percentage of total trips broken down by month
-
Hi All,
I have a massive data set which breaks down how many trips were taken on which days of which months for years 2016 & 2017. The data also has a column defining whether the person taking the trip is a member or not. The columns in the data set is as follows:
id, start_date, end_date,duration,is_member
I have a question being asked the percentage of total trips by members for the year 2017 broken down by month.
So far I can only find the total number of trips for members and non members in 2017 separately, but I cannot do it in one whole query. THe two queries are as follows:
SELECT MONTH(start_date),
COUNT(*)
FROM trips
WHERE YEAR(start_date) = 2017 AND YEAR(end_date) = 2017 AND is_member = 1
GROUP BY MONTH(start_date);
SELECT MONTH(start_date),
COUNT(*)
FROM trips
WHERE YEAR(start_date) = 2017 AND YEAR(end_date) = 2017
GROUP BY MONTH(start_date);
Any hellp would be greatly appreciated.
-
Something like this, perhaps?
SELECT Mth = MONTH(t.start_date)
,t.IsMember
,TotalTrips = COUNT(*)
FROM trips t
WHERE YEAR(t.start_date) = 2017
AND YEAR(t.end_date) = 2017
GROUP BY MONTH(start_date)
,t.IsMember
ORDER BY MONTH(t.start_date)
,t.IsMember; -
Hi Phil,
That would work but the question I am being asked is to find the percentage of total trips by members for the year 2017 broken down by month.
Thanks
-
Let's introduce some test data. Please try running this and tell me whether it gives you what you want.
DROP TABLE IF EXISTS #Trips;
CREATE TABLE #Trips
(
Start_Date DATE
,End_Date DATE
,IsMember TINYINT
);
INSERT #Trips
(
Start_Date
,End_Date
,IsMember
)
VALUES
('20170101', '20170102', 1)
,('20170201', '20170102', 0)
,('20170201', '20170102', 1)
,('20170301', '20170102', 1)
,('20170301', '20170102', 1)
,('20170401', '20170102', 1);
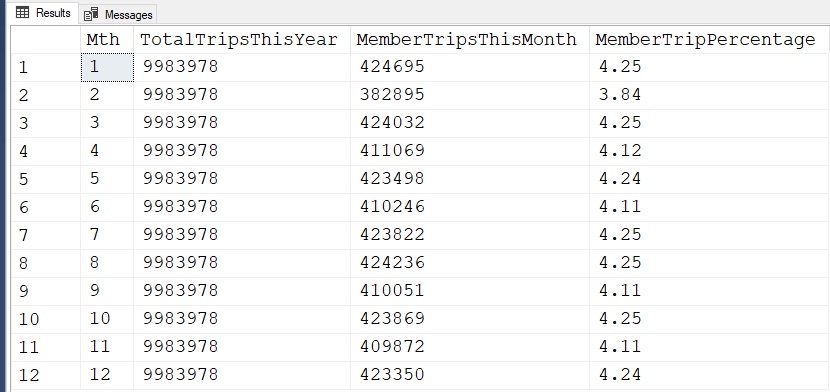
SELECT DISTINCT
Mth = MONTH(t.Start_Date)
,TotalTripsThisYear = COUNT(*) OVER (PARTITION BY YEAR(t.Start_Date))
,MemberTripsThisMonth = SUM(t.IsMember) OVER (PARTITION BY MONTH(t.Start_Date))
,MemberTripPercentage = CAST(SUM(t.IsMember) OVER (PARTITION BY MONTH(t.Start_Date)) * 100.0
/ COUNT(*) OVER (PARTITION BY YEAR(t.Start_Date)) AS DECIMAL(5, 2))
FROM #Trips t
WHERE YEAR(t.Start_Date) = 2017
AND YEAR(t.End_Date) = 2017
ORDER BY MONTH(t.Start_Date); -
Sorry Phil - still doesn't work. Keeps coming up with syntax error, do you mind explaining to me what the purpose of the over command in line 3 of the query refers to?
-
There is no syntax error in that code. I just copy/pasted and ran it to be sure that the rendering had not affected anything.
Which version of SQL Server are you using?
- lin123 wrote:
Sorry Phil - still doesn't work. Keeps coming up with syntax error, do you mind explaining to me what the purpose of the over command in line 3 of the query refers to?
I get no errors with Phil's code. Are you using SQL Server and, if so, which version?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - lin123 wrote:
I have a massive data set which breaks down how many trips were taken on which days of which months for years 2016 & 2017.
What do YOU consider to be "massive"??? We have no clue. To some it would be several 10's of thousands. To others, it would 100's of millions or even several billion. So please provide some order of magnitude in future posts. 😉
I settled for just 10 million rows per year for the 2 years. Here's the code to build a test table if anyone else wants to play. It takes about 35 seconds to run on my box. It should be "Minimally Logged" because it's being created in TempDB, which is in the SIMPLE Recovery Model.
--=====================================================================================================================
-- Create a "massive" data set for the years 2016/2017 according to what the OP described.
-- We're just building test data here. This is NOT a part of the solution.
-- I don't know if the OP considers 10 Million rows per year to be "massive" but it beats 6 rows.
--=====================================================================================================================
--===== If the test table already exists, drop it to make reruns in SSMS easier.
DROP TABLE IF EXISTS #Trips;
GO
--===== Create the table with a Non-Unique Clustered Index.
-- It's not possible to have a UNIQUE/PK on the data for this table.
CREATE TABLE #Trips
(
Start_Date DATE
,End_Date DATE
,IsMember TINYINT
,INDEX ByDates CLUSTERED (Start_Date)
)
;
--===== Create a substantial quanity of test data from 2016 thru 2017 (2018 is the cutoff date).
-- This code creates ~10 Million rows per year. Dunno if that's considered to be "massive" of not.
-- This took ~34 seconds on my laptop. YMMV.
WITH cteGenRandomStartDate AS
(
SELECT TOP 20000000 --20 Million
Start_Date = DATEADD(dd,ABS(CHECKSUM(NEWID())%DATEDIFF(dd,'2016','2018')),'2016') --Random constrained dates
FROM sys.all_columns ac1 --Just being used as a "row source" instead of using a loop.
CROSS JOIN sys.all_columns ac2 --Good for nearly 100 million rows thanks to the CROSS JOIN
)
INSERT INTO #Trips WITH (TABLOCK) --Essential for minimal logging
SELECT Start_Date
,End_Date = DATEADD(dd,ABS(CHECKSUM(NEWID())%10)+1,Start_Date) --1 to 10 days after start date.
,IsMember = ABS(CHECKSUM(NEWID())%2) --Random 1's and 0's
FROM cteGenRandomStartDate
ORDER BY Start_Date --Not required but a good habit
OPTION (MAXDOP 1) --Just to guarantee no parallelism, which could introduce some extent fragmentation
;The first thing I'll say is that you do NOT want to filter on both the Start_Date and End_Date. Any rows that straddle the year mark would be permanently orphaned because the two dates would not be in the same year.
Phil Parkin writes some good code. I modified his code to have SARGable criteria and only check on the Start_Date. Here's his code ...
--===== Phil's good code
SET STATISTICS TIME,IO ON
;
SELECT DISTINCT
Mth = MONTH(t.Start_Date)
,TotalTripsThisYear = COUNT(*) OVER (PARTITION BY YEAR(t.Start_Date))
,MemberTripsThisMonth = SUM(t.IsMember) OVER (PARTITION BY MONTH(t.Start_Date))
,MemberTripPercentage = CAST(SUM(t.IsMember) OVER (PARTITION BY MONTH(t.Start_Date)) * 100.0
/ COUNT(*) OVER (PARTITION BY YEAR(t.Start_Date)) AS DECIMAL(5, 2))
FROM #Trips t
WHERE t.Start_Date >= '2017' AND t.Start_Date < '2018' --4 digit strings auto-magically define the first of the year.
--AND t.End_Date >= '2017' AND t.End_Date < '2018' --Dont' include this line or orphaned trips occur
ORDER BY MONTH(t.Start_Date)
;
SET STATISTICS TIME,IO OFF
;His code turns out the expected results.

Just for posterity sake, here are the run stats... the code went 4 way parallel (I have MaxDop on my 12 CPU box set to 4) and took about 1.75 minutes of CPU time, and a little over a minute in duration. Not bad for 10 out of 20 million rows.
Table '#Trips______________________________________________________________________________________________________________000000000088'.
Scan count 5, logical reads 29916, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 40, logical reads 118898343 physical reads 0, read-ahead reads 108765, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 105220 ms, elapsed time = 67096 ms.I have a pot belly, nearly pure white hair, and a nearly pure white full beard that goes below the bottom of my solar plexus... and I'm only 27 years old. 😀 It got that way from problems like this. The concerning part is that one of the 'WorkTables' caused by the spooling required by the Windowing Functions cause 118,898,343 Logical Reads. That's 928.9 Giga bytes (almost a TeraByte) worth of data movement behind the scenes thanks to the Windowing Functions. NOT Phil's fault.
I LOVE Windowing Functions. You can do some amazing stuff with them. You just have to watch the "gazintas" when it come to logical reads. The fewer rows you have to use them on, the less logical reads you'll have, the less CPU you'll use, and the faster your run will be. You also won't have your DBA showing up at your desk asking why you burned up 4 CPUs in a flurry that lasted more than a minute.
Also, Management asks for an analysis by percent by month like they asked you. You bang it out in a hurry and your done. Two days later, while you're eyes-deep in other "urgent" problems, the big guns send you an email asking for another percentage. It takes you a little longer because you totally forgot what you did by then and then you give them that. Then they ask for more percentages and the cycle continues another 2 or 3 times.
So, when they ask for "A" percentage, anticipate the worst, put on your "Data Analyst" hat, and give them every percentage you can think of based on what they asked you for.
So, we need to solve 2 problems... we need to make the code less resource intensive and we need a lot more percentages.
To solve the first problem, we need to aggregate the "base data" to calculate the percentages from. We can do that by keeping the data layer and the presentation layer separate by using what Peter "Peso" Larsson calls "Pre-Aggregation". Once we have all the simple Sums by month, we'll only have 13 rows (one for the "Total Row", which they'll also eventually ask for... trust me... they eventually will) that we have to do an analysis on.
That will also make a HUGE difference in the number of logic reads, CPU, Duration, Memory, etc.
So, not including the unasked-for analysis on trip duration (which they might eventually ask for) and sticking only to the number of trips, here's what I would would write as code. Notice that the Windowing Functions that I DO use are only working on 13 rows instead of ~10 million rows.
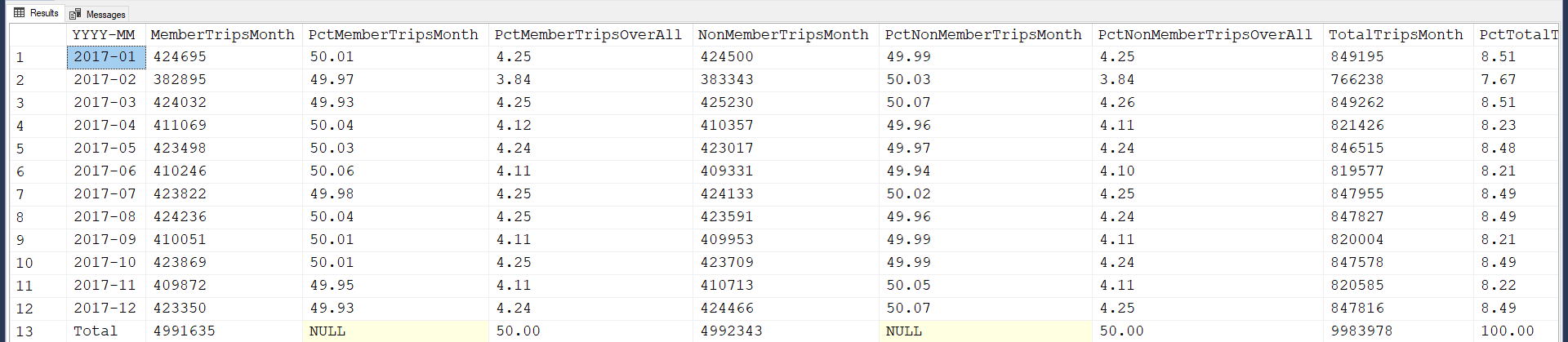
--===== Code that takes advantage of fast pre-aggregation.
DECLARE @pYear INT = 2017 --Parameter for stored procedure or iTVF (If a real scratch table is the source)
;
SET STATISTICS TIME,IO ON
;
WITH ctePreAgg AS
(
SELECT Mth = DATEDIFF(mm,0,t.Start_Date)
,MemberTripsMonth = SUM(IIF(t.IsMember = 1,1,0))
,NonMemberTripsMonth = SUM(IIF(t.IsMember = 0,1,0))
,TotalTripsMonth = COUNT(*)
,Grp = GROUPING(DATEDIFF(mm,0,t.Start_Date))
FROM #Trips t
CROSS JOIN (VALUES(DATEFROMPARTS(@pYear,1,1)))yy(YY)
WHERE t.Start_Date >= yy.YY AND t.Start_Date < DATEADD(yy,1,yy.YY)
--AND t.End_Date >= yy.YY AND t.End_Date < DATEADD(yy,1,yy.YY) --Dont' include this line or orphaned trips occur
GROUP BY DATEDIFF(mm,0,t.Start_Date) WITH ROLLUP
)
SELECT TOP 3000000000
[YYYY-MM] = IIF(Grp=0,CONVERT(CHAR(7),DATEADD(mm,Mth,0),23),'Total')
,MemberTripsMonth
,PctMemberTripsMonth = IIF(Grp=0,CONVERT(DECIMAL(9,2),MemberTripsMonth*100.0/TotalTripsMonth),NULL)
,PctMemberTripsOverAll = CONVERT(DECIMAL(9,2),MemberTripsMonth*100.0/((SUM(TotalTripsMonth) OVER())/2))
,NonMemberTripsMonth
,PctNonMemberTripsMonth = IIF(Grp=0,CONVERT(DECIMAL(9,2),NonMemberTripsMonth*100.0/TotalTripsMonth),NULL)
,PctNonMemberTripsOverAll = CONVERT(DECIMAL(9,2),NonMemberTripsMonth*100.0/((SUM(TotalTripsMonth) OVER())/2))
,TotalTripsMonth
,PctTotalTripsMonthOverAll = CONVERT(DECIMAL(9,2),TotalTripsMonth*100.0/((SUM(TotalTripsMonth) OVER())/2))
FROM ctePreAgg
ORDER BY Grp,[YYYY-MM]
;
SET STATISTICS TIME,IO OFFYeah... initially, that's a lot longer but I get it done in one sitting instead of the "added scope" sessions that experience has taught me very well that they're going to end up asking for. It's easier to comment out unwanted columns than it is to start over in a day or two to add them.
Here are the run results. And, guess what, even if they hadn't thought about the extra analysis, they going to love you for providing it (sorry that last column name doesn't quite fit the screen)... (I didn't add commas, which would be fairly easy to do using a trip through the Money datatype... If it were my actual submittal, I'd probably add them).
We also added a YEAR to the month so they don't need to ask that question, either.
With all that code, this must've taken a month of Sundays to run, right? Not at all thanks to the power of "Pre-Aggregation"... here's the stats.
Table 'Worktable'. Scan count 3, logical reads 31, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table '#Trips______________________________________________________________________________________________________________000000000088'.
Scan count 1, logical reads 29714, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 2672 ms, elapsed time = 2661 ms.No parallelism required.
It only took about 2.7 seconds of both CPU (compared to 105) and Duration (compared to 67) and we gave them everything that they'll have eventually asked for. If they insist they don't want the other stuff, don't make the mistake of deleting it from your code because the will eventually ask for it back (experience... trust me). Just comment out the columns they say they don't want until they change their mind again.
Also, before your next post, read the article at the first link in my signature line below. Words like "massive data set" need to be quantified at least with an order of magnitude. "Millions of rows" won't hack it either because there's a hell of a difference between 2 and 20 and 200 million rows. It would also be really helpful to others if you posted a CREATE TABLE statement because that would let us know not only the column names, but the datatypes, as well as making it so we didn't have to write it to test it.
And, you don't need to produce something that creates "Millions of rows" like I did but it would be nice if you include a small sample of 10 or more rows as "readily consumable data" in the form of a INSERT/SELECT VALUES statement.
Thanks for the question and I hope that all helps. 😀
p.s. It didn't take me that much longer to do, either. If you look at the formulas, you'll notice that they're all basically the same. It was a simple matter of making 1 and testing it and then the rest was all "CPR"... "Cut'Paste'n'Replace". 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Oh wow! Thanks for all the help guys, I just checked my servers and now it works. I greatly appreciate all the information I will be sure to take it in.
-
Jeff, that's nice work. Thanks for reminding me of ROLLUP and GROUPING too.
- lin123 wrote:
Oh wow! Thanks for all the help guys, I just checked my servers and now it works. I greatly appreciate all the information I will be sure to take it in.
Awesome. Can you tell us what the actual number of rows the "massive" table actually has in it just so we can do a little gauging for the future? Thanks.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Phil Parkin wrote:
Jeff, that's nice work. Thanks for reminding me of ROLLUP and GROUPING too.
Good sir, I'm humbled. Thank you for the very kind feedback. And thank you again for the wonderful proof-reading you did for me. I'm working on your great suggestions this week.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply