Non clustered index fragmentation problem
-
Hi,
Table schema
RouteID bigint,
DLRStatus tinyint,
DLRID nchar(50)
ReceivedDate datetime
This table contains millions of records and we need to fetch the record by DLRID which is received from several sources from outside the application so we cannot control the format and order. Most send this field as guid or some alphanumeric id .
the main issue is whenever we create a non clustered index on dlrid field within minutes the fragmentation goes to 99% because the data received is not in any order.
Is there any solution for this thanks.
-
I think the first thing I'd ask is - what problem are you trying to solve?
Having an index highly fragmented MAY cause performance issues, or may be perfectly fine. Are you noticing performance issues related to this fragmented index? This is easy to test with a test system - restore a backup to the test system, run your problem query. Next, still on the test system, rebuild that index (99% fragmentation on a million row table should get a rebuild, not a reorg) and re-run the problem query. Is it "better"? If so, then I'd worry about fixing the fragmentation on live. If the query is still sluggish, then fragmentation isn't the problem.
Now, if you are just wanting to get the fragmentation number lower, it may not hurt to adjust your fill factor, especially if data is going in in random order. But it also depends on how you are pushing the data in. Is it a "truncate and reload" or even a "delete and insert" approach? If so, and you are having millions of rows going in at a time, I'd disable the index before the data load (better performance on the data load) and add a "rebuild" onto the index after the data load. If it is a constant stream of data going in, then I'd be looking at adjusting the fill factor. To which value? That (from my experience) is more trial and error. Since it is a high write and a random write, I'd probably start at 75 and let it run for a bit and see if it helped. Then I'd bump it to 80 and see if that made things better or worse. Then adjust accordingly until I hit the sweet spot. That is, again, assuming that I am fixing a problem like performance. If this is just to remove an alert on a reporting tool, it would be low on my list of things "to fix".
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Hi Brian,
the data flow is continuous and only inserts are happening no updates or delete.
i tried different fill factor settings but its the same.
as far as performance is concerned i have not noticed any degradation our server is running on an nvme ssd which has high io.
today i rebuild the index it hardly takes 2 seconds to rebuild with 15 million rows.
my only concern is that this table grows daily about a million records or more, so in future it may create problem.
I am not able to think what can be the other way to avoid fragmentation if we even need to change schema also.
the last option i can think of is to schedule a daily rebuild of this index with option online.
If you can provide some opinion on this it would be great. Thanks
-
With random data being inserted into an nchar(50) column - there isn't going to be anything you can do to prevent fragmentation. Your best option is to reduce the number of page splits occurring - and that will be done by setting an appropriate fill factor and rebuilding the index on a regular basis.
The goal is to set the fill factor as high as possible - but leaving enough space available on each page to allow for xx time between rebuilds. I would start with a fill factor of 90 and incrementally drop that until you get to a point that is workable - but probably no lower than 80, but that will depend on your system.
It may be that you need to schedule an index rebuild every xx hours - but honestly, at only 15 million rows I cannot see this having the sort of activity that would cause it to fragment that much and that fast.
And finally - unless the majority of the data being sent is close to 50 characters, using nchar(50) is padding out the column on every single page. Change that to nvarchar(50) and that will reduce the amount of data per page - and won't be an issue because the table is only receiving inserts.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
If the DLRID are mostly unique, or mostly come in batches together when not unique, I suggest encoding the DLRIDs into a numeric code.
That is, create a separate table with the nvarchar(50) DLRIDs as the unique clustering key, but include a $IDENTITY column in the table. Then, use that id value, rather than the char value, when inserting into the main table. Cluster the main table on the DLRID_id rather than the DLRID itself. That would reduce fragmentation drastically, while also reducing the main table size. The other table will get fragmented, but it can be rebuilt without effecting access to the main table.
The lookup for a given DLRID would then look like this:
SELECT *
FROM dbo.main_table mt
WHERE DLRID_id = (SELECT DLR_id FROM <new_DLRID_encode_table> WHERE DLRID = N'<string_to_match>')
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
how are you determining the frag level, are you using the index physical stats DMV?
-----------------------------------------------------------------------------------------------------------
"Ya can't make an omelette without breaking just a few eggs" 😉
- vineet6824 wrote:
Hi,
Table schema
RouteID bigint,
DLRStatus tinyint,
DLRID nchar(50)
ReceivedDate datetime
This table contains millions of records and we need to fetch the record by DLRID which is received from several sources from outside the application so we cannot control the format and order. Most send this field as guid or some alphanumeric id .
the main issue is whenever we create a non clustered index on dlrid field within minutes the fragmentation goes to 99% because the data received is not in any order.
Is there any solution for this thanks.
I realize that this post is a couple of months old and I might be trying to close the barn door after the horse already got out but we'll see.
Jeffrey Williams has a darned good suggestion about this if you don't want to take Scott's advise about building a separate lookup table (which wouldn't be needed in most OLTP/single row lookup environments).
There are a couple of keys here, though. If you could answer a couple of questions, please, we might be able to easily make it so that you can quite literally go for months with <1% fragmentation on the DLRID column because it IS random. Here are the questions...
1. What is the average row size of this table? Yeah, I could figure it out from what you posted but it's easier if you just run sys.dm_db_index_physical_stats and let me know.
2. How many rows do you actually have in this table? Saying "Millions of rows" is not an adequate answer. How many millions?
3. How many rows per day are generally inserted into the table? Again, "Thousands of rows" or "Millions of rows" is not adequate. I need to know how many thousands or millions of rows.
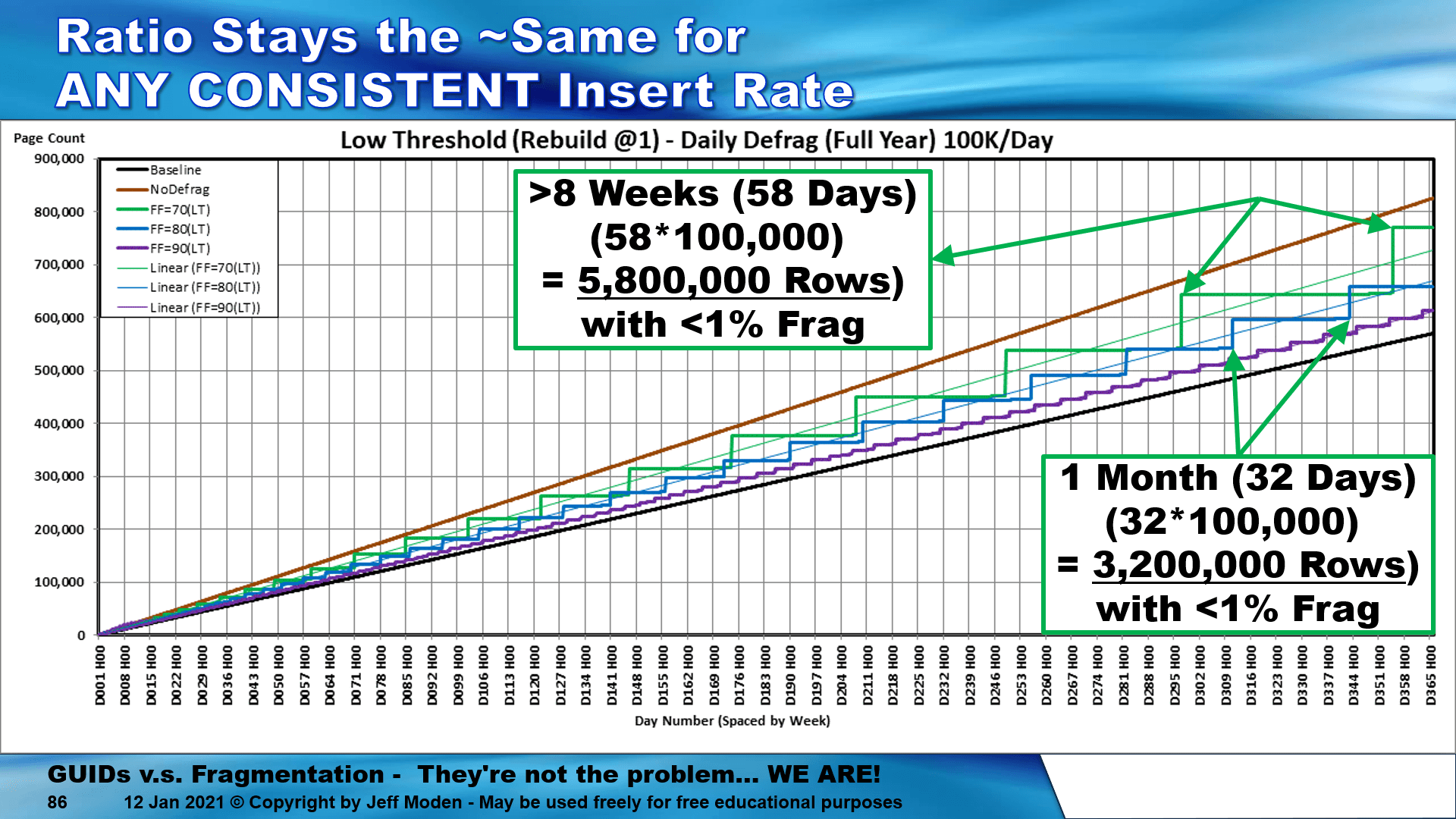
Just to give you a clue that I might just know what I'm talking about, I've done a shedload of testing with this kind of stuff. One of the tests I did inserts 100,000 rows per day in a 1005 RBAR fashion into a 123 byte/row Clustered Index for 58 straight days with < 1% fragmentation, almost zero page spits, and no index maintenance during the 58 day period. That's 5.8 MILLION random GUID rows inserted with < 1% fragmentation. The table contained ~29.8 Million 123 byte rows at the beginning of day 299, which was day 1 of the 58 day period I'm talking about. That was with a 70% Fill Factor and the other Fill Factors also work a treat.
Here's the graph from the test results... the "flats" are where data is being added with almost no page splits (no even "good" ones) and nearly zero fragmentation.

And, no... the page density of the pages doesn't stay at 70%. They're constant filling as shown in the following chart of a similar 70% Fill Factor run of the same technique. This chart was for 10,000 rows per day ending at 3.65 million rows.
The "technique" is simple no matter how many rows per day you have.
- Set the desired Fill Factor. I recommend 71, 81, or 91. Why the 1? To make it easy to identify these types of "Low Threshold Rebuild" indexes just by reading the Fill Factor. No special tables required.
- Rebuild when logical fragmentation hits goes over just 1%. This is important because ALL of the pages fill at almost the same rate and as soon as you get 1% fragmentation, it means there's no practical amount of room left above the fill factor and the index is going to start doing MASSIVE page splits across the board starting the next day or so.
- When you do index maintenance at or above 1%, only do REBUILDs! NEVER EVER USE REORGANIZE ON RANDOM GUID INDEXES because it doesn't actually work the way you think it does. Like a bad drug, REORGANIZE actually compresses the pages without clearing the area above the fill factor and guess what that does? IT PERPETUATES MASSIVE PAGE SPLITS ALL DAY EVERY DAY and the more you use it, the more you need to use it. The "Best Practice" index maintenance that everyone in the whole bloody world uses are actually a WORST PRACTICE for most indexes that fragment. There are only two different scenarios out of many where REORGANIZE will actually do the job and then it'll still cost you an arm and a leg in log file space and number of entries in one of those while it perpetuates the problem in the other (you need to fix the other index).
Here's what the index looks like (this is for an 80% fill factor but looks almost identical at other fill factors) if you make the mistake of using REORGANIZE. Like I said... DO NOT USE REORGANIZE ON RANDOM GUID INDEXES! (Exception... use Reorganize if you need to compress LOBs but then follow that with a REBUILD).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)


Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply