Pivot not working, pivot without aggregate functions.
-
Hi Team,
Can you please help me to get data pivot data.
my Sample table.
code CandidateStatusId
1A E
1A IR
1A N
1A SC
1A SCIR
1B E
1B IR
1B N
1B SC
1B SCIR
2 E
2 IR
2 N
2 SC
2 SCIR
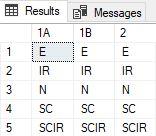
I am expecting output as below, COLUMNNS name as 1A,1B,2 and below are values.
1A 1B 2
IR E E
N IR IR
SC N N
SCIR SC SC
NULL SCIR SCIR
-
Neither a Pivot nor a nasty fast CROSSTAB can be done without an aggregate. The good new for you is, MAX() is an aggregate. Do the Pivot using MAX(). You'll probably have to create a partitioned ROW_NUMBER if you want then in groups of 4 but... understand that you have absolutely nothing in the data you posted to preserve the order within your groups. Is there a column you could use to do that, such as a date column?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
DROP TABLE IF EXISTS #T;
SELECT *
INTO #T
FROM (VALUES ('1A','E'),('1A','IR'),('1A','N'),('1A','SC'),('1A','SCIR'),
('1B','E'),('1B','IR'),('1B','N'),('1B','SC'),('1B','SCIR'),
('2', 'E'),('2', 'IR'),('2', 'N'),('2', 'SC'),('2', 'SCIR')) T(code, CandidateStatusId)
;with cte as
(
select row_number() over (partition by code order by (select null)) rownum, *
from #t
)
select a.CandidateStatusId [1A],
b.CandidateStatusId [1B],
c.CandidateStatusId [2]
from cte a
inner join cte b
on b.rownum = a.rownum
and b.code = '1B'
inner join cte c
on c.rownum = a.rownum
and c.code = '2'
where a.code = '1A'
order by a.rownum
-
Post withdrawn. Found something odd.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
So do you have another column that would enforce the order of the data you posted or doesn't the order in the resulting rows matter?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Post withdrawn. Found something odd.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jonathan AC Roberts wrote:
DROP TABLE IF EXISTS #T;
SELECT *
INTO #T
FROM (VALUES ('1A','E'),('1A','IR'),('1A','N'),('1A','SC'),('1A','SCIR'),
('1B','E'),('1B','IR'),('1B','N'),('1B','SC'),('1B','SCIR'),
('2', 'E'),('2', 'IR'),('2', 'N'),('2', 'SC'),('2', 'SCIR')) T(code, CandidateStatusId)
;with cte as
(
select row_number() over (partition by code order by (select null)) rownum, *
from #t
)
select a.CandidateStatusId [1A],
b.CandidateStatusId [1B],
c.CandidateStatusId [2]
from cte a
inner join cte b
on b.rownum = a.rownum
and b.code = '1B'
inner join cte c
on c.rownum = a.rownum
and c.code = '2'
where a.code = '1A'
order by a.rownumThis is actually a very interesting answer. I took my previous comments down because your good code, at least in preliminary testing on 15 million rows, blows the doors off Pivots and even a classic CrossTab even though it's scanning the full table (or index) 3 times. I've got some "playing" to do but wanted to say thanks for the reply, Jonathan.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply