Minimal Logging
-
The article notes that it still needs to meet the prerequisites and points to the following which explains the differences with empty tables vs tables with data:
Prerequisites for Minimal Logging in Bulk ImportSue
- Thank you for a quick reply.
I think I meet the prerequisites, but I find that article very confusing, which is I why I quoted the other one, which puts the requirements into a simple to read table. But let me go through the points one by one:
The table is not being replicated: Check
Table locking is specified: CheckTable is not a memory-optimized table: Check"If the table has a clustered index and is empty, both data and index pages are minimally logged. In contrast, if a table has a btree based clustered index and is non-empty, data pages and index pages are both fully logged regardless of the recovery model.":
The table has a unique clustered index and is not empty. The text above talks about a "btree based clustered index". I do not know what that is.
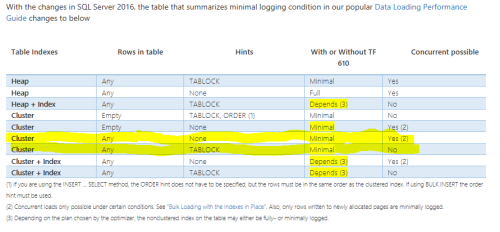
This is the text that confuses me. If this text means to say that there can never ever be minimal logging in tables with clustered indexes and data in the table, then it directly contradicts the table in the article I referenced and the data loading performance guide. It is the table below. I think I fit in either of the two rows I highlighted. If not, then please explain why.

Apologies for the small image. See it in full resolution here.Thanks.
- ti 93734 - Monday, March 18, 2019 12:09 PM
What Recovery Model is the database in when you're trying your "Minimally Logged" Inserts?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Both databases are permanently in simple recovery model.
- ti 93734 - Monday, March 18, 2019 6:00 PM
Ok. And your code looks absolutely correct for minimal logging, as well.
I believe (I don't know what's in either of your files according to "sort order") the problem here may be "interleaving" of the data. If the second insert isn't "append only" according to the order enforced by the Clustered Index (CI from here on), then SQL Server will insert into the logical "middle" of the CI because it is compelled to maintain the logical sorted order of the data in the CI. When that happens, you have the "bad" kind of page splits, which can be quite nasty and are ALL FULLY LOGGED and I believe that's what you're seeing. There's also the issue that any partially full page that you insert into even with "Minimal Logging" will still be fully logged and only new pages will be "Minimally Logged", which is clearly stated in the link you provided.
.--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thank you for the quick answer.
I have suspected that something like what you say could be going on - mostly because I could not think of any other cause for what I see. But I have been over and over the insert order and the CI order and think it should be good.
Additionally I tried to look at the index fragmentation after the first minimally logged insert and after the second insert, which is certainly not completely minimally logged - judging by the size of the ldf file.
I am using this query after inserts:
SELECT avg_fragmentation_in_percent, fragment_count, page_count, avg_page_space_used_in_percent, record_count
FROM sys.dm_db_index_physical_stats(DB_ID(N'InsertTest'), OBJECT_ID(N'InsertTest.dbo.InsertDest'), NULL, NULL, 'DETAILED')
This is what I get after round 1 (executed in 52 seconds and grew LDF to 0.03 GB):avg_fragmentation_in_percent fragment_count page_count avg_page_space_used_in_percent record_count
---------------------------- -------------------- -------------------- ------------------------------ --------------------
0.01 61 418606 99.6 80372250
0.161 9 1243 99.83 418606
50 4 4 92.12 1243
0 1 1 1.16 4In addition, I count rows per value for the first column in the CI:
select RunID, count(*) as rCount from InsertDest group by RunID
RunID rCount
----------- -----------
0 8037225
1 8037225
2 8037225
3 8037225
4 8037225
5 8037225
6 8037225
7 8037225
8 8037225
9 8037225This is what I get after round 2 (executed in 220 seconds and grew LDF to 21.7 GB):
avg_fragmentation_in_percent fragment_count page_count avg_page_space_used_in_percent record_count
---------------------------- -------------------- -------------------- ------------------------------ --------------------
0.01 287 837211 99.6 160744500
0.076 193 3942 62.95 837211
14.286 21 21 55.64 3942
0 1 1 6.2 21I have taken the still very low fragmentation in the first of the 4 rows to mean that the second insert was able to "append" the new data at the end of te CI. But I am not really sure how to interpret this data. Do you have an opinion on it?
Here is the row count per value in the first columns in the CI order after the second insert:RunID rCount
----------- -----------
0 8037225
1 8037225
2 8037225
3 8037225
4 8037225
5 8037225
6 8037225
7 8037225
8 8037225
9 8037225
10 8037225
11 8037225
12 8037225
13 8037225
14 8037225
15 8037225
16 8037225
17 8037225
18 8037225
19 8037225 -
Ah... my apologies. I didn't read one of your previous posts completely to find out that you are, indeed, doing your secondary inserts in an "Append Only" fashion. That post also clearly states that you're using the SIMPLE recovery model, as well, as so I'm a bit embarrassed that I asked that question separately on top of it all.
There seems to be a huge contradiction between what is stated in the article that Sue posted and the article that you posted the later of which is a snippet of a much larger document that explains it all in a much more detailed fashion and supports the idea that secondary inserts being minimally logged for new page allocations, which is what your code and data appears to be doing.
Guess it's going to come down to doing some testing on my end. I don't have 2017 but I do have 2016. I'll play a bit after work tonight.
As a bit of a sidebar, I do remember seeing an article about some form of a true up for the log file after a minimally logged insert. I'll see if I can find that article, as well.
Heh... this reminds me of what my Dad told me even before the internet was available... "Half of all that is written is wrong and the other half is written in such a fashion that you can't tell".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Hi Jeff
Please do not apologize for anything. I am just ecstatic that someone is helping out. Thank you.
Good point from your dad. If only SQL Server's logfile grew at the same rate that the database file does when doing fully logged inserts...
Thomas
-
Ok, Thomas... it's official. You're not actually losing your mind. 😀 Minimal logging on the second insert does NOT work as advertised either on 2008 ( Dev Edition) or 2016 (Enterprise Edition). I even explicitly enabled Trace Flag 610 on both just to be sure.
I will say that sp_lock still shows that the 2nd insert is a "Bulk Operation" but the logfile still grows the same amount whether it's bulk logged or not. The second insert also takes the same amount of time whether it's bulk logged or not (WITH (TABLOCK) being used or not is the only difference). If you make the mistake of leaving out the OPTION (RECOMPILE on the second insert, then you can have a problem where the insert takes nearly 3 times longer especially when a background CHECKPOINT comes into play on smaller memory machines.
If we look at the "Pre-requisites for minimal logging at the following URL...
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms190422%28v%3dsql.105%29
... it clearly states (including the note)...- If the table has a clustered index and is empty, both data and index pages are minimally logged. In contrast, if a table has a clustered index and is non-empty, data pages and index pages are both fully logged regardless of the recovery model.
Note
If you start with an empty table and bulk import the data in batches, both index and data pages are minimally logged for the first batch, but from the second batch onwards, only data pages are bulk logged.... which is a direct contradiction of what it say in the link you pointed out, which is also the incorrect one because you've seen it not be true and so have I (now).--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - If the table has a clustered index and is empty, both data and index pages are minimally logged. In contrast, if a table has a clustered index and is non-empty, data pages and index pages are both fully logged regardless of the recovery model.
-
I'm doing another test... there might be a bit of a nuance with DBCC SHRINKFILE that I previously missed.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Once again: Thank you so much for looking into this.
I really really hope that we are both wrong.
Thomas
-
Nope... Didn't miss a thing. I'm posting my test because 1) I made a claim against the MS documentation and 2) I want other people to have proof and 3) I want other people to have a chance to peer review my code to make sure that I didn't make a mistake. 😉
Here's the test database that I created for the test... please DO read the comments! (And apologies in advance for the indentation problems the forum software on this site has :Whistling:
USE master;
CREATE DATABASE [JBMMinLogTest] ON PRIMARY
(--You may need to change the path here for the FILENAME here.
NAME = N'JBMMinLogTest'
, FILENAME = N'C:\SQLData\JBMMinLogTest.mdf'
, SIZE = 2457600KB --2400MB, we're not measuring this
, FILEGROWTH = 102400KB -- 100MB, we're not measuring this
)
LOG ON
(--You may need to change the path here for the FILENAME here.
NAME = N'JBMMinLogTest_log'
,FILENAME = N'C:\SQLLogs\JBMMinLogTest_log.ldf'
,SIZE = 10240KB -- ONLY 10MB to make measurements more accurate
,FILEGROWTH = 10240KB -- ONLY 10MB to make measurements more accurate
)
;
GO
ALTER DATABASE [JBMMinLogTest] SET RECOVERY SIMPLE;
USE [JBMMinLogTest];
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false;
GO
Here's the test harness... again, DO READ THE COMMENTS!
USE [JBMMinLogTest] --Note: Change this to the database you created for this test.
;
GO
RAISERROR('
--=============================================================================
-- Presets
-- Note: Make a new database and then run this code in that database.
-- The new database should be in the SIMPLE Recovery Model with size
-- and growth for the log file at 10MB each to increase accuracy of
-- measuring the size of the log file.
--
-- Also note if you run this in the "Results to Text" mode, you''ll
-- get fully documented output. If you run in the "Results to Grid"
-- mode, the grid will contain a summary.
--
-- Reference thread that started this investigation:
-- https://www.sqlservercentral.com/Forums/1488290/Minimal-Logging
-- Created by: Jeff Moden - 23 Mar 2019
--=============================================================================
',0,0) WITH NOWAIT
;
--===== Turn on the Trace Flag that's supposed to help. This won't affect 2016+.
DBCC TRACEON (610,-1); -- Be careful. The "-1" makes this a global setting
-- and this code does NOT turn it off later! you'll
-- need to do that manually if you don't want it on.--===== If the test tables already exist, drop them just to make reruns in
-- SSMS easier.
IF OBJECT_ID('dbo.SourceTable') IS NOT NULL DROP TABLE dbo.SourceTable;
IF OBJECT_ID('dbo.TargetTable') IS NOT NULL DROP TABLE dbo.TargetTable;
CHECKPOINT;
GO
--===== Shrink the log file so we can measure its growth easily.
DBCC SHRINKFILE (2,1) WITH NO_INFOMSGS; --LDF File
CHECKPOINT;
GO
--===== Display the size of the files
-- CHAR is to force the column width for display purposes.
SELECT StartingSize = CAST(name AS CHAR(35))
,SizeMB = size/128
FROM sys.database_files
;
GO
RAISERROR('
--=============================================================================
-- Create the tables with the right Clustered Indexes for this test.
-- Note that "RndInt" was originally "RunID" to match the original
-- problem. It no longer matters because the secondary insert won''t be
-- minimally logged anyway and wanted to take it out of the picture to
-- avoid confusion. It''s just there to have something to insert into.
-- The UniqueID (an IDENTITY column) is all that really matters for this
-- test.
--=============================================================================
',0,0) WITH NOWAIT
;
CREATE TABLE dbo.SourceTable
(
UniqueID INT IDENTITY(1,1)
,RndInt INT
,OtherStuff CHAR(1000)
)
;
CREATE UNIQUE CLUSTERED INDEX IXC_SourceTable ON dbo.SourceTable (UniqueID)
;
CREATE TABLE dbo.TargetTable
(
UniqueID INT IDENTITY(1,1)
,RndInt INT
,OtherStuff CHAR(1000)
)
;
CREATE UNIQUE CLUSTERED INDEX IXC_TargetTable ON dbo.TargetTable (UniqueID)
;
GO
RAISERROR('
--=============================================================================
-- Populate the source table.
-- The INSERT is Minimally logged here.
--=============================================================================
',0,0) WITH NOWAIT
;
WITH cteGenRand AS
(
SELECT TOP 1000000
RndInt = CRYPT_GEN_RANDOM(1)%20 --Generates numbers 0 through 19
,OtherStuff = CRYPT_GEN_RANDOM(4)
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2
) -- Note that we're sorting on RndInt to help sort IDENTITY.
INSERT INTO dbo.SourceTable WITH (TABLOCK)
(RndInt,OtherStuff)
SELECT RndInt,OtherStuff
FROM cteGenRand
ORDER BY RndInt,OtherStuff --See note just above INSERT here.
OPTION (RECOMPILE)
;
CHECKPOINT;
GO
--===== Display the size of the files
-- CHAR is to force the column width for display purposes.
SELECT [AfterSourceInsert (IS MinLogged)] = CAST(name AS CHAR(35))
,SizeMB = size/128
FROM sys.database_files
;
GO
RAISERROR('
--=============================================================================
-- FIRST INSERT INTO TARGET TABLE.
--
-- Note: The 4th row in the first chart in the following ref says it
-- should be minimally logged and it IS.
-- https://blogs.msdn.microsoft.com/sql_server_team/sql-server-2016-minimal-logging-and-impact-of-the-batchsize-in-bulk-load-operations/
--=============================================================================
',0,0) WITH NOWAIT
;
--===== Shrink the log file so we can measure its growth easily.
DBCC SHRINKFILE (2,1) WITH NO_INFOMSGS; --LDF File
CHECKPOINT;
GO
--===== Display the size of the files
-- CHAR is to force the column width for display purposes.
SELECT BeforeFirstInsert = CAST(name AS CHAR(35))
,SizeMB = size/128
FROM sys.database_files
;
GO
INSERT INTO dbo.TargetTable WITH (TABLOCK)
(RndInt,OtherStuff)
SELECT RndInt,OtherStuff
FROM dbo.SourceTable
WHERE UniqueID <= 500000
ORDER BY UniqueID
OPTION (RECOMPILE)
;
CHECKPOINT;
GO
--===== Display the size of the files
-- CHAR is to force the column width for display purposes.
SELECT [AfterFirstInsert (IS MinLogged)] = CAST(name AS CHAR(35))
,SizeMB = size/128
FROM sys.database_files
;
GO
RAISERROR('
--=============================================================================
-- SECOND INSERT INTO TARGET TABLE.
--
-- Note: The 7th row in the first chart in the following ref says it
-- should be minimally logged but it IS NOT MINIMALLY LOGGED.
-- https://blogs.msdn.microsoft.com/sql_server_team/sql-server-2016-minimal-logging-and-impact-of-the-batchsize-in-bulk-load-operations/
--
-- The following reference clearly states that it won''t be.
-- https://docs.microsoft.com/en-us/sql/relational-databases/import-export/prerequisites-for-minimal-logging-in-bulk-import?view=sql-server-2017
--
-- From the reference:
-- "In contrast, if a table has a btree based clustered index and is
-- non-empty, data pages and index pages are both fully logged
-- regardless of the recovery model."
--
-- To make matters worse, there''s a conflicting statement in a note
-- box right below the paragraph that contains the above quote, which
-- is also NOT TRUE because supplemental INSERTs will NOT be
-- Minimally Logged":
-- "If you start with an empty table rowstore table and bulk import
-- the data in batches, both index and data pages are minimally
-- logged for the first batch, but from the second batch onwards,
-- only data pages are bulk logged."
--=============================================================================\
',0,0) WITH NOWAIT
;
--===== Shrink the log file so we can measure its growth easily.
DBCC SHRINKFILE (2,1) WITH NO_INFOMSGS; --LDF File
CHECKPOINT;
GO
--===== Display the size of the files
-- CHAR is to force the column width for display purposes.
SELECT BeforeSecondInsert = CAST(name AS CHAR(35))
,SizeMB = size/128
FROM sys.database_files
;
GO
INSERT INTO dbo.TargetTable WITH (TABLOCK)
(RndInt,OtherStuff)
SELECT RndInt,OtherStuff
FROM dbo.SourceTable
WHERE UniqueID > 500000
ORDER BY UniqueID
OPTION (RECOMPILE)
;
CHECKPOINT;
GO
--===== Display the size of the files
-- CHAR is to force the column width for display purposes.
SELECT [AfterSecondInsert (NOT MinLogged)] = CAST(name AS CHAR(35))
,SizeMB = size/128
FROM sys.database_files
;
GO
Here are the fully documented results ("Text in Results" display mode). This set of results is from 2008 (Dev Edition) running on my laptop. Results on my 2016 (Enterprise Edition) development box at work has the same proof that the SECOND INSERT IS NOT MINIMALLY LOGGED despite what the following reference states (see the output below for more detail on that):
https://blogs.msdn.microsoft.com/sql_server_team/sql-server-2016-minimal-logging-and-impact-of-the-batchsize-in-bulk-load-operations/--=============================================================================
-- Presets
-- Note: Make a new database and then run this code in that database.
-- The new database should be in the SIMPLE Recovery Model with size
-- and growth for the log file at 10MB each to increase accuracy of
-- measuring the size of the log file.
--
-- Also note if you run this in the "Results to Text" mode, you'll
-- get fully documented output. If you run in the "Results to Grid"
-- mode, the grid will contain a summary.
--
-- Reference thread that started this investigation:
-- https://www.sqlservercentral.com/Forums/1488290/Minimal-Logging
-- Created by: Jeff Moden - 23 Mar 2019
--=============================================================================
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
StartingSize SizeMB
----------------------------------- -----------
JBMMinLogTest 2400
JBMMinLogTest_log 4(2 row(s) affected)
--=============================================================================
-- Create the tables with the right Clustered Indexes for this test.
-- Note that "RndInt" was originally "RunID" to match the original
-- problem. It no longer matters because the secondary insert won't be
-- minimally logged anyway and wanted to take it out of the picture to
-- avoid confusion. It's just there to have something to insert into.
-- The UniqueID (an IDENTITY column) is all that really matters for this
-- test.
--=============================================================================--=============================================================================
-- Populate the source table.
-- The INSERT is Minimally logged here.
--=============================================================================(1000000 row(s) affected)
AfterSourceInsert (IS MinLogged) SizeMB
----------------------------------- -----------
JBMMinLogTest 2400
JBMMinLogTest_log 64(2 row(s) affected)
--=============================================================================
-- FIRST INSERT INTO TARGET TABLE.
--
-- Note: The 4th row in the first chart in the following ref says it
-- should be minimally logged and it IS.
-- https://blogs.msdn.microsoft.com/sql_server_team/sql-server-2016-minimal-logging-and-impact-of-the-batchsize-in-bulk-load-operations/
--=============================================================================
BeforeFirstInsert SizeMB
----------------------------------- -----------
JBMMinLogTest 2400
JBMMinLogTest_log 4(2 row(s) affected)
(500000 row(s) affected)
AfterFirstInsert (IS MinLogged) SizeMB
----------------------------------- -----------
JBMMinLogTest 2400
JBMMinLogTest_log 34(2 row(s) affected)
--=============================================================================
-- SECOND INSERT INTO TARGET TABLE.
--
-- Note: The 7th row in the first chart in the following ref says it
-- should be minimally logged but it IS NOT MINIMALLY LOGGED.
-- https://blogs.msdn.microsoft.com/sql_server_team/sql-server-2016-minimal-logging-and-impact-of-the-batchsize-in-bulk-load-operations/
--
-- The following reference clearly states that it won't be.
-- https://docs.microsoft.com/en-us/sql/relational-databases/import-export/prerequisites-for-minimal-logging-in-bulk-import?view=sql-server-2017
--
-- From the reference:
-- "In contrast, if a table has a btree based clustered index and is
-- non-empty, data pages and index pages are both fully logged
-- regardless of the recovery model."
--
-- To make matters worse, there's a conflicting statement in a note
-- box right below the paragraph that contains the above quote, which
-- is also NOT TRUE because supplemental INSERTs will NOT be
-- Minimally Logged":
-- "If you start with an empty table rowstore table and bulk import
-- the data in batches, both index and data pages are minimally
-- logged for the first batch, but from the second batch onwards,
-- only data pages are bulk logged."
--=============================================================================
BeforeSecondInsert SizeMB
----------------------------------- -----------
JBMMinLogTest 2400
JBMMinLogTest_log 4(2 row(s) affected)
(500000 row(s) affected)
AfterSecondInsert (NOT MinLogged) SizeMB
----------------------------------- -----------
JBMMinLogTest 2400
JBMMinLogTest_log 1514(2 row(s) affected)
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Just to be clear:
In addition to disproving claims made by Microsoft in the referenced blog post from 2016, the tests Jeff and I have independently conducted also disprove the same claim in the original Data Loading Performance Guide. The table Jeff referenced in the blog post is essentially an updated version of Table 1 in the Data Loading Performance Guide, which was simplified because TF610 is now always active. Already back in 2008 Microsoft claimed in row 6 and 7 of Table 1 that minimal logging could be achieved with data already in the table. It was false then and it is false now.
By the way: I just noted a small difference in the text between the 2088 and 2017 versions of the prerequisites article.
2008:
If the table has a clustered index and is empty, both data and index pages are minimally logged. In contrast, if a table has a clustered index and is non-empty, data pages and index pages are both fully logged regardless of the recovery model.2016/7:
If the table has a clustered index and is empty, both data and index pages are minimally logged. In contrast, if a table has a btree based clustered index and is non-empty, data pages and index pages are both fully logged regardless of the recovery model.I wonder if that makes a difference?
Thomas
- ti 93734 - Saturday, March 23, 2019 11:06 AM
A "B-Tree" based Clustered Index is what they were talking about in 2008. In other words, they didn't have to be so explicit in 2008 because 2008 didn't have Column Store Clustered Indexes, which are NOT "B-Tree" based. It's a shame they didn't explicitly state it that way to avoid confusion for folks that may not know.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Got it. Thanks.
Viewing 15 posts - 16 through 30 (of 33 total)
You must be logged in to reply to this topic. Login to reply