Rows to Column
-
Hai all
I have one table one column. I have 10 rows that table .
I want output, segregate one column to three column rows accordingly
Create table #test(Sno int identity(1,1),Name varchar(20))
insert into #test values('one')
insert into #test values('two')
insert into #test values('three')
insert into #test values('four')
insert into #test values('five')
insert into #test values('six')
insert into #test values('seven')
insert into #test values('eight')
insert into #test values('nine')
insert into #test values('Ten')
I need following output
Column1-Column2-Column3
one-two-three
four-five-six
seven-eight-nine
ten
Please help me this query
-
You have no explicit column(s) by which the data can be you reliably ordered and grouped. You have no ID, date, or other criteria for ordering or grouping the data.
Your sample data uses names of numbers. That seems artificial/arbitrary. You seem to be relying on either the order of insert or that implied numeric order for grouping. Real data often isn't inserted in the order you want it output... and even then there's no guarantee it will be returned in that order.
Is it OK to group every three values, recognizing that SQL Server doesn't guarantee ordering, and may return them in a different order than they were inserted? (and therefore the grouping may not be in the implied numeric order) -- they could come back in random order.
I recommend you think about criteria you'd use (e.g., an integer column matching the numeric name in this situation, or perhaps a grouping number -- e.g., "one", "two", and "three" have GroupID 1, etc.) to predictably control ordering and grouping.
-
I agree with ratbak here. You need some way that SQL can order the data that makes logical sense.
One HUGE problem with using the names of numbers is that it forces you to use English for the numbers and SQL has no concept of "English" ordering. A second large, but not as huge, of a problem is what if you make a typo entering those numbers and you spell eight "eihgt" by accident? "eihgt" is not a valid number and someone searching through the database for "eight" MAY just think you missed it and add it themselves. Now you have both eight and eihgt in there. A third problem - what if you are inserting millions of records like this and you miss some? I would strongly encourage you not to use names of numbers for data like this unless it is absolutely needed for some business case.
My first step would be to add a column for ordering onto the source table. Something like ID INT IDENTITY(1,1).
Now you have numbered rows. Since we have this and we know we want 3 columns, next build a group ID by taking (ID-1) (as we want this to be 0 based) divided number of desired columns, in this case 3. Now Group ID can be used for the row! At this point, we have the Name column, an ID column and a Group ID column. Next, we need to give the final columns a name, so lets call them col# (col0, col1, and col2). Now, we need to make these, so lets do that by taking (ID-1) (again, to be 0 based) and modulo the desired number of columns, in this case 3.
So to write out those calculations:
GroupID = (ID-1)/3
ColumnID = 'col' + CAST((ID-1)%3 AS CHAR(4))
Now that we have this, our data is still 1 row per word plus 2 numeric columns (ID and GroupID) followed by ColumnID. Now, a quick pivot on ColumnID and you are good to go!
Limitations on the above - you have 3 calculated columns (ID, GroupID, and ColumnID) which depending on the usage will determine if it needs to be a persisted calculated column OR if you can get by with a nested select or common table expression or a view or whatever method works best for you. Another limitation is that PIVOT syntax is hard to remember and I try to avoid using it if I don't need to. Another limitation, if your requirements change and you need 4 columns or 2, it is an easy change, but the pivot and the calculations need tweaking. Final limitation I can think of is that due to the pivot, this is not very modular. What I mean is if you were to try to put the "3" into a parameter, you would need to do some dynamic SQL to make the PIVOT work nicely and that could get messy (and risky) pretty fast.
Now, all of the above being said, this sounds to me like a bit of a homework type assignment. If that is the case, we do not know what you have learned and what you haven't. Therefore if we offer advice using some obscure method for numbering or ordering the data or we make suggestions that violate the rules for the assignment, we don't know. For me, the ID column (INT IDENTITY(1,1)) is going to be the easiest approach. You could also use INT IDENTITY(0,1) and then not need to subtract 1 from ID from my above proposed solution. I just always forget with IDENTITY which is the starting value and which is the increment, so I tend to do 1,1 when I can easily work with either 0 or 1 as a starting point.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Thank you for your response. As per your request I added identity column in that table. Please help me.
-
Thank you for the readily consumable test data. Details for one solution are in the comments in the code below...
--===== One solution.
-- Note's: 1. ItemNum/3 creates a row number for the output "matrix".
-- 2. ItemNum%3 creates a row number for the output "matrix".
WITH cteEnumerate AS
(--==== ItemNum starts at ZERO and ensures there are no gaps like there may be in the IDENTITY column (Sno)
SELECT ItemNum = ROW_NUMBER() OVER (ORDER BY Sno)-1 --Guarantee No Gaps
,Name
FROM #Test
)--==== Then we do a simple "CROSS TAB" (some call it a PIVOT but it's usually faster than PIVOT)
-- to create 3 item rows in the correct order according to the ItemNum
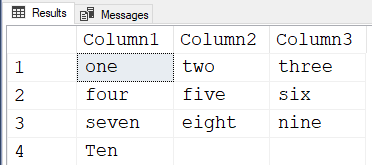
SELECT Column1 = MAX(CASE WHEN ItemNum%3 = 0 THEN Name ELSE '' END)
,Column2 = MAX(CASE WHEN ItemNum%3 = 1 THEN Name ELSE '' END)
,Column3 = MAX(CASE WHEN ItemNum%3 = 2 THEN Name ELSE '' END)
FROM cteEnumerate
GROUP BY ItemNum/3
ORDER BY ItemNum/3
;Results:

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply