Needed to find all possible Dates Overlaps from a single Table
-
Hi,
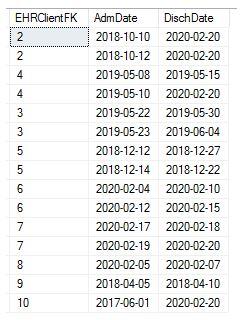
I have the following Episode table example:
Where DischDate = "2020-02-20" means - client hasn't been discharged.

My goal is to display all possible date range - AdmDate - DischDate - overlaps combinations for the Client (EHRClientFK)
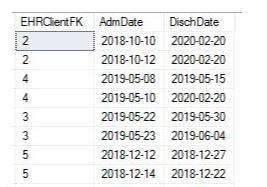
I expect to display the values for EHRClientFK = 2, 3, 4, 5 (see picture below)
Values where EHRClientFK = 8, 9, 10 have less than 2 dates combinations
Values for EHRClientFK = 6, 7 have no overlaps
So I expect the result, like :
Here is my Template of all the Overlaps:
I wrote the following code to achieve my goal, but when I apply it on the "Real" table (with more than 20K records) - I still see some NON overlapping dates - (for example Value 2 with AdmDate1 = 2/10/20 DischDate1 = 2/12/20; AdmDate2 = 2/13/20)and also the values with just one date range AdmDate1, DischDate1 and no dates 2...
Please see my code below:
My question - how should I change my Where clause in order to only dispaly more than one date range for my Client + the Overlap Dates only?
SELECT
a.[EHRClientFK]
,a.[AdmDate]
,a.[DischDate]
FROM [WH].[dbo].[Episode] a
INNER JOIN [WH].[dbo].[Episode] b ON a.EHRClientFK = b.EHRClientFK
WHERE
((a.DischDate = '2020-02-20') AND (b.DischDate = '2020-02-20'))
OR ((a.AdmDate <= b.DischDate) AND (b.AdmDate <= a.DischDate))
GROUP BY
a.[EHRClientFK]
,a.[AdmDate]
,a.[DischDate]
HAVING COUNT (*) >1 -
Seems like you should be able to join the (AdmitDate, DischargeDate) to a Calendar table to expand the date range to a set of dates, and then group by EHRClientFK. Then any with a count > 1 has an overlap on that day.
-
Nice post and perfectly described but could you write the code without test data to know if you wrote the code correctly? Neither can we. 😉 Take the data you used to make this graphic and render it as readily consumable data in the form of code. Help us help you. Please see the first link in my signature line below for one way to do that.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Jeff, Here is the data in a consumable format. I couldn't work out from the question exactly what's wanted so I'll leave it to someone else.
;with Episode as
(
select * from (values
(2,convert(datetime,'20181010'),convert(datetime,'20200220')),
(2,'20181012','20200220'),
(4,'20190508','20200515'),
(4,'20190510','20200220'),
(3,'20190522','20190530'),
(3,'20190523','20190604'),
(5,'20181212','20181227'),
(5,'20181214','20181222'),
(6,'20200204','20200210'),
(6,'20200212','20200215'),
(7,'20200217','20200218'),
(7,'20200219','20200220'),
(8,'20200205','20200207'),
(9,'20200405','20180410'),
(10,'20170601','20200220')) T(EHRClientFK, AdmDate, DischDate)
)
SELECT a.[EHRClientFK],
a.[AdmDate],
a.[DischDate]
FROM [Episode] a
INNER JOIN [Episode] b ON a.EHRClientFK = b.EHRClientFK
WHERE ((a.DischDate = '2020-02-20') AND (b.DischDate = '2020-02-20'))
OR ((a.AdmDate <= b.DischDate) AND (b.AdmDate <= a.DischDate))
GROUP BY a.[EHRClientFK] ,a.[AdmDate] ,a.[DischDate]
HAVING COUNT (*) > 1; - Jonathan AC Roberts wrote:
Jeff, Here is the data in a consumable format. I couldn't work out from the question exactly what's wanted so I'll leave it to someone else.
Except for a little bit of unnecessary criteria, it looks to me like you worked it out just fine, Jonathan. All I'm doing below is the same as you except I'm putting the test data into a table to demonstrate that the Cartesian Product can be avoided by the addition of an index and eliminating the extra criteria.
And thanks for posting the readily consumable data. We now have two different methods to show the OP how to help the people both understand the question better and make it easier for them to provide a working coded solution.
Here's my version of the readily consumable test data with a couple of explanations added in.
--=============================================================================
-- Create and populate the test table.
-- This is not a part of the solution. We are just creating demonstrable,
-- readily consumable test data to test code with.
--=============================================================================
--===== If it exists, drop the test table to make reruns in SSMS easier.
IF OBJECT_ID('TempDB..#Episode','U') IS NOT NULL
DROP TABLE #Episode
;
GO
--===== Without knowing anything else about the table, create the test table
-- with a guess at the datatypes. Change then if necessary. The solution
-- code should still work unless you do something totally wonky with the
-- datatypes.
CREATE TABLE #Episode
(
EHRClientFK INT NOT NULL
,AdmDate DATE NOT NULL
,DischDate DATE
)
;
--===== Assuming that there''s more to this table than just those 3 columns
-- and that a Clustered Index already exists on the table, add a UNIQUE
-- Non-Clustered Index to the table to make it so that we don''t end up
-- with a Cartesian Product due to scans in the upcoming query.
CREATE UNIQUE NONCLUSTERED INDEX IX_Cover01
ON #Episode (EHRClientFK, AdmDate, DischDate)
;
--===== Populate the test table with test data according to what the OP posted.
INSERT INTO #Episode WITH (TABLOCK)
(EHRClientFK, AdmDate, DischDate)
VALUES ( 2,'20181010','20200220')
,( 2,'20181012','20200220')
,( 4,'20190508','20200515')
,( 4,'20190510','20200220')
,( 3,'20190522','20190530')
,( 3,'20190523','20190604')
,( 5,'20181212','20181227')
,( 5,'20181214','20181222')
,( 6,'20200204','20200210')
,( 6,'20200212','20200215')
,( 7,'20200217','20200218')
,( 7,'20200219','20200220')
,( 8,'20200205','20200207')
,( 9,'20200405','20180410')
,(10,'20170601','20200220')
;Here's one solution almost identical to Jonathan's but without the extra criteria. Please READ THE WARNING IN THE HEADER!
--=============================================================================
-- Solve the problem in a fashion similar to how Jonathan AC Roberts
-- solved it in his previous post on this thread.
-- To learn how it works, please see the following article on the subject.
-- https://www.sqlservercentral.com/articles/finding-%e2%80%9cactive%e2%80%9d-rows-for-the-previous-month-sql-spackle-1
-- NOTE THAT THIS CODE COULD BECOME A PERFORMANCE ISSUE IF THERE ARE A LOT
-- OF ROWS FOR ANY GIVEN EHRClientFK VALUE DUE TO MULTIPLE SMALLER
-- CARTESIAN PRODUCTS. IF THAT''S THE CASE, PLEASE POST BACK AND WE''LL USE
-- ANOTHER METHOD.
--=============================================================================
SELECT a.EHRClientFK
,a.AdmDate
,a.DischDate
FROM ##Episode a
JOIN ##Episode b ON a.EHRClientFK = b.EHRClientFK
AND a.AdmDate <= b.DischDate
AND b.AdmDate <= a.DischDate
GROUP BY a.EHRClientFK, a.AdmDate, a.DischDate
HAVING COUNT (*) > 1
;--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jonathan AC Roberts wrote:
Jeff, Here is the data in a consumable format. I couldn't work out from the question exactly what's wanted so I'll leave it to someone else.
Except for a little bit of unnecessary criteria, it looks to me like you worked it out just fine, Jonathan.
--=============================================================================
-- Solve the problem in a fashion similar to how Jonathan AC Roberts
-- solved it in his previous post on this thread.It's not my solution, I just pasted in the OP's SQL from the question.
-
Heh... I definitely blew that one then. I didn't look at the OPs code closely enough to realize that you had provided a copy of the same code. I was also confused because it provided the correct answer according to the graphics the OP posted.
Anyway, thanks for the correction, Jonathan.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Hell-1934 wrote:
In general when using the cases of overlap, people tend to forget specific cases because there multiple overlap situations. In the above I am missing for example overlaps where the second line the A becomes before the first line.
So testing for a 'NON' overlap is far simpler test if the end. In text:
If period A finishes before period B starts the periods do not overlap.
OR
If period B finishes before period A starts the periods do not overlap.
Do not overlap is true when:
A.finish <= B.start OR B.finish <= A.start
The 'inverse' of this test Overlap:
NOT (A.finish <= B.start OR B.finish <= A.start)
this is equivalent to (Overlap):
A.finish>B.start AND B.finish>A.start
Remark, NULL values do throw of the NOT in this reasoning (three valued logic), so get rid of the NULL's before using the above. If there is a NULL use a very early date for the start or a very late date for the finish.
Starting from the 'non overlap' test en progressing to the 'overlap' test makes the thinking process so much simpler, only two conditions have to be tested and the understanding is far simpler. This had been done wrong by plenty of people even people considered to be SQL Guru's at the top level (although that was Oracle).
Hope to have made the world a bit simpler with the above reasoning.
Ben
-
Here's an option that eliminates the need for a self join by using windowing functions (LAG & LEAD)
WITH
cte_overlap AS (
SELECT
e.EHRClientFK,
e.AdmDate,
e.DischDate,
Overlap = CASE
WHEN
e.AdmDate < LAG(e.DischDate, 1, '1900-01-01') OVER (PARTITION BY e.EHRClientFK ORDER BY e.AdmDate)
OR
e.DischDate > LEAD(e.AdmDate, 1, '9999-12-31') OVER (PARTITION BY e.EHRClientFK ORDER BY e.AdmDate)
THEN 1
ELSE 0
END
FROM
#Episode e
)
SELECT
o.EHRClientFK,
o.AdmDate,
o.DischDate
FROM
cte_overlap o
WHERE
o.Overlap = 1; -
Thank you very much - ben.brugman + Jason A. Long!
These are the decisions that should definately work, I am going to try today.
I tried the previous authors but unfortunately - no difference with what I wrote and the same mistakes ((
Yes, case is probably more elegant (I knew but wasn't sure how to use it)
Displaying DO NOT overlap variations seems like very correct one!
Thx again!
-
Also, thank you - the authors above - next time when problem I'll read the "posting" rules.
As I am thrown between the different projects and systems (languages) and can't 100% be concentrated on sql, there will be problems, for sure , again -)

Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply