Recursive Queries
-
Comments posted to this topic are about the item Recursive Queries
-
Nice one to end the week on, thanks Evgeny
Point to note on recursive CTE's though - Use with care - they are not a golden bullet, but rather a lead weight...____________________________________________
Space, the final frontier? not any more...
All limits henceforth are self-imposed.
“libera tute vulgaris ex” - Stewart "Arturius" Campbell - Thursday, February 22, 2018 10:12 PM
+1
Manik
You cannot get to the top by sitting on your bottom. -
What would the correct syntax be, to generate a table of numbers 1 to 10?
- sipas - Friday, February 23, 2018 3:06 AM
If done using a recursive CTE, then
with cnumbers as
(
select 1 as i
union all
select i+1
from cnumbers
where i < 10
)
select i
from cnumbers;However, much better performance would be obtained using a tally table...
____________________________________________
Space, the final frontier? not any more...
All limits henceforth are self-imposed.
“libera tute vulgaris ex” - Stewart "Arturius" Campbell - Friday, February 23, 2018 3:44 AM
Thank you very much.
- Stewart "Arturius" Campbell - Friday, February 23, 2018 3:44 AM
That depends. Do you only need numbers 1 to 10? Is the tally table already in memory? What's the speed of your storage? How's the tally table indexed and what's its fragmentation like?
I think you'll find that on most systems today, the CPU cycles to run such a small recursive CTE still takes less time than the I/O to load even a single extent from disk.It's when you scale up that recursive CTEs, especially an inefficient one like this, become a drag on performance.
- sknox - Friday, February 23, 2018 6:52 AM
That is assuming the tally table has to be a persistent table. You can generate a tally table on the fly incredibly fast with zero reads. Using the DelimitedSplit8K splitter I have long ago isolated just the tally table portion and changed it into a view that I use on nearly all my systems. It is stupid fast, requires zero storage and doesn't indexes or to be concerned with fragmentation. And using this type of tally table you don't have to be concerned about if the recursive cte is going to get too large for performance or any of that. This will scale quite nicely. 🙂
create View [dbo].[cteTally] asWITH
E1(N) AS (select 1 from (values (1),(1),(1),(1),(1),(1),(1),(1),(1),(1))dt(n)),
E2(N) AS (SELECT 1 FROM E1 a, E1 b), --10E+2 or 100 rows
E4(N) AS (SELECT 1 FROM E2 a, E2 b), --10E+4 or 10,000 rows max
cteTally(N) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4
)
select N from cteTally
GO_______________________________________________________________
Need help? Help us help you.
Read the article at http://www.sqlservercentral.com/articles/Best+Practices/61537/ for best practices on asking questions.
Need to split a string? Try Jeff Modens splitter http://www.sqlservercentral.com/articles/Tally+Table/72993/.
Cross Tabs and Pivots, Part 1 – Converting Rows to Columns - http://www.sqlservercentral.com/articles/T-SQL/63681/
Cross Tabs and Pivots, Part 2 - Dynamic Cross Tabs - http://www.sqlservercentral.com/articles/Crosstab/65048/
Understanding and Using APPLY (Part 1) - http://www.sqlservercentral.com/articles/APPLY/69953/
Understanding and Using APPLY (Part 2) - http://www.sqlservercentral.com/articles/APPLY/69954/ - Evgeny Garaev - Thursday, February 22, 2018 10:10 PM
I believe the answer should be 1 to 10, in reality, whenever you receive an error message while executing code, you would eliminate the error. An error message is not usually accepted as a final outcome.
- Sean Lange - Friday, February 23, 2018 7:17 AM
I wouldn't call that a tally table -- it's a tally view (or, more specifically, a tally CTE wrapped in a view.)
But yes, that can be even more efficient than either other solution. However, this does not necessarily scale as well as you might think. I just tested going from 10e+4 to 10e+8 on my test system and the query went from < 1 second to well over a minute, when I stopped it. Every time you have to scale to the next power, you double the number of nested loops in the query. So by 10e+8, a persistent tally table may be more efficient, especially if there's enough RAM on the system to hold it in memory (the table would take ~500MB).
The point is, there are multiple ways of accomplishing this, and what is ideal for one situation may not be good in another situation.
No matter how good any solution is, it doesn't excuse you from evaluating the environment it will need to be run in. - sknox - Friday, February 23, 2018 8:51 AM
Agree 100000% that the best solution is always the one that is tested and proven to work in the environment. I keep this at 10e4 because more than that starts to bog down horribly as you noticed.
_______________________________________________________________
Need help? Help us help you.
Read the article at http://www.sqlservercentral.com/articles/Best+Practices/61537/ for best practices on asking questions.
Need to split a string? Try Jeff Modens splitter http://www.sqlservercentral.com/articles/Tally+Table/72993/.
Cross Tabs and Pivots, Part 1 – Converting Rows to Columns - http://www.sqlservercentral.com/articles/T-SQL/63681/
Cross Tabs and Pivots, Part 2 - Dynamic Cross Tabs - http://www.sqlservercentral.com/articles/Crosstab/65048/
Understanding and Using APPLY (Part 1) - http://www.sqlservercentral.com/articles/APPLY/69953/
Understanding and Using APPLY (Part 2) - http://www.sqlservercentral.com/articles/APPLY/69954/ - sknox - Friday, February 23, 2018 6:52 AM
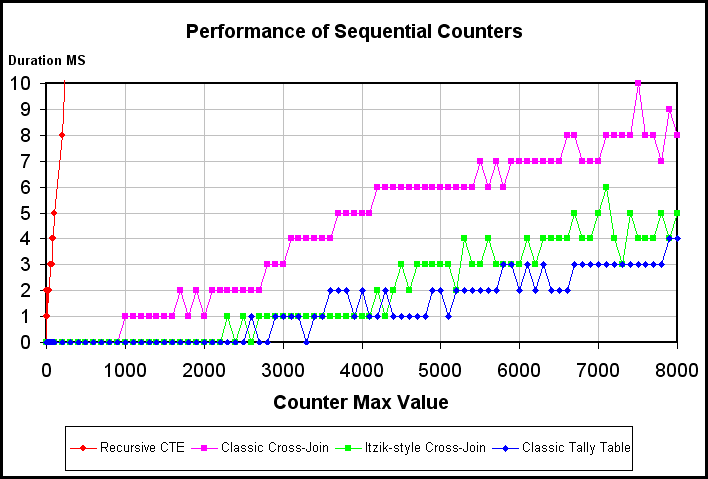
Not true. Recursive CTEs that calculate one row at a time are a huge drag on performance even for small counts. Please see the following article.
http://www.sqlservercentral.com/articles/T-SQL/74118/Just to highlight the problem, here's the main graph from that article. That Red sky rocket at the left of the chart is a recursive cte that doesn't have to count much.

--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - sknox - Friday, February 23, 2018 8:51 AM
If you continue to make performance claims, you really should post your performance test code. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Friday, February 23, 2018 2:19 PM
I wasn't making a detailed performance claim; I was describing a single instance of an effect I observed. But if you want the code I used, simply extend the code already listed one more level, or, if you're too lazy to do that, there's this article ( http://www.sqlservercentral.com/articles/T-SQL/74118/ ) written by some guy which has this algorithm extended to 10e+8. Unfortunately that guy didn't post his results past 8,000 rows, so you'll have to run the test yourself to verify how it slows down.
As for that article you referred to, it actually agrees with my secondary point: The rCTE does get significantly worse as it scales.
However, it doesn't address my primary point at all, which is that the constraints of your environment affect how effective different methods are.
In fact, that article doesn't even mention at all the environment its tests were run in. That's pretty much requirement 1 of any performance test -- especially in the case where you're testing one method which depends primarily on CPU against another method which depends primarily on RAM availability and I/O speed.So let's run an actual test of my original premise:
1. What am I testing: I'm testing whether, in a low-count scenario where a system is memory-constrained, a rCTE tally CTE may perform better than a classic (ie, persistent on-disk) tally table.
2. Test Environment: I'm running these tests on a Leno Y40-70 laptop with a 2GHz Intel Core I7- 4510 with 16GB RAM and a Seagate 2TB
ST2000LX001. The Operating System is Windows 10 Pro (version 1709 build 16299.192), and the SQL Server instance is Microsoft SQL Server 2017 (RTM) - 14.0.1000.169 (X64) Developer Edition.
3. Test Methodology. I will run two scripts, one selecting the sum of the numbers 1 - 10 twice from a rCTE and the other selecting the sum of the numbers 1-10 twice from a classic tally table. Each script will be run a total of 10 times, 5 times with no other constraints, and then 5 times with DBCC DROPCLEANBUFFERS prefixed, to simulate a memory-constrained environment. Specifically, DBCC DROPCLEANBUFFERS will remove the classic tally table data (among other things) from SQL Server's buffer pool, causing it to reload it from disk (or disk cache) on the next query that uses it. This simulates a case where the system does not have the tally table loaded due to memory constraints (or even simply lack of use). Performance will be measured with SET STATISTICS TIME ON; SET STATISTICS IO ON will also be set to provide illustrative data on I/O usage.The Classic Tally Table was created using the following schema, and was populated with numbers from 1 to 133448,704
CREATE TABLE [dbo].[Tally](
[TallyID] [int] NOT NULL,
CONSTRAINT [PK_Tally] PRIMARY KEY CLUSTERED
(
[TallyID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]4. Controlling for other variables: I am the only user of this machine and the only user of the SQL Server instance on this machine, so other users will not have an effect. I cannot directly control for the variable resource usage of other software loaded on the machine; however the multiple runs should average out any variable effect caused by that. Any significant outliers from those runs will be noted and removed from final analysis (additional runs will be performed in the event of an outlier to ensure every test is run the same amount of times.)
Scripts:
1. rCTE script:
--rCTE Tally Table
--Comment out DBCC DROPCLEANBUFFERS for first 5 runs; uncomment for second five runs
DBCC DROPCLEANBUFFERS
GOSET STATISTICS TIME ON
SET STATISTICS IO ON
GO--Run A (first instance)
WITH cnumbers
AS (
SELECT 1 AS i
UNION ALL
SELECT i + 1
FROM cnumbers
WHERE i < 10
)
SELECT sum(i)
FROM cnumbers
OPTION (MAXRECURSION 0);
GO--Run B (second instance)
WITH cnumbers
AS (
SELECT 1 AS i
UNION ALL
SELECT i + 1
FROM cnumbers
WHERE i < 10
)
SELECT sum(i)
FROM cnumbers
OPTION (MAXRECURSION 0);
GOSET STATISTICS TIME OFF
SET STATISTICS IO OFF
2. Classic Tally Table script:
--Classic Tally Table
--Comment out DBCC DROPCLEANBUFFERS for first 5 runs; uncomment for second five runs
DBCC DROPCLEANBUFFERS
GOSET STATISTICS TIME ON
SET STATISTICS IO ON
GO--Run A (first instance)
SELECT sum(TallyID)
FROM dbo.Tally
WHERE TallyID <= 10
GO--Run B (second instance)
SELECT sum(TallyID)
FROM dbo.Tally
WHERE TallyID <= 10
GOSET STATISTICS TIME OFF
SET STATISTICS IO OFFResults (all numbers in millisecods):
No Constraints Simulated RAM Constraint Run rCTE A rCTE B Classic A Classic B rCTE A rCTE B Classic A Classic B 1 0 0 0 0 0 0 3 0 2 0 0 0 0 0 0 3 0 3 0 0 0 0 0 0 3 0 4 0 0 0 0 0 0 3 0 5 0 0 0 0 0 0 2 0 Average 0 0 0 0 0 0 2.8 0 Analysis:
The only queries which ever take any measurable amount of time in these scenarios are the Classic A queries under the RAM constrained scenario.
A quick look at STATISTICS IO shows the reason why:
Classic A: Table 'Tally'. Scan count 1, logical reads 4, physical reads 4...
Classic B: Table 'Tally'. Scan count 1, logical reads 4, physical reads 0...
The table is not in memory in the A instance, so it must be loaded from disk (or more likely in this case, disk cache). These 4 physical reads cost 2-3ms on this system.For contrast, under all scenarios, the comparable rCTE STATISTICS IO were:
rCTE A: Table 'Worktable'. Scan count 2, logical reads 62, physical reads 0...
rCTE B: Table 'Worktable'. Scan count 2, logical reads 62, physical reads 0...
The table is never persisted to disk in this scenario, so there are no reads (or writes)Notes:
I used SUM() rather than returning all rows merely to make reading the results easier. I had tested both methods, and switching to SUM() provided no measurable difference in execution times.The only outlier found was run #3 of the Classic Tally Table A under the simulated RAM Constraint -- that took 131 milliseconds. This was most likely due to some background service happening to perform its own I/O. The last run (run 5) to replace the outlier was the only run to take less than 3ms (2ms).
While not part of the tested hypothesis, I did run the test a few more times using the numbers 1 - 1,000 instead of 1 - 10. As we all expected, the rCTE performed significantly worse than the Classic Tally Table in this case, averaging around 10ms per run as compared to 4ms per run in the Simulated RAM Constraint scenario.
Viewing 14 posts - 1 through 14 (of 14 total)
You must be logged in to reply to this topic. Login to reply