Reorganising field in a table
-
Hi all
We've got some tables where the field order is .... odd.
We designed the tables but, through changes and ALTER TABLE ... ADD COLUMMN ... scripts (i.e. the customer wanted extra fields), the fields are in a non-alphabetical order.
Is there a way to reorganise the fields into alphabetical order without creating a new table and transferring all the data?
I tried to alter the ordinal position for the fields in INFORMATION_SCHEMA.COLUMNS but that's read-only.
We'd want to do this for a few hundred tables to doing them by hand would take forever.
Any ideas on this one would be greatly appreciated.
TIA
Richard
-
If I may ask why is it so important that they are in alphabetical order?
What's going to happen the next time an alter column is run and its an "N" column, it's not going to go in the middle of the table it's going to go to the end.
Each time you want to do it and you want them in alphabetical order you're going to have to create a copy of the table and pump the data into it.
But why go through the pain, there is no benefit at all to having columns in alphabetical order.
-
@ant-green - it was a request from the customer (to make the fields easier to find). If it was simple, then I'd go ahead and do it.
If it's going to painful, then ...... no.
As for adding new columns, that will be rare once the table is in production (the database is currently in DEV) and will need go through the usual DEV\QA process.
-
Well if it's dev deal with the pain but its a CREATE INSERT DROP RENAME process.
Otherwise don't do it, doing it is not trivial at all.
-
Thanks @ant-green - looks like that's not happening then (can't justify the time to get it done).
-
If you've got this all inside a VS database project, editing the .sql files for the tables and then Publishing does everything for you.
But behind the scenes, it is still generating CREATE TABLE/INSERT/DROP/RENAME statements for you.
-
@Phil - we haven't yet but we're working on that bit. It would still be painful, but not as bad as creating all the tables by hand, etc
- richardmgreen1 wrote:
@Phil - we haven't yet but we're working on that bit. It would still be painful, but not as bad as creating all the tables by hand, etc
Should be straightforward to import the database as a project into VS ... unless you have references to other databases, which complicates things.
Then edit using something like Notepad++ - it will do the alphabetic sorting for you.
-
Thanks for that. We use synonyms to refer to other databases so hopefully that shouldn't cause too many issues.
I'll give it a go with a test database and see how I get on.
- richardmgreen1 wrote:
Thanks for that. We use synonyms to refer to other databases so hopefully that shouldn't cause too many issues.
I'll give it a go with a test database and see how I get on.
it will cause issues - even more if you use different database names depending on the environment (dev/tst/prod)
in order to "correctly" use synonyms with a VS project you will need to use VS variables to use instead of your hardcoded database name on the synonyms.
- frederico_fonseca wrote:richardmgreen1 wrote:
Thanks for that. We use synonyms to refer to other databases so hopefully that shouldn't cause too many issues.
I'll give it a go with a test database and see how I get on.
it will cause issues - even more if you use different database names depending on the environment (dev/tst/prod)
in order to "correctly" use synonyms with a VS project you will need to use VS variables to use instead of your hardcoded database name on the synonyms.
Interesting. I don't know about this technique. Do you have any good links explaining how best to set it up? The links I have found have not been great.
- richardmgreen1 wrote:
Is there a way to reorganise the fields into alphabetical order without creating a new table and transferring all the data?
That is, quite possibly, the worst table design idea I've ever heard.
It's too long to explain why it works this way but one of the best ideas is to have the most-filled variable width columns to the far left in the table and the least filled variable width columns to the far right. Most people have no idea that if you have, for example, 10 VARCHAR() columns in a table and they're all NULL, they don't actually occupy any space. Not even 2 bytes to say they're null!. But add even just one character to the VARCHAR() column furthest to the right an all hell breaks loose. All of the VARCHAR() columns suddenly "materialize the meta data" (contrary, not the length but the starting byte position in the row). It also causes a count of the varchar() columns to suddenly appear. So, you end up with 3 additional bytes (too long to explain here) and two "starts at" bytes for all the columns plus the data. So, adding just the 1 byte to the rightmost column of 10 null VARCHAR colums will cause a sudden expansive update of 3 + (10*2) +1 bytes or 24 bytes. That can cause some very serious page splits.
There are other reasons to not do things is "alphabetical order" (one is, what happens if you need to add a column on a very large table?).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Perhaps you could create a view with the columns in your (client's) preferred order? It it was a full view, it should be updatable and therefore the view name could be used just like a table name.
If necessary, you could even rename the original table (for example, we add "_base" to some actual table names when all other access is through views) and add a view that had the original table name.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
Perhaps you could create a view with the columns in your (client's) preferred order? It it was a full view, it should be updatable and therefore the view name could be used just like a table name.
If necessary, you could even rename the original table (for example, we add "_base" to some actual table names when all other access is through views) and add a view that had the original table name.
+ 1000!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Phil Parkin wrote:frederico_fonseca wrote:richardmgreen1 wrote:
Thanks for that. We use synonyms to refer to other databases so hopefully that shouldn't cause too many issues.
I'll give it a go with a test database and see how I get on.
it will cause issues - even more if you use different database names depending on the environment (dev/tst/prod)
in order to "correctly" use synonyms with a VS project you will need to use VS variables to use instead of your hardcoded database name on the synonyms.
Interesting. I don't know about this technique. Do you have any good links explaining how best to set it up? The links I have found have not been great.
original links I looked for this (been many many years) I don't have them anymore - but this one explains part of it (e.g. using VS environments to change the contents of the variables dynamically) - https://stackoverflow.com/questions/29969634/how-to-make-schema-compare-of-database-sql-project-respect-sql-cmd-variables
it is a bit of a pain as it requires each user to change THEIR local .user file to contain the required changes - so these should also be kept as a "read me file" within the solution so new users can follow instructions.
one example I did just now to show up how it works.
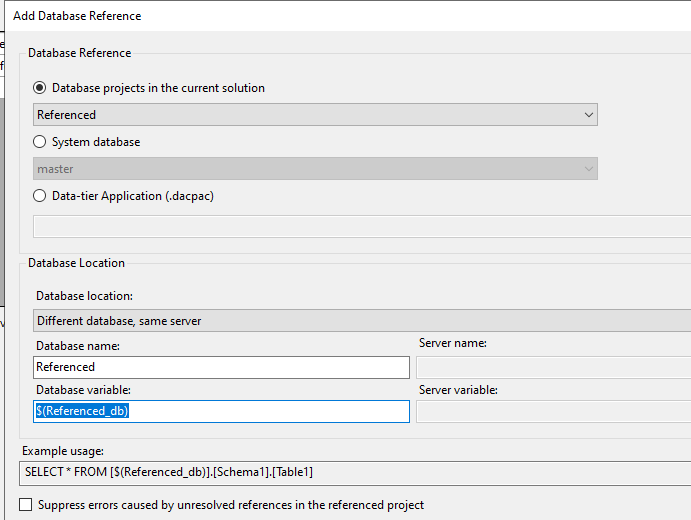
this example assumes 2 databases on solution - Base (where we will create a synonym to the other db) and Referenced
on Base we add a database reference and we give it name "$(Referenced_db)"

this will create a SQLCMD variable on the project
with this and if we create a synonym on db BASE (create synonym xxx for [referenced].[dbo].) we would change its content on visual studio to be "create synonym xxx for [$(Referenced_db)].[dbo]."
with this, any deploy, publish or schema compare would replace the content of the variable ($(Referenced_db)) with "Referenced".
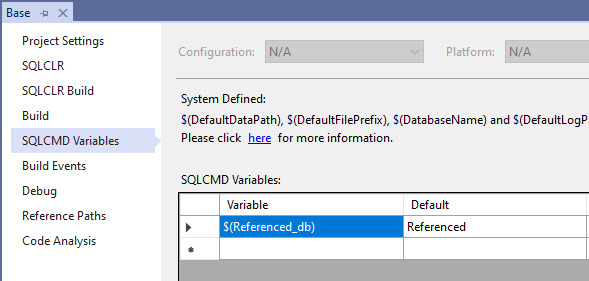
while the above is fine if your dbnames are the same across environments, this is not always the case - as an example on my shop the db names vary from environment to environment - in some cases it is a single letter at the end of db (D,T,U,P) in others its (_dev, _tst, _uat, none for prod), so we need to do a bit more.
on my sample the database names have a suffix according to environment (_dev, _tst, _uat) - prod does not have this - and we also need to allow for normal Visual Studio environment where variable name must match that of the DB name within the solution.
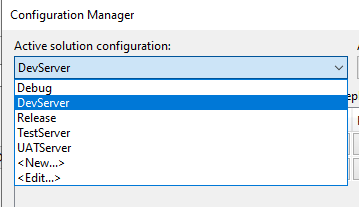
first create new environments
then we change the SQLCMD variable to have a "local" value - this will add a entry to the projname.sqlproj.user file. and within this one its where the magic happens.
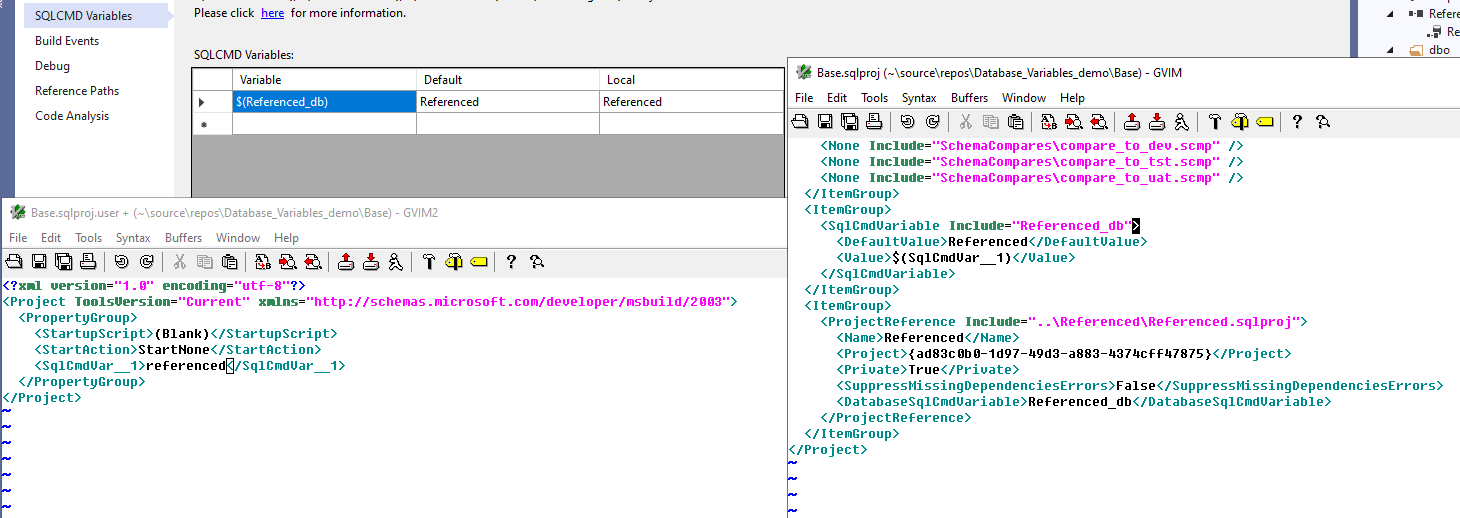
once we add a value to "local" the definition of the project changes - a new sqlcmdvariable is added to the .sqlproj ($(SqlCmdVar_1)) - right image-- and it is also added to the .user file -- left image.
as this is a standard .xml VS file we can manually change it and make it so that that variable is populated based on the configuration name we select in VS (added above).
after changing it my .user file looks like this
<?xml version="1.0" encoding="utf-8"?>
<Project ToolsVersion="Current" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<PropertyGroup>
<StartupScript>(Blank)</StartupScript>
<StartAction>StartNone</StartAction>
<SqlCmdVar__1 Condition=" '$(Configuration)' == 'Debug' ">Referenced</SqlCmdVar__1>
<SqlCmdVar__1 Condition=" '$(Configuration)' == 'DevServer' ">Referenced_dev</SqlCmdVar__1>
<SqlCmdVar__1 Condition=" '$(Configuration)' == 'TestServer' ">Referenced_tst</SqlCmdVar__1>
<SqlCmdVar__1 Condition=" '$(Configuration)' == 'UATServer' ">Referenced_uat</SqlCmdVar__1>
<SqlCmdVar__1 Condition=" '$(Configuration)' == 'Release' ">Referenced</SqlCmdVar__1>
</PropertyGroup>
</Project>with the above changes we can now do builds and schema compares - and as long as we select the correct environment BEFORE we do the task, the variable will be replaced with the correct value for that configuration.
sample project attached.
Viewing 15 posts - 1 through 15 (of 22 total)
You must be logged in to reply to this topic. Login to reply