Slow deletes
-
Hi All,
I have table with 1574963 rows and grown up to 1.21 Tera Bytes. Table has a clustered idx and additional nonclustered idx is created.
App team is trying delete/archive some data in small chunks.
CREATE TABLE [dbo].[LogData](
[c1] [bigint] NOT NULL,
[c2] [int] NOT NULL,
[c3] [int] NOT NULL,
[c4] [ntext] NOT NULL, -->>
[c5] [int] NOT NULL,
[c6] [int] NOT NULL,
[c7] [int] NOT NULL,
[c8] [int] NOT NULL,
[c9] [int] NOT NULL,
[c10] [int] NOT NULL,
[c11] [nvarchar](255) NULL, -->>
[c12] [ntext] NULL, -->>
[c13] [int] NULL,
[c14] [bigint] NOT NULL,
[c16] [ntext] NULL, -->>
PRIMARY KEY CLUSTERED
(
[c1] ASC,
[c2] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
)
GO
CREATE NONCLUSTERED INDEX [AeLogDataPidInsId] ON [dbo].[AeProcessLogData]
(
[c3] ASC,
[c1] ASC,
[c5] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
Questions)
1) App team managed has to delete 1 million records, but when we trying to shrink the data file, the space is not getting released to OS. Why? how to reclaim the space?
2) The deletes are VERY VERY SLOW ... Anyone explain why DELETE's are slow?
Thanks,
Sam
-
I suspect the ntext fields are why it's slow. it's not a huge number of rows, but quite a high data size... I am guessing here
as for reclaiming the space back, i've had similar issues - first step - try DBCC Cleantable
I can't remember who helped me last time - i think it was Jeff moden- he'll crack this as quick as a flash
MVDBA
-
Sam
Space from deleted data is not automatically released to the operating system. You have to shrink the data files to get the space back.
Please post the code that your App team is using to do the deletes.
John
-
Hi John
the original poster mentioned "when we trying to shrink the data file, the space is not getting released to OS. Why? how to reclaim the space?"
my understanding is that the shrink is not working. is that correct sam?
MVDBA
-
As for the queries being slow, check out the execution plan to see how the deletes are being derived by the optimizer. It's possible to tune deletes (sometimes). You may need to reduce the size of the chunk in order to make better use of the index or something. Hard to know without seeing the plan.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
my advice
script it as delete 50 records then go for 500, then 5000 etc
time them and figure out your economy of scale.
MVDBA
- MVDBA (Mike Vessey) wrote:
Hi John
the original poster mentioned "when we trying to shrink the data file, the space is not getting released to OS. Why? how to reclaim the space?"
Oh yes, that's right. I'll read it properly next time!
John
- vsamantha35 wrote:
1) App team managed has to delete 1 million records, but when we trying to shrink the data file, the space is not getting released to OS. Why? how to reclaim the space?
2) The deletes are VERY VERY SLOW ... Anyone explain why DELETE's are slow?
For Item 1 Above
- By row count, what percentage of the file are you trying to delete? Contrary to what most will suggest, I've found that deleting more than about 25% of such a table even in small bites is usually the wrong way to go.
- Are there any foreign keys on the table that point to other tables? (I don't want to assume "No" even if it is a LogTable)
- Are there any foreign keys that point to the table? (Again, I don't want to assume "No" even if it is a LogTable)
- Are there any triggers on the table? (Again, I don't want to assume "No" even if it is a LogTable)
- I don't see a column with a temporal datatype in the table. Is there a column in the table that records the date (or date/time) of when the row was added to the table?
- What is the code currently being used to do the partial deletes?
- Shrinks may not work because the Deletes may not, in fact, be totally emptying pages. A single row of even 1 byte will prevent the data from being shrunk. And stop deleting until we're done figuring out and actually accomplishing the DELETEs. It's a waste of time to do otherwise and the shrinks might actually slow down the DELETEs because of index inversions.
For Item 2 Above
- We'll know more about that when you answer questions #2 and #6 above.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. And please provide answers to all of the questions I asked. All of them are important to this and the idea I have in my head to accomplish this much more quickly and without blowing up your log files, etc. It will also make your shrinks work.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
another question - it's so blindingly obvious that I forgot to ask.
when you are shrinking, are you using truncateonly in the dbcc script?
MVDBA
-
p.s.
And please don't skip answering any of the questions... they're actually quite important to all of this and the "plan" that I have in mind. One of the problems with this table is that it has a LOB column in it. Very fortunately, it has an Out-of-Row LOB (NTEXT) but that's also a problem with your shrinks. This would also be the right time to convert the super-deprecated NTEXT datatype to an NVARCHAR(MAX) but we also have to make sure that goes Out-of-Row or we'll screw the pooch for all range scans on this table and that will crush performance. Please don't try to make that conversion on your own because, unless you hold your mouth just right while doing so, it flat out won't work.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - MVDBA (Mike Vessey) wrote:
another question - it's so blindingly obvious that I forgot to ask.
when you are shrinking, are you using truncateonly in the dbcc script?
Great question, Mike.
I'm thinking that it's the Out-Of-Row NTEXT column that's causing the problem with the shrinks, though.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:MVDBA (Mike Vessey) wrote:
another question - it's so blindingly obvious that I forgot to ask.
when you are shrinking, are you using truncateonly in the dbcc script?
Great question, Mike.
I'm thinking that it's the Out-Of-Row NTEXT column that's causing the problem with the shrinks, though.
out of row data is always a pain
MVDBA
- MVDBA (Mike Vessey) wrote:Jeff Moden wrote:MVDBA (Mike Vessey) wrote:
another question - it's so blindingly obvious that I forgot to ask.
when you are shrinking, are you using truncateonly in the dbcc script?
Great question, Mike.
I'm thinking that it's the Out-Of-Row NTEXT column that's causing the problem with the shrinks, though.
out of row data is always a pain
A lot of people say that but that's only because they don't know what In-Row LOBS do to your Clustered Index, Page Density, and scan performance.
For example, it can cause super low page densities because of what I call "Trapped Short Pages". Because SQL Server forces a sort order in Clustered Indexes, In-Row Lobs that vary in width quite a bit can leave "Trapped Short Pages" that consist of single row pages that are trapped between two wide row pages. The rows on the "Trapped Short Pages" can be as short as a 7 byte row header and a single byte data type.
The other really bad part about In-Row LOBS is that they REALLY slow down range scans.
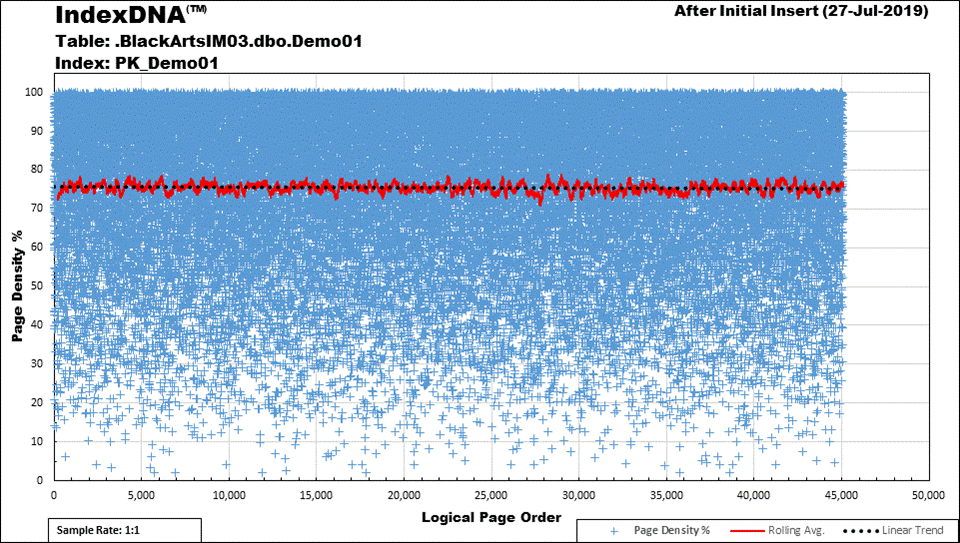
I have a presentation on the subject call "Black Arts" Index Maintenance #3: Defragmented by Default on the subject. Here's what the Page Density of such a thing looks like...

Each Blue Cross represents the Page Density (0 to 100%, see the X-Scale on the chart) of individual page for an In_Row usage of VARCHAR(MAX). You can see from the chart that this is after an "Initial Insert". What I've not stated on the chart is that this was a sequential single insert on a Clustered Index that has an "Ever-Increasing" Primary Key. It's a train wreck with many pages much less than 50% and a lot of pages that are even less than 10% full.
And, rather than post 3 identical charts, I'll tell you there were NO changes after a REORGANIZE or after a REBUILD (which doesn't affect LOBs anyway). Of course, there wouldn't be because the data was all inserted as a single INSERT.
Out-of-Row LOBs work MUCH BETTER than In-Row in all cases except 2...
1. Queries that use them (where they're so close to taking the same amount of time it's not worth mentioning the differences and are sometime faster than the In-Row stuff).
2. DELETEs (which leave gaping holes in the Out-of-Row pages that take multiple REORGS {up to 10 in my experiments} to shrink and that's why I'm setting up to use an alternate method for Sam's problem).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
interesting.. i'll have a read later.
one of the things we were taught(more than 20 years ago) was how to do capacity planning, how many rows per page, work out what was out of row etc etc - it seems to be a missing skill these days.
no one seems to care because we "just buy more disks"
we have a project on the go at the minute (not mine) and it's "code first" the database design it put out will not last a week
MVDBA
Viewing 15 posts - 1 through 15 (of 27 total)
You must be logged in to reply to this topic. Login to reply