 PM|New entry created.|User|NTCLSC04|Sean C|06/02/2015 05:41:25 PM|recd atty rep letter from Char Rosaa Jr with Rosaxx, Xmnnnd & XXXmilia 999-999-5572 999-998-4870 fax misc details unknown.|System| |Tiffany H|06/03/2015 07:21:13 AM| status change.|User|COCLTH03|Tiffany H|06/03/2015 07:34:48 AM|attempted contact with any office. 999-998-5572 place was closed.|User|COCLTH03|Tiffany H|07/01/2015 07:41:22 AM|attempted contact with any office. |System| |Chrystal R|10/21/2015 03:52:40 PM|Reassigned by Chrystal from Tiffany to John .|User|COCLJD02|John D|12/05/2015 04:47:40 PM|Police were called on 8/14/13 -sent papers to Supe for approval|User|COCLJD02|John D|01/03/2016 10:22:58 PM|EOR returned to from post officer |User|COCLJD02|John D|01/03/2016 10:40:04 PM| - including recorded statement: attempts made Confirmed date Recommendation: |Supervisor| |Gale D|01/04/2016 09:34:55 AM|Agree to proceed with the process.|User|COCLJD02|John D|01/05/2016 11:37:29 PM|EOR has been reissued to returned to sender|User|COCLJD02|John D|01/05/2016 11:40:57 PM|Sent notice of explanation |System| |John Difranco|01/05/2016 11:41:57 PM|Closed.'
SELECT RowNo,
ROW_NUMBER() OVER(PARTITION BY T.RowNo ORDER BY D1.ItemNumber) ItemNoInRow,
D1.Item
FROM
(
select ROW_NUMBER() OVER(ORDER BY D.ItemNumber) RowNo, *
, LEAD(D.ItemNumber, 1,1) OVER(ORDER BY D.ItemNumber) - 1 EndItemNumber
from [dbo].[DelimitedSplit8K_LEAD] (@FileString, '|') D
INNER JOIN (select N'Supervisor' UNION
select N'Contact' UNION
select N'Manager' UNION
select N'Note' UNION
select N'User' UNION
select N'System') V (CodeWord) ON D.Item = V.CodeWord
) T
INNER JOIN [dbo].[DelimitedSplit8K_LEAD] (@FileString, '|') D1
ON D1.ItemNumber >= T.ItemNumber AND D1.ItemNumber < ISNULL(NULLIF(T.EndItemNumber , 0), 8000)If I would not be so lazy, I might have created a temp table for the splitting result, to avoid double call of the function.
_____________
Code for TallyGenerator - Sergiy wrote:
I'd prefer to split the file normally, with simple delimiter '|'.
After it's done we can manipulate the resulting data set to shuffle the items into proper slots, defined by the given key words.
Here is my quick and nasty attempt on code:
DECLARE @FileString nvarchar(8000)
SET @FileString= '|System| |Sean Colley|06/02/2015 05:28:55 PM|New entry created.|User|NTCLSC04|Sean C|06/02/2015 05:41:25 PM|recd atty rep letter from Char Rosaa Jr with Rosaxx, Xmnnnd & XXXmilia 999-999-5572 999-998-4870 fax misc details unknown.|System| |Tiffany H|06/03/2015 07:21:13 AM| status change.|User|COCLTH03|Tiffany H|06/03/2015 07:34:48 AM|attempted contact with any office. 999-998-5572 place was closed.|User|COCLTH03|Tiffany H|07/01/2015 07:41:22 AM|attempted contact with any office. |System| |Chrystal R|10/21/2015 03:52:40 PM|Reassigned by Chrystal from Tiffany to John .|User|COCLJD02|John D|12/05/2015 04:47:40 PM|Police were called on 8/14/13 -sent papers to Supe for approval|User|COCLJD02|John D|01/03/2016 10:22:58 PM|EOR returned to from post officer |User|COCLJD02|John D|01/03/2016 10:40:04 PM| - including recorded statement: attempts made Confirmed date Recommendation: |Supervisor| |Gale D|01/04/2016 09:34:55 AM|Agree to proceed with the process.|User|COCLJD02|John D|01/05/2016 11:37:29 PM|EOR has been reissued to returned to sender|User|COCLJD02|John D|01/05/2016 11:40:57 PM|Sent notice of explanation |System| |John Difranco|01/05/2016 11:41:57 PM|Closed.'
SELECT RowNo,
ROW_NUMBER() OVER(PARTITION BY T.RowNo ORDER BY D1.ItemNumber) ItemNoInRow,
D1.Item
FROM
(
select ROW_NUMBER() OVER(ORDER BY D.ItemNumber) RowNo, *
, LEAD(D.ItemNumber, 1,1) OVER(ORDER BY D.ItemNumber) - 1 EndItemNumber
from [dbo].[DelimitedSplit8K_LEAD] (@FileString, '|') D
INNER JOIN (select N'Supervisor' UNION
select N'Contact' UNION
select N'Manager' UNION
select N'Note' UNION
select N'User' UNION
select N'System') V (CodeWord) ON D.Item = V.CodeWord
) T
INNER JOIN [dbo].[DelimitedSplit8K_LEAD] (@FileString, '|') D1
ON D1.ItemNumber >= T.ItemNumber AND D1.ItemNumber < ISNULL(NULLIF(T.EndItemNumber , 0), 8000)If I would not be so lazy, I might have created a temp table for the splitting result, to avoid double call of the function.
Yep. That's my preference as well and why I wrote the code the way I did. It turns out that you can use BULK INSERT to the splitting very quickly, as well. You just need to deal with the extra delimiter at the beginning of the file and that's just as easy... just don't use the first row that's returned from that.
If that first delimiter wasn't there, there would be no need for any post work to pivot things because there's a very nice and consistent 5 items per computational row to be split.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
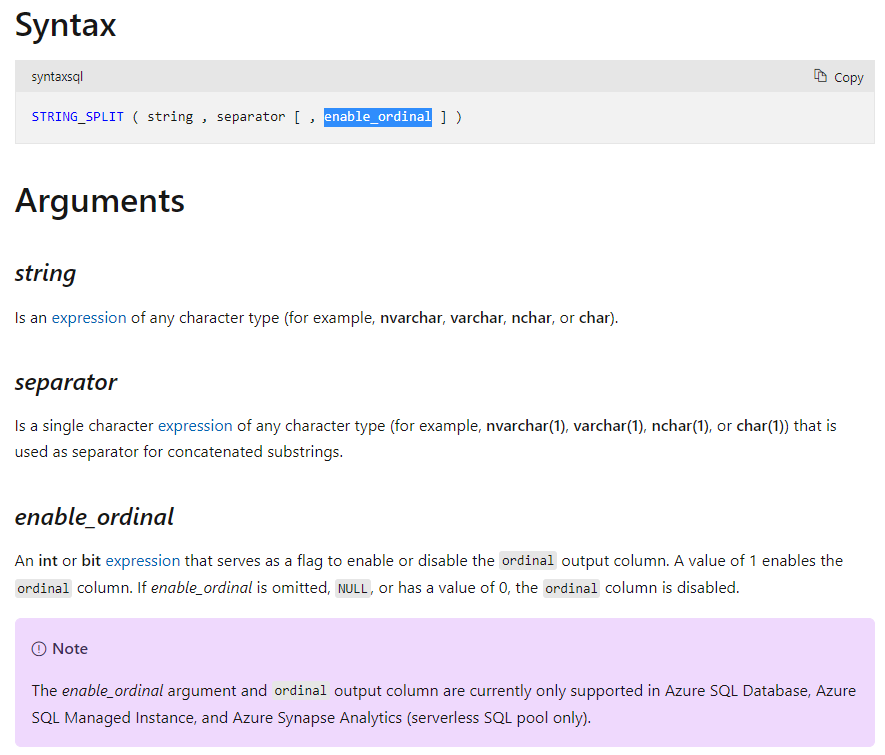
SQL Server now, at last, has added an addition (enable_ordinal) parameter to the STRING_SPLIT function.
This returns a column called ordinal the same value as the ItemNumber column in DelimitedSplit8K

This is currently only available in Azure but future versions of SQL Server might include it
-
I saw that and was totally impressed. It only took them 5 years to get a fix out... kind of. As you say, it's only in Azure so far. 😀
Once it hits the "on-premise" world, I'll certainly be testing it for both functionality and performance, though we already know that it's going to (IMHO) fail the functionality test just like the original did in that it's not going to return a NULL if you pass it a NULL.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
I saw that and was totally impressed. It only took them 5 years to get a fix out... kind of. As you say, it's only in Azure so far. 😀
Once it hits the "on-premise" world, I'll certainly be testing it for both functionality and performance, though we already know that it's going to (IMHO) fail the functionality test just like the original did in that it's not going to return a NULL if you pass it a NULL.
I'm sure your input has helped them change their mind on adding that functionality.
-
I doubt it. The still haven't made a built in sequence generator even though I've added to Erland Sommarskogs "Connection" post that he created more than a decade ago (going on 14 years IIRC).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
This was new news to me. We're using Azure SQL and I confirmed it works (tested at Compatibility Level 150). Since the input argument "string is an expression of any character type" it must be able to handle nvarchar(max) blobs too. Maybe it won't be as quick as 8k/4k versions. As far as language additions generally in SQL Server 2022 it appears to be a big donut. There are some performance enhancement/optimization things but no new syntax afaik
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
I wonder if instead of using literal number 8000, you could limit the number of rows in the first CTE
to count the number of delimiters in the string, but adding one for the last substring that doesn't have a
terminating delimiter.
to SELECT
@count = LEN(@string) - LEN(
REPLACE(
@string,
@character,
''
)
or SELECT
@count = DATALENGTH(@string) - DATALENGTH(
REPLACE(
@string,
@character,
''
)
- Henry B. Stinson wrote:
I wonder if instead of using literal number 8000, you could limit the number of rows in the first CTE
to count the number of delimiters in the string, but adding one for the last substring that doesn't have a
terminating delimiter.
to SELECT @count = LEN(@string) - LEN( REPLACE( @string, @character, '' )
or SELECT @count = DATALENGTH(@string) - DATALENGTH( REPLACE( @string, @character, '' )
You don't really need to because CTEs don't materialize one at a time because there's no "blocking operator" in any of them. They're considered to be a part of one query.
I have done 4 way CTEs (256 place base) that have a TOP of the 4th root +1 of the total desired number. It wasn't the fact that they all produced the same number of rows that helped so much. That fact that it only created 3 nested loops instead of 31 (like the typical cascading CTEs do for this) helped a little. It does, however, make for an easier to read execution plan.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Henry B. Stinson wrote:
I wonder if instead of using literal number 8000, you could limit the number of rows in the first CTE
to count the number of delimiters in the string, but adding one for the last substring that doesn't have a
terminating delimiter.
to SELECT @count = LEN(@string) - LEN( REPLACE( @string, @character, '' )
or SELECT @count = DATALENGTH(@string) - DATALENGTH( REPLACE( @string, @character, '' )
You don't really need to because CTEs don't materialize one at a time because there's no "blocking operator" in any of them. They're considered to be a part of one query.
I have done 4 way CTEs (256 place base) that have a TOP of the 4th root +1 of the total desired number. It wasn't the fact that they all produced the same number of rows that helped so much. That fact that it only created 3 nested loops instead of 31 (like the typical cascading CTEs do for this) helped a little. It does, however, make for an easier to read execution plan.
I know that plan well. Starting out with 256 values instead of using powers of 2 reduces the number of cross joins to 3, which are the nested loop operators in the plan. Like Jeff said, it's easier to read, but the performance is also there, so it's worth it. I've tested this from SQL 2012 to SQL 2019 and it holds true.
- Henry B. Stinson wrote:
I wonder if instead of using literal number 8000, you could limit the number of rows in the first CTE
to count the number of delimiters in the string, but adding one for the last substring that doesn't have a
terminating delimiter.
to SELECT @count = LEN(@string) - LEN( REPLACE( @string, @character, '' )
or SELECT @count = DATALENGTH(@string) - DATALENGTH( REPLACE( @string, @character, '' )
BTW, thanks for the thought provoking suggestion. I appreciate it.
I'll also tell you (from a lot of previous testing) that using a REPLACE or concatenation does slow things down quite a bit.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I converted Jeff's algorithm for determining ISO dates to Oracle, but it was only a matter of translating the algorithm. In the case of the splitter, the purpose was not to create a splitter but to determine the most efficient way to split a large string and handle edge cases using a set based operation. I guess you know you are going to need a lot of time for this.
-
I apologize... that last post slipped right past me. I know it's been a couple of months but thank you for the feedback on the ISO algorithm. Also, I thought that Oracle had a pretty good built in splitter function.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Steve Jones - SSC Editor wrote:
Thanks, Steve. I've been doing that same thing for years to create "character usage histograms" using either a Tally Table or fnTally. So has Itzik with his "GetNums" function. The only think new here is the word "GenerateSeries". 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 976 through 990 (of 991 total)
You must be logged in to reply to this topic. Login to reply