SQL 2016 alwayOn AG failover failure when primary site went down
-
Hi,
I have an issue that happened during a disaster testing.
The setup is the following.
2 sites geographically separated with AD on both sites replicated between
SQL 2016 AlwaysOn Availability group setup with synchronous commit
Primary sql server on site 1
Secondary sql server on site 2
File share witness on a file server on site 2.The disater exercise looked as follows:
The power to site 1 was cut off. The AD on site 2 took over the domain responsibilities. All applications worked well with only one site available. Except for the SQL servers in the AlwaysOn setup.
The databases on server 1 went down but no failover was done.When the disaster exercise was over and power to site 1 was turned on the dbs were available again.
So I wonder
- Is this how it should work? Or is it some config that needs to be fixed?
- Shouldn't a failure like this (one site is lost) trigger an automatic failover of AG to the other db server on the other site?What am I missing?
If you have any input or you could point me to a resource for me too check, I would really appreciate it.
Thanks,
rico
-
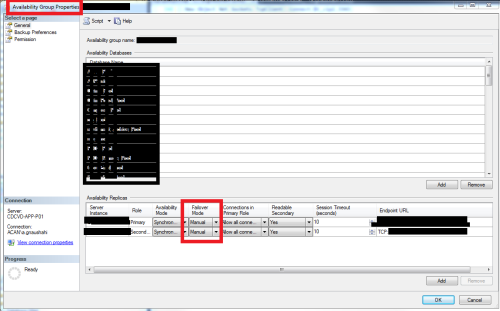
check ag group properties

-
Thanks for the tip but it is already set to automatic.
So the questions are:
- When the server goes down, the AG fails over to node 2.
- But what should happen if all primary site goes down? Should the AG failover to site 2? Is this how it works? Or is it that in this case no failover will occur?rico
-
Start from cluster level, the cluster went down after site 1 had gone down? If not what was DBs and replica state, for automatic failover they should be Synchronized, you can check this on report or in DMV
select * from sys.dm_hadr_database_replica_states
select * from sys.dm_hadr_availability_replica_states
column is_failover_ready in sys.dm_hadr_database_replica_cluster_states should be 1 for databases that can failover -
Thanks, but this happened a few days ago so I can't see the status from then. The dbs and AGs are up and running right now.
I'm troubleshooting the incident.I try to understand the underlying functionality of a cluster to see if it's by design or actually a failure.
As I have understood, the network has to be seen by both nodes in the cluster, is that correct?
So in my case when all site 1 was lost then the databases in the AG went down because the node 1 in site 1 could not see the network and therefore it didn't attempt to failover. Is this correct?/rico
- ricfors - Tuesday, October 16, 2018 10:46 AM
The secondary replica should have transitioned to the resolving state, was the group synch state healthy when the failure occurred?
-----------------------------------------------------------------------------------------------------------
"Ya can't make an omelette without breaking just a few eggs" 😉
-
I don't know the state it was before the disaster test. I was involved after, when everything was back up again and working.
Can I check that afterwards?/rico
-
What errors do you have in error log? There should be many errors and information regard this failover that will tell if this was cluster fault or some synchronization errors in SQL.
-
Was the primary replica shut down gracefully or was the power cable yanked out, or something? The reason I ask is that it surprised me a few years ago to learn that a graceful shutdown of the primary replica (i.e. when the services are stopped cleanly) does not trigger an automatic failover. I really thought it would.
- Beatrix Kiddo - Friday, October 19, 2018 4:26 AM
The power was cutoff to the whole site.
/rico
- e4d4 - Friday, October 19, 2018 3:50 AM
In the windows eventlog - Applications and Services Logs - Microsoft - Windows - FailoverClustering - Operational
First it says
- Cluster has missed two consecutive heartbeats for the local endpoint 127.0.0.1 connected to remote endpoint 127.0.0.1
- Cluster has lost the UDP connection from local endpoint 127.0.0.1 connected to remote endpoint 127.0.0.1Then it goes on
- Cluster resource 'File Share Witness' in clustered role 'Cluster Group' has transitioned from state Online to state ProcessingFailure.
and goes through all the stages
from state ProcessingFailure to state WaitingToTerminate
to state Terminating
to state DelayRestartingResource
to state OnlineCallIssued
to state WaitingToTerminate
to state Terminating
to state Failed
The Cluster service is attempting to fail over the clustered role 'Cluster Group' from node 'A' to node 'B'
... and then going through different states until
Clustered role 'Cluster Group' is moving to cluster node 'B'In the SQL server log it says
- A connection timeout has occurred on a previously established connection to availability replica 'B' with id [EF8F981F-BB63-4744-B058-75768896FF19]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
- Always On Availability Groups connection with secondary database terminated for primary database 'database1' on the availability replica 'B' with Replica ID: {ef8f981f-bb63-4744-b058-75768896ff19}.
... and repeats the same for all the databases in the AAG, which are 6.Then comes this
- SSPI handshake failed with error code 0x80090311, state 14 while establishing a connection with integrated security; the connection has been closed. Reason: AcceptSecurityContext failed. The Windows error code indicates the cause of failure. No authority could be contacted for authentication. [CLIENT: xx.xx.xx.xx]
- SSPI handshake failed with error code 0x80090311, state 14 while establishing a connection with integrated security; the connection has been closed. Reason: AcceptSecurityContext failed. The Windows error code indicates the cause of failure. No authority could be contacted for authentication. [CLIENT: yy.yy.yy.yy]
- Login failed. The login is from an untrusted domain and cannot be used with Windows authentication. [CLIENT: xx.xx.xx.xx]
- Login failed. The login is from an untrusted domain and cannot be used with Windows authentication. [CLIENT: yy.yy.yy.yy].. and repeats that until everything is back up again.
I can't find any information that the AAG group has failed over to the other node. Only the cluster group seems to have failed over. But not the AAG.
Is this a config error, a expected behavior? Shouldn't the AAG also fail over in this case? Can you clarify this, please
According to the latest errors the application couldn't connect to the database with windows authentication because it couldn't find it's domain controler. But I can't see if the application tries to connect to the AAG listener or if it's the server A.
So I'm really confused about the errors./rico
-
make sure the following
3434 tcp & udp ports are enabled between nodes..
135 tcp rpc port is open between nodes
137 udp port open between nodes
49152 - 65635 upd port range is open between nodes. (make sure this range is defined in component services > my computer properties > default protocol > connection-oriented TCP properties )
ICMP (ping) is open between nodes.check if you have adequate bandwidth available between nodes
The errors below are due to (1) either SPN is not set properly or (2) SQL is located in prod domain and client is trying to login using other domain e.g. dev\user and dont have access to sql (3) windows auth is disabled in sql
- SSPI handshake failed with error code 0x80090311, state 14 while establishing a connection with integrated security; the connection has been closed. Reason: AcceptSecurityContext failed. The Windows error code indicates the cause of failure. No authority could be contacted for authentication. [CLIENT: xx.xx.xx.xx]
- SSPI handshake failed with error code 0x80090311, state 14 while establishing a connection with integrated security; the connection has been closed. Reason: AcceptSecurityContext failed. The Windows error code indicates the cause of failure. No authority could be contacted for authentication. [CLIENT: yy.yy.yy.yy]
- Login failed. The login is from an untrusted domain and cannot be used with Windows authentication. [CLIENT: xx.xx.xx.xx]
- Login failed. The login is from an untrusted domain and cannot be used with Windows authentication. [CLIENT: yy.yy.yy.yy] -
I would check your quorum setup, it sounds like there weren't enough voting members to adequately vote to make the second site the primary. I typically recommend a file share witness that has nothing to do with either site or an Azure Cloud witness if on Windows 2016.
Owner & Principal SQL Server Consultant
Im Your DBA, Inc.
https://www.imyourdba.com/ - goher2000 - Friday, October 26, 2018 11:57 AM
Hi, the cluster is up and running fine.
All this happened while doing a disaster drill exercise. So the suggestions are not relevant in this case.
Thanks anyway./rico
- ImYourDBA - Friday, October 26, 2018 8:46 PM
Hi,
This is were I get stuck in trying to understand the cluster behavior.
The voting members are node 1, node 2 and quorum file share.
The file share is located on a 3rd server. This server with the file share is on site 2. The same goes for node 2 (replica server).
On site one was (and is) node 1 (primary server) with the AAG group. On this server, the "cluster group" was also active (this group contains the file share resource).When site 1 was cut off, the cluster group failed over to node 2 (on site 2). But the AAG did not. The connected sessions complained about not being able to access the db due to non-authorized domain.
So to me it sounds that something couldn't access the dns and/or the Domain controller. But the cluster group had no issues in failing over. So is this by design or what caused this behavior?I will propose to set up a file share for the quorum on a server in a site 3, if possible. But, the people responsible for their application would still want a explanation to why it happened. So there's my dilemma.
/rico
Viewing 15 posts - 1 through 15 (of 17 total)
You must be logged in to reply to this topic. Login to reply