SQL Duplicate remove Query
-
Hi Guys,
I want to remove duplicates from the table. The duplicate is a typo in the first and last name.
Here is the sample script
CREATE TABLE test_dup(
f_name nvarchar(20)
,l_name nvarchar(20)
,statenvarchar(20)
)
INSERT INTO dbo.test_dup
(
f_name,
l_name,
state
)
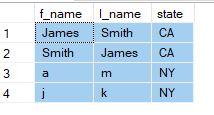
SELECT 'James','Smith','CA'
UNION all
select 'Smith','James','CA'
UNION all
select 'a','m','NY'
UNION all
select 'j','k','NY'
select * from dbo.test_dupHere is the sample data

Here is what I want. (Only three records)
f_name,l_name,state
James,Smith,CA
a,m,NY
j,k,NY
Please let me know how can I accomplish this.
Thanks.
-
Given that
- You've named a specific row to exclude and not business rules;
- Those are not really duplicates;
- There is no inherent way to determine which is truly a first name and which is truly a last name;
- There is almost certainly more than one James Smith in California, so the table design does not seem to allow for reality...
Just exclude the row you named:
SELECT * FROM dbo.test_dup
WHERE state = 'CA'
AND NOT (f_name = 'Smith' AND l_name = 'James')You haven't provided business rules for excluding such duplicates systematically, so given you've named only one case you want to exclude, exclusively exclude it.
Otherwise, you need to explain what defines a duplicate? On what basis do you choose what to keep and which to exclude?
-
+1000 to ratbak on this one.
I'll also state that since you KNOW this is a type-0, why don't you submit a script to management to actually fix the bad data instead of allowing it to continue in such a fashion? And, yeah... if you have to notify the user, DO IT! Do it right. Stop perpetuating the need for such workarounds that are doomed to failure.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
How would the computer know that 'James' is the first name and 'Smith' is a last name?
You might be better just creating a script to delete the specific rows, then you can manually decide which is first and which is last.
Some people have names where their first name is a valid surname and their surname a valid first name, so I would use a manual check.
This SQL might help:
;with cte as
(
select *, case when a.f_name < a.l_name then a.f_name + a.l_name else a.l_name + a.f_name end as srt
from (select a.f_name, a.l_name, a.state
from dbo.test_dup a
union all
select a.l_name, a.f_name, a.state
from dbo.test_dup a
) a
group by a.f_name, a.l_name, a.state
having count(*) > 1
)
SELECT 'DELETE dbo.test_dup WHERE f_name = ''' + a.f_name + ''' AND l_name = ''' + a.l_name + ''' AND state = ''' + a.state + ''';'
FROM CTE a
order by srtYou just need to decide which of each pair of rows you need to keep.
-
Here is the SQL script, if someone is looking for a solution.
select top 1 t.*
From test_dup src
join test_dup t on src.f_name = t.l_name
and src.l_name = t.f_name
and src.state = t.state
union
select src.*
From test_dup src
left join test_dup t on src.f_name = t.l_name
and src.l_name = t.f_name
and src.state = t.state
where t.f_name is null
and t.l_name is null and t.state is null -
WARNING! BEFORE YOU USE THE CODE LISTED ABOVE, PLEASE READ THE FOLLOWING!
If someone is looking for a code solution to ignore duplicates then, sorry, the code above shouldn't be it. You will end up leaving out people that have legitimate names.
For example, I have a very good friend on this very site by the name of Michael John. I also have a work acquaintance whose name is John Michael.
If you have known "typo's", then fix the data instead of making this terrible mistake.
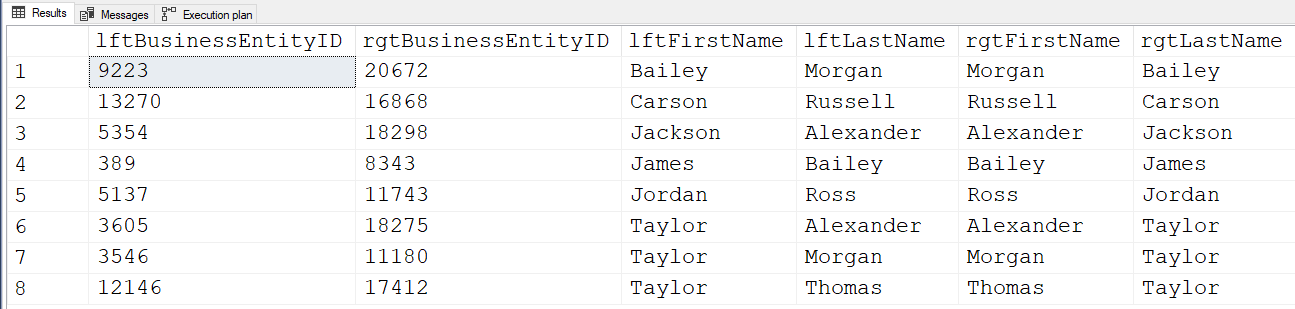
To check for possible such typo's as candidate rows that need manual verification, then do something like the following (I played this against the AdventureWorks database) and then manually verify whether or not the entries are correct or not You might even want to add a HasBeenVerified column to your table so they don't show up in such validation queries in the future.
Here's the code...
SELECT lftBusinessEntityID = lft.BusinessEntityID
,rgtBusinessEntityID = rgt.BusinessEntityID
,lftFirstName = lft.FirstName
,lftLastName = lft.LastName
,rgtFirstName = rgt.FirstName
,rgtLastName = rgt.LastName
FROM person.Person lft
JOIN person.Person rgt
ON lft.FirstName = rgt.LastName
AND lft.LastName = rgt.FirstName
AND lft.BusinessEntityID < rgt.BusinessEntityID
ORDER BY lftFirstName,rgtLastName
,lftLastName ,rgtFirstName
;... and here's the output from that code...
ALL of those First/Last name combinations are valid and common name combinations. Ignoring any of them with your code can be a serious mistake on your part. You MUST manually verify which ones are valid and FIX the ones than aren't.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply