Query taking more time
-
Dear All,
I have a table and it just have 34K rows in it. I have a non clustered index on a date column and i queried for date > <some date>. It tooks 1.5 minutes to return the results. I took the exec plan and posted here for reference. Please help.
Thanks in Advance

- haichells - Wednesday, May 16, 2018 6:50 AM
Insufficient information. Please post an execution plan as a .sqlplan attachment - the actual plan would be preferable to an estimated plan.
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden - haichells - Wednesday, May 16, 2018 6:50 AM
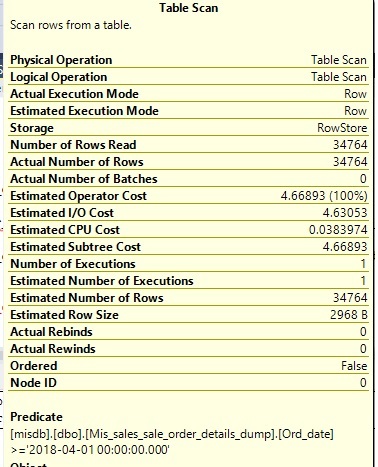
All this shows is a small part of the execution plan. As Chris stated, please post the execution plan as a .sqlplan file. Also, the picture shows that the table was scanned not the nonclustered index.
- haichells - Wednesday, May 16, 2018 6:50 AM
Do you do any stats maintenance? Have you checked for a bad execution plan created by the bad form of parameter sniffing? Did someone add a new index that is actually bad for the query? Also, please see the article at the second link under "Helpful Links" in my signature line below for how to get the best help for performance issues.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
attached execution plan
- haichells - Wednesday, May 16, 2018 10:31 PM
You're returning all 93 columns and every single row is checked against the date filter, and passes - so you're returning all 34,764 rows too, a total of about 98MB.
The index isn't used because it isn't a covering index - it doesn't contain all of the columns required by the query. If only one row matched the parameter then the fastest route to the data would be an index seek and a bookmark lookup. However, stats on the date indicate that all rows will be returned so the index is ignored.
It's going to be slow for these reasons, but 90 seconds seems too long - is this heap in use? An excess of forwarding pointers can slow things up.
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden - ChrisM@Work - Thursday, May 17, 2018 2:15 AM
Looks like a heap since it says table scan not clustered index scan.
- ChrisM@Work - Thursday, May 17, 2018 2:15 AM
I just went through that at work. They have a 1.9GB table that the ORM does a SELECT * from with no criteria. It takes a huge amount of time to return the data to the ORM and it registers as 89 GB of reads. Turns out it's a heap and 340 thousand of the 360 thousand rows are forwarded records because the table is first inserted to and then an expAnsive update (which is expEnsive) occurs almost immediately. Rebuilding the heap helped a ton. I'm trying to get authorization to convert the non-clustered PK to a clustered PK. Not sure that will happen because this is one of THOSE 3rd party apps where the code atrocities just want to make you cry.
I DID have the opportunity to talk with the lead developer at the company that built the software. He said they didn't use any clustered indexes because it would make their database non-portable to other DBMSs. <Headdesk>
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Thursday, May 17, 2018 7:57 AM
Oh ffs, that's absurd. "It might be teethgrindingly slow but it doesn't matter - it's portable!"
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden - ChrisM@Work - Thursday, May 17, 2018 8:22 AM
Heh... haven't seen that particular acronym in a long time. It's use is highly appropriate here! 😀 In its expanded form, Its also pretty much what I told that developer and his management
Now, if I can just get them to fix the code that is literally hitting the database more than 80 Million times in the span of 4 hours.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply