Split column value to rows.
-
Hi All,
I was looking for code to split column value into separate rows..
Any help on this..
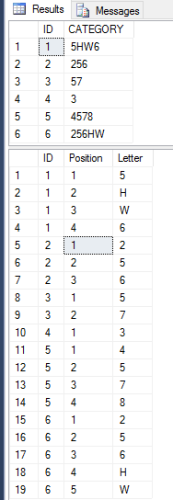
like for the example below , for ID =1 ,it should give 4 rows..like this
ID Category
1 5
1 H
1 W
1 6create table TEST
(
ID char(10),
CATEGORY VARCHAR(10)
)INSERT INTO TEST values(1,'5HW6')
INSERT INTO TEST values(2,'256')
INSERT INTO TEST values(3,'57')
INSERT INTO TEST values(4,'3')
INSERT INTO TEST values(5,'4578')
INSERT INTO TEST values(6,'256HW')SELECT * from TEST[font="Comic Sans MS"]
---------------------------------------------------Thanks [/font]
-
Try:
DECLARE @TEST table (ID int IDENTITY,CATEGORY VARCHAR(10));
INSERT @TEST (CATEGORY)
VALUES ('5HW6')
,('256')
,('57')
,('3')
,('4578')
,('256HW');
SELECT ID
, CATEGORY
FROM @TEST;
SELECT ID
, n Position
, Substring(t.CATEGORY, n, 1) Letter
FROM @TEST t
CROSS APPLY (SELECT n FROM (VALUES (1),(2),(3),(4),(5)) nums (n)) nums
WHERE n<=Len(t.CATEGORY)
- Joe Torre - Thursday, June 1, 2017 2:33 PM
Nice job, Joe. Other than the placement of the commas, it's about what I would have done. 😛
Mr. Learner, I don't think you're going to get much more efficient of an approach than this. I ran a test over 1.7M rows and it split them out in 29.2 seconds.
I was able to get it down to 22.7 seconds using Itzik's Tally function, called TallyN below.
Without actually returning the values (using a bit bucket instead) the times were 8166 ms vs. 7826 ms.I tried a couple of slightly different approaches and the results were largely the same.
Here's the test harness I put together for it.
--This table variable is only used to track the start and end time of each task as executed. Thanks for the approach, EE!
DECLARE @times TABLE (
task Varchar(32),
d Datetime);--Bit bucket variables to receive the values
DECLARE @id Integer,
@n Integer,
@char Varchar(1);--Approach #1
INSERT INTO @times(task, d) VALUES('Split', GETDATE());SELECT @id = ID, @n = n, @char = Substring(t.CATEGORY, n, 1)
FROM #TEST t
CROSS APPLY (SELECT n FROM (VALUES (1),(2),(3),(4),(5)) nums (n)) nums
WHERE n <= Len(t.CATEGORY);INSERT INTO @times(task, d) VALUES('Split', GETDATE());
--Approach #2
INSERT INTO @times(task, d) VALUES('TallyN', GETDATE());SELECT @id = ID, @n = t.N, @char = SUBSTRING(d.Category, t.N, 1)
FROM #test d
CROSS APPLY dbo.TallyN(5) t
WHERE t.N < LEN(d.Category);INSERT INTO @times(task, d) VALUES('TallyN', GETDATE());
--The time each approach took is the difference of the min and max for each task name
SELECT task, DATEDIFF(ms, MIN(d), MAX(d))
FROM @times
GROUP BY task;I hope I didn't go overboard, but I really enjoy this type of thing. 😉 There may, of course, be faster ways to do the same thing, but I think this is pretty good.
-
I'm not sure there's actually a substantial performance difference between the two methods.
Note that the TallyN query as written will always avoid doing the last letter of each category, because it's doing WHERE t.N < LEN(d.Category) instead of WHERE t.N <= LEN(d.Category)
I'd wager most of the performance improvement comes from avoiding that extra letter of work for each ID 🙂
EDIT:
As a followup, here's another method that seems to shave a bit of time off by only generating the rows we need in the CROSS APPLY, instead of potentially generating all 5 and rejecting some of them with the WHERE clause (I'm still playing around with this in my head and might test a couple other ideas, hence labeling it 'Jacob #1')
I've also noticed this one tends to go parallel, so you might want to throw in a MAXDOP 1 hint so the elapsed time metric isn't misleading. Even forcing them all serial this one consistently is measurably faster, though.
INSERT INTO @times(task, d) VALUES('Jacob #1', GETDATE());SELECT @id = ID,
@n = t.N,
@char = SUBSTRING(d.Category, t.N, 1)
FROM #TEST d
CROSS APPLY
(
SELECT TOP (LEN(Category)) n
FROM (VALUES(1),(2),(3),(4),(5))n(n)
ORDER BY n ASC
)t(n);INSERT INTO @times(task,d) VALUES ('Jacob #1', GETDATE());
Cheers!
- Jacob Wilkins - Thursday, June 1, 2017 4:44 PM
DOH! Well, that's embarrassing. Thank you for the good catch, Jacob. It really did make a difference in performance.
Jacob Wilkins - Thursday, June 1, 2017 4:44 PMNice work. That does indeed take it down significantly. With the fix to the TallyN in place, here's where it stands now.
Jacob #1: 3630
Split: 7470
TallyN: 8060I'm seeing some variability in trials of up to 500 ms or so.
-
I see a claim of working against 1.7 million rows. What does the data actually look like and what is the structure of the table that you're using for the test?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, June 1, 2017 5:39 PM
Hi Jeff. I made a test table and used 1.7M rows. I did some lower-volume testing, but kept adding to it over several rounds and ended up at 1.7M. I didn't start out with that number as a goal, but rather ended up there. It's on my laptop and I used tempdb.
Here's the table:
IF OBJECT_ID('tempdb.dbo.#test', 'u') IS NOT NULL DROP TABLE #test;
CREATE TABLE #test (
ID integer IDENTITY,
CATEGORY Varchar(10));And here's the mechanism to create the test data. I know I don't have to explain it to you, as it should look very familiar. 😉
INSERT INTO #test(Category)
SELECT SUBSTRING(CONVERT(CHAR(36),NEWID()),
ABS(CHECKSUM(NEWID()) % 16) + 1,
ABS(CHECKSUM(NEWID()) % 5) + 1)
FROM dbo.TallyN(100000); -
I see I forgot to define dbo.TallyN. It's Itzik's zero-read tally ITVF. I use it so much I sometimes think it's a part of SQL Server. It isn't, but it should be.
ALTER FUNCTION dbo.TallyN(@N Bigint) RETURNS TABLE WITH SCHEMABINDING
AS
--Credit: This function was written by Itzik Ben-Gan at http://sqlmag.com/sql-server/virtual-auxiliary-table-numbers
RETURN WITH level0 AS (
SELECT 0 AS g UNION ALL SELECT 0), --2
level1 AS (SELECT 0 AS g FROM level0 AS a CROSS JOIN level0 AS b), --2^2 = 4
level2 AS (SELECT 0 AS g FROM level1 AS a CROSS JOIN level1 AS b), --4^2 = 16
level3 AS (SELECT 0 AS g FROM level2 AS a CROSS JOIN level2 AS b), --16^2 = 256
level4 AS (SELECT 0 AS g FROM level3 AS a CROSS JOIN level3 AS b), --256^2 = 65536
level5 AS (SELECT 0 AS g FROM level4 AS a CROSS JOIN level4 AS b), --65536^2 = 4294967296
Tally AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS n FROM level5)
SELECT TOP (@N) N
FROM Tally
ORDER BY N; - Jacob Wilkins - Thursday, June 1, 2017 4:44 PM
Be careful with that order by clause, it will significantly slow down the query!
😎 -
Here is a simple test harness and the result set from my old i5 laptop
😎USE TEEST;
GO
SET NOCOUNT ON;DECLARE @SAMPLE_SIZE INT = 2000000;
DECLARE @MAX_CHARS INT = 5;
DECLARE @INT_BUCKET INT = 0;
DECLARE @CHAR_BUCKET VARCHAR(10) = '';
DECLARE @TIMER TABLE (T_TXT VARCHAR(20) NOT NULL, T_TS DATETIME NOT NULL DEFAULT (GETDATE()));/*
IF OBJECT_ID(N'dbo.TBL_SAMPLE_SPLIT_CHARS') IS NOT NULL DROP TABLE dbo.TBL_SAMPLE_SPLIT_CHARS;CREATE TABLE dbo.TBL_SAMPLE_SPLIT_CHARS
(
SSC_ID INT NOT NULL CONSTRAINT PK_DBO_TBL_SAMPLE_SPLIT_CHARS_SSC_ID PRIMARY KEY CLUSTERED
,CATEGORY VARCHAR(10) NOT NULL
);;WITH T(N) AS (SELECT X.N FROM (VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) X(N))
, NUMS(N) AS (SELECT TOP(@SAMPLE_SIZE) ROW_NUMBER() OVER (ORDER BY @@VERSION) AS N
FROM T T1,T T2,T T3,T T4,T T5,T T6,T T7,T T8,T T9)
INSERT INTO dbo.TBL_SAMPLE_SPLIT_CHARS(SSC_ID,CATEGORY)
SELECT
NM.N
,SUBSTRING(REPLACE(CONVERT(VARCHAR(36),NEWID(),0),CHAR(45),CHAR(65)),1,(ABS(CHECKSUM(NEWID())) % @MAX_CHARS) + 1)
FROM NUMS NM;
-- */INSERT INTO @TIMER(T_TXT) VALUES('DRY RUN');
SELECT
@INT_BUCKET = SSC.SSC_ID
,@CHAR_BUCKET = SSC.CATEGORY
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('DRY RUN');INSERT INTO @TIMER(T_TXT) VALUES('EE CROSS APPLY');
SELECT
@INT_BUCKET = SSC.SSC_ID
,@INT_BUCKET = NM.N
,@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY,NM.N,1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
CROSS APPLY (SELECT TOP(LEN(SSC.CATEGORY)) X.N FROM (VALUES (1),(2),(3),(4),(5)) X(N)) AS NM
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('EE CROSS APPLY');INSERT INTO @TIMER(T_TXT) VALUES('EE OUTER APPLY');
SELECT
@INT_BUCKET = SSC.SSC_ID
,@INT_BUCKET = NM.N
,@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY,NM.N,1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
OUTER APPLY (SELECT TOP(LEN(SSC.CATEGORY)) X.N FROM (VALUES (1),(2),(3),(4),(5)) X(N)) AS NM
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('EE OUTER APPLY');INSERT INTO @TIMER(T_TXT) VALUES('Jacob #1');
SELECT @INT_BUCKET = SSC.SSC_ID,
@INT_BUCKET = t.n,
@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY, t.N, 1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
CROSS APPLY
(
SELECT TOP (LEN(Category)) n
FROM (VALUES(1),(2),(3),(4),(5))n(n)
ORDER BY n ASC
)t(n)
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('Jacob #1');INSERT INTO @TIMER(T_TXT) VALUES('Jacob #2');
SELECT @INT_BUCKET = SSC.SSC_ID,
@INT_BUCKET = t.n,
@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY, t.N, 1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
CROSS APPLY
(
SELECT TOP (LEN(Category)) n
FROM (VALUES(1),(2),(3),(4),(5))n(n)
)t(n)
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('Jacob #2');SELECT
T.T_TXT
,DATEDIFF(MICROSECOND,MIN(T.T_TS),MAX(T.T_TS)) AS DURATION
FROM @TIMER T
GROUP BY T.T_TXT
ORDER BY DURATION ASC;Results
T_TXT DURATION
-------------------- -----------
DRY RUN 433334
EE OUTER APPLY 1663333
Jacob #2 1740000
EE CROSS APPLY 1750000
Jacob #1 21433333 - Ed Wagner - Thursday, June 1, 2017 4:04 PM
Using the LEN function in the WHERE clause is a killer here, slows the query down several times, much more efficient to use the TOP operator within the numbers CTE. The reason for this is that when using the former, the server will generate the full output of the CTE and then filter is applied afterwards whilst the TOP operator will limit the number generated.
😎Demonstration
USE TEEST;
GO
SET NOCOUNT ON;DECLARE @SAMPLE_SIZE INT = 2000000;
DECLARE @MAX_CHARS INT = 5;
DECLARE @INT_BUCKET INT = 0;
DECLARE @CHAR_BUCKET VARCHAR(10) = '';
DECLARE @TIMER TABLE (T_TXT VARCHAR(20) NOT NULL, T_TS DATETIME NOT NULL DEFAULT (GETDATE()));/*
IF OBJECT_ID(N'dbo.TBL_SAMPLE_SPLIT_CHARS') IS NOT NULL DROP TABLE dbo.TBL_SAMPLE_SPLIT_CHARS;CREATE TABLE dbo.TBL_SAMPLE_SPLIT_CHARS
(
SSC_ID INT NOT NULL CONSTRAINT PK_DBO_TBL_SAMPLE_SPLIT_CHARS_SSC_ID PRIMARY KEY CLUSTERED
,CATEGORY VARCHAR(10) NOT NULL
);;WITH T(N) AS (SELECT X.N FROM (VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) X(N))
, NUMS(N) AS (SELECT TOP(@SAMPLE_SIZE) ROW_NUMBER() OVER (ORDER BY @@VERSION) AS N
FROM T T1,T T2,T T3,T T4,T T5,T T6,T T7,T T8,T T9)
INSERT INTO dbo.TBL_SAMPLE_SPLIT_CHARS(SSC_ID,CATEGORY)
SELECT
NM.N
,SUBSTRING(REPLACE(CONVERT(VARCHAR(36),NEWID(),0),CHAR(45),CHAR(65)),1,(ABS(CHECKSUM(NEWID())) % @MAX_CHARS) + 1)
FROM NUMS NM;
-- */INSERT INTO @TIMER(T_TXT) VALUES('DRY RUN');
SELECT
@INT_BUCKET = SSC.SSC_ID
,@CHAR_BUCKET = SSC.CATEGORY
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('DRY RUN');INSERT INTO @TIMER(T_TXT) VALUES('EE CROSS APPLY TOP');
SELECT
@INT_BUCKET = SSC.SSC_ID
,@INT_BUCKET = NM.N
,@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY,NM.N,1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
CROSS APPLY (SELECT TOP(LEN(SSC.CATEGORY)) X.N FROM (VALUES (1),(2),(3),(4),(5)) X(N)) AS NM
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('EE CROSS APPLY TOP');INSERT INTO @TIMER(T_TXT) VALUES('EE OUTER APPLY TOP');
SELECT
@INT_BUCKET = SSC.SSC_ID
,@INT_BUCKET = NM.N
,@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY,NM.N,1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
OUTER APPLY (SELECT TOP(LEN(SSC.CATEGORY)) X.N FROM (VALUES (1),(2),(3),(4),(5)) X(N)) AS NM
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('EE OUTER APPLY TOP');INSERT INTO @TIMER(T_TXT) VALUES('EE CROSS APPLY WHERE');
SELECT
@INT_BUCKET = SSC.SSC_ID
,@INT_BUCKET = NM.N
,@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY,NM.N,1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
CROSS APPLY (SELECT X.N FROM (VALUES (1),(2),(3),(4),(5)) X(N)) AS NM
WHERE NM.N <= LEN(SSC.CATEGORY)
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('EE CROSS APPLY WHERE');INSERT INTO @TIMER(T_TXT) VALUES('EE OUTER APPLY WHERE');
SELECT
@INT_BUCKET = SSC.SSC_ID
,@INT_BUCKET = NM.N
,@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY,NM.N,1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
OUTER APPLY (SELECT X.N FROM (VALUES (1),(2),(3),(4),(5)) X(N)) AS NM
WHERE NM.N <= LEN(SSC.CATEGORY)
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('EE OUTER APPLY WHERE');INSERT INTO @TIMER(T_TXT) VALUES('Jacob #1');
SELECT @INT_BUCKET = SSC.SSC_ID,
@INT_BUCKET = t.n,
@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY, t.N, 1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
CROSS APPLY
(
SELECT TOP (LEN(Category)) n
FROM (VALUES(1),(2),(3),(4),(5))n(n)
ORDER BY n ASC
)t(n)
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('Jacob #1');INSERT INTO @TIMER(T_TXT) VALUES('Jacob #2');
SELECT @INT_BUCKET = SSC.SSC_ID,
@INT_BUCKET = t.n,
@CHAR_BUCKET = SUBSTRING(SSC.CATEGORY, t.N, 1)
FROM dbo.TBL_SAMPLE_SPLIT_CHARS SSC
CROSS APPLY
(
SELECT TOP (LEN(Category)) n
FROM (VALUES(1),(2),(3),(4),(5))n(n)
)t(n)
OPTION (MAXDOP 1);
INSERT INTO @TIMER(T_TXT) VALUES('Jacob #2');SELECT
T.T_TXT
,DATEDIFF(MICROSECOND,MIN(T.T_TS),MAX(T.T_TS)) AS DURATION
FROM @TIMER T
GROUP BY T.T_TXT
ORDER BY DURATION ASC;Results
T_TXT DURATION
-------------------- ---------
DRY RUN 470000
EE OUTER APPLY TOP 1640000
Jacob #2 1770000
EE CROSS APPLY TOP 1783333
EE OUTER APPLY WHERE 10510000
Jacob #1 16463333
EE CROSS APPLY WHERE 18526667 - Ed Wagner - Thursday, June 1, 2017 4:04 PM
No such thing as going overboard when doing fun stuff mate😉
😎 - Eirikur Eiriksson - Friday, June 2, 2017 6:38 AM
Heh - I agree. I was working through a slightly different idea, but won't be working on it until I get home tonight.
- Eirikur Eiriksson - Friday, June 2, 2017 2:22 AM
Indeed.
I kept it included because very strictly speaking there is no guarantee of correctness of the query without it.
To guarantee the query is correct, you have to know that the N returned for a string of length 3 will be 1,2, and 3.
Anything else would yield incorrect results.
As you did, I noticed that I seemed to get correct results every time without it, but without the ORDER BY, there's just no guarantee you'll get the right N from the APPLY.
Perhaps the engine will actually return them in the desired order under every possible circumstance, but I'm a paranoid DBA,so I couldn't bring myself to make that assumption 🙂
- Jacob Wilkins - Friday, June 2, 2017 8:18 AM
From a set based perspective, the order of appearance is irrelevant, the result set will be correct with or without the order by clause as the N will always correspond correctly to the position of the character returned. In fact, when using MAXDOP 1, the output is always appearing in the correct order although as you said, there is no guarantee that will always be so.
😎A greater culprit is not using the TOP operator, especially when handling greater variety of input length, the constant scan operator will feed the join operator maximum number of rows for every iteration.
Viewing 15 posts - 1 through 15 (of 27 total)
You must be logged in to reply to this topic. Login to reply