"Number of rows Read" vs "Actual Number of rows for all Executions"
-
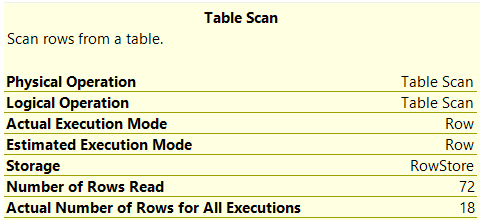
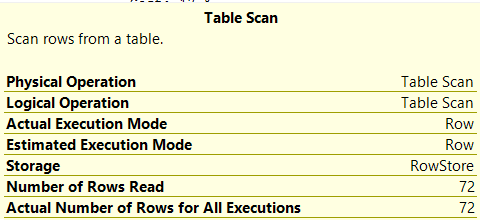
I'm using SSMS 2019 and comparing two execution plans. When looking at a seek or scan operator details there is a line for Number of rows Read and also one for Actual Number of rows for all Executions. This is new (I think in 2019) and I can't find anything about this anywhere on the internet or in any SQL book I own.
Below are two screenshots from the plans to show you what I'm talking about. Anyone know the difference, and/or have a link to any article about the difference between these.
 "I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
-
Thanks for posting your issue and hopefully someone will answer soon.
This is an automated bump to increase visibility of your question.
-
I don't have documentation on this, but from reading the text for both I interpret it as:
Number of rows read <-- number of rows that needed to be read from disk/memory
Actual Number of Rows for All Executions <-- the number of rows that are being passed to the next command
The reason why you would need to read all rows would be when doing a scan BUT you don't need all rows from the table. For example, lets say you have an INT IDENTITY column on a table with 72 rows. You have NO index on that column, so you need to do a SCAN if you are going to be using that in your WHERE clause. So, you do a SELECT from that table with a WHERE clause like "WHERE ID <= 18". Assuming no gaps, you would get 18 rows back which would match the Actual Number of Rows for All Executions value BUT since there is no index on that column, you are doing a Table Scan on it which would result in the Number of Rows Read of 72 since you need to read all of the rows in order to check if ID is less than or equal to 18.
To me, the above makes sense based on the wording of those metrics and is useful information. Does the above make sense to you?
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Hey there, Alan... long time no see (like, um.... Friday night, right? :D)
You and I (and Brian above) and a whole lot of others know what these two things are but, I agree... the properties aren't very well covered in the "official" documentation. In fact, I've not been able to find them in any of the documentation.
BUT... just like good SQL being documented so you don't have to worry about losing the documentation or having disparate sources of information, the folks that wrote the "Properties" window in SSMS did real good. I'm not talking about the Yellow pop-up thing in the execution plan... I'm talking about when you right click-on that and select "Properties". Just highlight the property and read the description at the bottom of the window.
Here are the two descriptions from there...
May the SQL gods be kind to the developers that did this. 😀
I can also confirm that both of these properties have been available since at least 2016. I did have to check to make sure. I don't have any instances earlier than that to check.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
"I can also confirm that both of these properties have been available since at least 2016. I did have to check to make sure. I don't have any instances earlier than that to check."
Can confirm that these properties are available in our 2012 instances using SSMS v18.8. Sorry I missed you guys on friday, had to go walkabout!
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden -
Thanks for the feedback on 2K12, Chris. And, Eirikur reminded us that you were on a walkabout on Friday. Sill missed ya, though.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
For those wondering, I checked and those do not appear to exist on 2008 R2. So thinking they were added in 2012.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Thanks for the replies and sorry for being a Ghost OP.
To me, the above makes sense based on the wording of those metrics and is useful information. Does the above make sense to you?
Absolutely, thanks Brian. - very good details and it explains a couple things about a query I've been working on.
Thanks Jeff - I didn't even think to look at the properties details.
Missed you too Chris - hope to catch you next time!
"I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
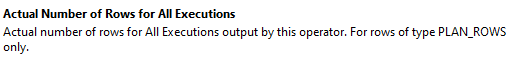

Viewing 8 posts - 1 through 8 (of 8 total)
You must be logged in to reply to this topic. Login to reply