Pivot 1 row to multiple columns using T SQL
-
Hello. I have data in a table that I want to pivot from 1 row to multiple columns. I only want the colums with dx to pivot if there is a value in them. Thanks.
This is a sample of what I have:
MemberNbr dx dx2 dx3 dx4 dx5
11 J222 e4444
This is what I want:
MemberNbr Diag
11 J222
11 e4444
-
Please see the article at the first link on how to provide some readily consumable test data to help you help people help you. It also saves on many questions such are the missing items NULL or Empty Strings or Spaces or ??? Another question would be, do you want it to handle more possibilities other than just the dx and dx3 columns or not.
A lot of us won't post code unless we've tested it and we need the test data to test it.
With that in mind, use CROSS APPLY to unpivot the data. It's usually faster than using the UNPIVOT operator.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
This is how my table looks except I used random numbers for my values. Some of the dx columns have values and some do not. How about actually showing me how to use cross apply instead of talking about it.
- genova11 wrote:
This is how my table looks except I used random numbers for my values. Some of the dx columns have values and some do not. How about actually showing me how to use cross apply instead of talking about it.
Two way street here. I posted comments to solve the problem just like you posted comments to describe the problem. Take 5 minutes to actually read the article at the link instead of talking about it. Then take another 5 to post the readily consumable data and then one of us will post readily consumable code as a solution. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - genova11 wrote:
This is how my table looks except I used random numbers for my values. Some of the dx columns have values and some do not. How about actually showing me how to use cross apply instead of talking about it.
Forum etiquette is that you post sample data, in the form of CREATE TABLE / INSERT statements which we can cut and paste directly in SSMS and execute for ourselves, along with your desired results based on that sample data. Makes the requirement very clear and removes ambiguity.
If you won't take the time to do that simple task, why should anyone here spend time coding a solution for you?
-
DROP TABLE IF EXISTS MemberDiagnosis;
go
-- Create the table
CREATE TABLE MemberDiagnosis (
MemberNbr INT,
dx VARCHAR(50),
dx2 VARCHAR(50),
dx3 VARCHAR(50),
dx4 VARCHAR(50),
dx5 VARCHAR(50)
);
-- Insert sample data
INSERT INTO MemberDiagnosis (MemberNbr, dx, dx2, dx3, dx4, dx5)
VALUES
(1, 'diagnosis1', 'diagnosis2', NULL, 'diagnosis4', 'diagnosis5'),
(2, 'diagnosisA', NULL, NULL, 'diagnosisD', 'diagnosisE'),
(3, 'diagnosisX', 'diagnosisY', 'diagnosisZ', NULL, NULL);
-- Select the data before pivoting
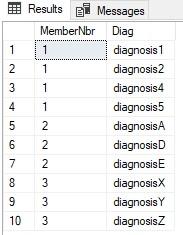
SELECT * FROM MemberDiagnosis;
select MemberNbr, a.b Diag
from MemberDiagnosis
cross apply(values (dx),(dx2),(dx3),(dx4),(dx5)) a(b)
where a.b is not null
order by 1
;
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply