Real-time moving averages for IoT with R
-
Comments posted to this topic are about the item Real-time moving averages for IoT with R
-
The idea is interesting (and probably goes far enough, but we will probably need some serious math to appreciate it), but in my opinion the application to the computation of averages problem is a rather poor choice. And BTW this is NOT a moving average problem, instead it is the problem of updating an average as new data arrives (and older is discarded). And of course it has an obvious and 100% accurate (as opposed to the presented approximate) solution: just keep track of the number of data points arrived (let's call it i) and their sum (let's call it S), so that their average is S / i. Then, as a new observation x is available: S := S + x, i := i + 1, and the new average value is given again by S / i.
That is, with two variables and a division you always have your exact result.
- giorgos.altanis - Monday, October 2, 2017 12:02 AM
Hi Giorgos,
I have to disagree with you, that this isn't a moving average problem. It is a moving average, where the time steps are t -> t+1, i.e. it is the smallest increment possible for a moving average. Of course however, you are completely correct that there are other ways to calculate an exact online average. Perhaps you could consider ways that the concept could be useful in IoT. What if you wanted to track a function of x over time? Perhaps the variance or covariance?
Regards,
Nick -
Thanks for the reply Nick,
Indeed the concept seems very powerful, although I am not capable of fully appreciating it (at least without some serious study). Still, and forgive me for insisting on this, a moving average is a different problem, as it refers to a fixed-length window (e.g., always compute the average of the last 10 points, or last 1000 points, and so on). So, perhaps you would consider changing slightly the title, as it may be misleading.
Regards! -
Interesting, thanks Nick. Exactly where and how are you running this R code, and in real-time? Whats the service you are using?
In my view I believe to process this type of workload with larger data sets you'd probably want to consider doing this in fit-for-purposes services like Azure Stream Analytics (ASA) for example.
ASA can read live from Azure Event Hub or IoT Hub and also has windowing functions specifically built for streaming data without the need to actually land the data first (ie BEFORE it gets to your data store - weather that be Hadoop, SQL, NoSQL, whatever).
Windows can be micro-seconds to days in length.
Even better, ASA queries on streaming data are written in good ol standard SQL - with support for MIN, MAX, AVG, COUNT, STDEV, etc etc
Check this article on Windowing in ASA - https://msdn.microsoft.com/en-us/library/azure/dn835019
AEH or ASA are both PaaS services which means instant deployment, massive scale and server-less----------------------------------------
Rolf T (Mr. Fox SQL)
https://mrfoxsql.wordpress.com/
rolf.tesmer@mrfoxsql.com.au
---------------------------------------- -
I agree with giorgos.altanis on this one, i.e. this is certainly NOT a moving averages problem, so it would be nice if the title of this good article was changed. I would also like to point out that the statement "we can throw away the previous data points and keep just two numbers: the previous "average" and the current data point and take the average at each step" is incorrect. In fact, the author states himself that "To me, at least, this is not blindingly obvious". Well, it is not obvious because it is actually not. It just so happens that the numbers chosen in the set turn out to match the final result. Taking other set of numbers can quickly prove it wrong. This is easiest to see with the sets consisting of same numbers plus one outlier. For example, let the numbers be { 2, 2, 2, 2, 2, 2, 2, 2, 11 }. In this case, the "previous average" just before the last number is always 2 while the final "average" is (2 + 11) / 2 = 6.5. This is obviously incorrect as the true average is 3. Also, if the outlier were in first position, then the "average" calculated using this method would be 2.03515625. This is very different from 6.5 and still is very far from the true average. In a mean time, the simple average is supposed to be commutative. Other averages are typically not, but simple average is commutative, from what I understand.
Outside of the title and the problem with initial function, this is a very good article deserving a high rate. Thank you Nick.
-
Hello Nick,
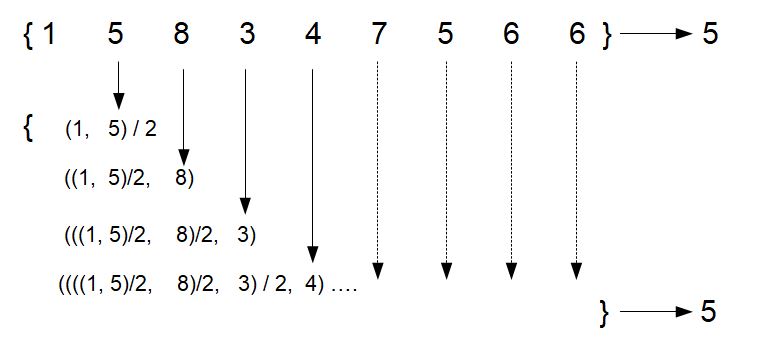
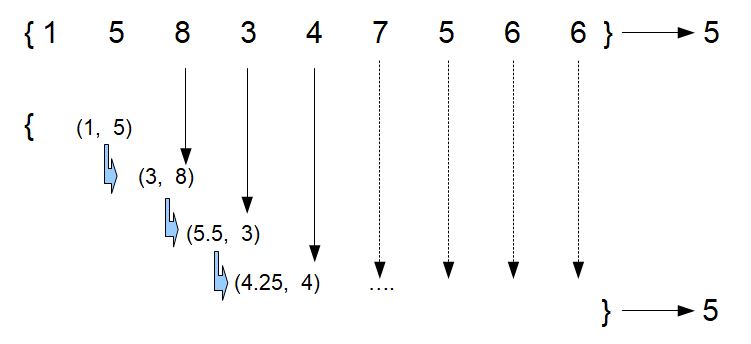
i have just a remark about your first example image, if i understand :
As Oleg says, i believe you should may be détails "weighted means" : for example :In the second step :
It is not : ((1,5)/2 + 8)/2=5.5 ou (3+8)/2=5.5 : you will not get at the end --> 5
Right is : 3*(2/3)+8*(1/3)=4.67 : at the end, you will get -->5And in the next step :
It is not : (5,5+3)/2=4.25 : you will not get --> 5
Right is : 4.67*(3/4)+3*(1/4)=4.25 : at the end, you will get -->5And so on.
This mean you should also know the number of records for calculations, in this example.Excuse me if i am not very clear. Thanks
Gilles. - Oleg Netchaev - Monday, October 2, 2017 7:30 AM
Hi Oleg,
Your example {2, 2, 2, 2, 2, 2, 2, 2, 11} is great! Thank you @giorgos.altanis, @oleg-2.Netchaev and @g.samson for your explanations.
Gilles (@g.samson), I also like your phrase "weighted average" as a more suitable description.
Thanks all,
Nick - g.samson - Monday, October 2, 2017 9:29 AM
"weighted means" - this is a great phrase! Thanks Gilles.
- Rolf Tesmer (Mr. Fox SQL) - Monday, October 2, 2017 5:21 AM
Hi Rolf,
I am running similar processes as part of a data pipeline pushing data into Elasticsearch, SQL Server and Azure Log Analytics. I am doing a lot of the "pipeline" work in R for two reasons: 1) all of my data is coming from public APIs and news feeds, which are very easy to poll programmatically and 2) the transformations I am applying go well beyond what you could easily achieve in SQL. But I completely agree that Azure's Streaming services look amazing! I also like that you can call AzureML functions too - very cool.
Good to hear from you,
Nick
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply