Is there a way to implement ROWS between logic?
-
Hi everyone
SUM function has the option to select ROWS BETWEEN parameter to allow for a rolling sum calculation. This is very useful. I would like to do the same for PERCENT_RANK but this function does not have this option available. Suppose there are 100 daily records and I want to calculate the PERCENT_RANK on each day using the last 10 days as input. The first 9 days don't have enough data so it would be returning NULL but on the 10th day there are 10 records so it should return the PERCENT_RANK using the past 10 days (day 1 to 10). On the 11th day, it would look at day 2 to 11 and return the PERCENT_RANK etc. The sub-query would identify the last 10 records (including current day record) and disregard all others and then feed that to PERCENT_RANK. Is there a way to partition the records via a sub-query and feed it to PERCENT_RANK so it functions as if the ROWS BETWEEN logic was used?
The table has three columns - Unit, Date, Metric. The rolling PERCENT_RANK is calculated on Metric for each Unit.
Thank you
-
Thanks for posting your issue and hopefully someone will answer soon.
This is an automated bump to increase visibility of your question.
-
Got sample data? I wanna see if you're right.
- pietlinden wrote:
Can you not insert a rolling 10 days window? Something along the lines of
PERCENT_RANK() OVER (PARTITION BY year ORDER BY date DESC ROWS BETWEEN 10 PRECEDING AND CURRENT ROW)
This would be ideal but it doesn't work.
-
Got data? What if you use OUTER/CROSS APPLY to retrieve the top N records?
Prove it doesn't work. Provide some data.
- pietlinden wrote:
Got data? What if you use OUTER/CROSS APPLY to retrieve the top N records? Prove it doesn't work. Provide some data.
np. here you go:
drop table if exists #temp1
create table #temp1
(
unit varchar(10) not null,
test_date date not null,
metric float not null
)
insert into #temp1
values ('abc', '2025-01-01', 23.543),
('abc', '2025-01-02', 16.234),
('abc', '2025-01-03', 2.56245),
('abc', '2025-01-04', 11.789904),
('abc', '2025-01-08', 6.33),
('abc', '2025-01-09', 8.02),
('abc', '2025-01-11', 23.4214),
('abc', '2025-01-14', 0.023),
('abc', '2025-01-15', 4.08788),
('abc', '2025-01-21', 12.03),
('abc', '2025-01-31', 8.49329),
('abc', '2025-02-04', 2.0904),
('abc', '2025-02-05', 2.76),
('abc', '2025-02-06', 1.99),
('abc', '2025-02-07', 1.88),
('abc', '2025-02-08', 5.943),
('abc', '2025-02-09', 0.62)
select*,
PERCENT_RANK() OVER (PARTITION BY unit ORDER BY test_date DESC ROWS BETWEEN 10 PRECEDING AND CURRENT ROW)
from#temp1Error:
Msg 10752, Level 15, State 3, Line 33
The function 'PERCENT_RANK' may not have a window frame.
Completion time: 2025-06-19T12:04:46.6328194-07:00 - pietlinden wrote:
Got data? What if you use OUTER/CROSS APPLY to retrieve the top N records? Prove it doesn't work. Provide some data.
My SQL skills are not too sharp. I am a rookie/hobbyist. I have no clue how to use OUTER/CROSS APPLY operators. How would I use this to get the logic I am looking for?
-
I think this is what you are looking for.
-- For each test_date, determine the last date to count in a 10 date range
; WITH DateAnalysis AS
(SELECT *,
LastDateToCount = LAG(test_date, 9, NULL) OVER (PARTITION BY unit ORDER BY test_date DESC)
FROM #temp1
)
-- Get the dates within each range and assign a GroupNumber
, DateGroups AS
(SELECT t1.*,
da.LastDateToCount,
GroupNumber = DENSE_RANK() OVER (PARTITION BY da.unit ORDER BY da.LastDateToCount DESC)
FROM #temp1 t1
CROSS JOIN DateAnalysis da
WHERE t1.unit = da.unit
AND t1.test_date >= da.test_date
AND t1.test_date <= da.LastDateToCount
)
-- Now that the groups have been established we can perform PERCENT_RANK
SELECT *,
RowNumInThisGroup = ROW_NUMBER() OVER (PARTITION BY unit, GroupNumber ORDER BY test_date DESC),
PERCENT_RANK() OVER (PARTITION BY unit, GroupNumber ORDER BY test_date DESC)
FROM DateGroupsUpdated to include unit in partitions
- SoCal_DBD wrote:
I think this is what you are looking for.
-- For each test_date, determine the last date to count in a 10 date range
; WITH DateAnalysis AS
(SELECT *,
LastDateToCount = LAG(test_date, 9, NULL) OVER (PARTITION BY unit ORDER BY test_date DESC)
FROM #temp1
)
-- Get the dates within each range and assign a GroupNumber
, DateGroups AS
(SELECT t1.*,
da.LastDateToCount,
GroupNumber = DENSE_RANK() OVER (PARTITION BY da.unit ORDER BY da.LastDateToCount DESC)
FROM #temp1 t1
CROSS JOIN DateAnalysis da
WHERE t1.unit = da.unit
AND t1.test_date >= da.test_date
AND t1.test_date <= da.LastDateToCount
)
-- Now that the groups have been established we can perform PERCENT_RANK
SELECT *,
RowNumInThisGroup = ROW_NUMBER() OVER (PARTITION BY unit, GroupNumber ORDER BY test_date DESC),
PERCENT_RANK() OVER (PARTITION BY unit, GroupNumber ORDER BY test_date DESC)
FROM DateGroupsUpdated to include unit in partitions
Thank you for this. The test data has 17 records but when I run your query I am getting 80 records. Do you know why that is happening?
-
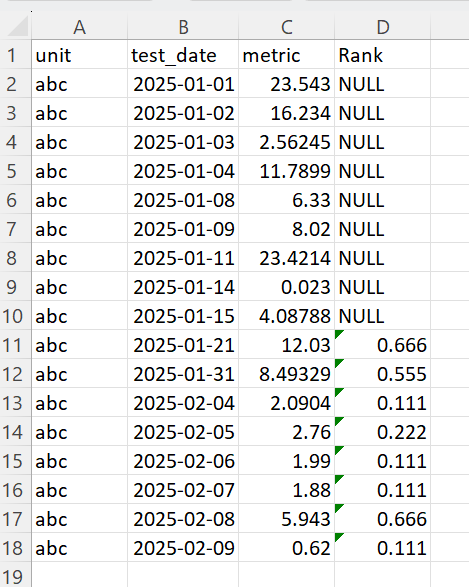
I forgot to include the expected results. Sorry about that. Here you go:

-
I used temp tables so you can just see the iterations of the data. This will match your expected results.
DROP TABLE IF EXISTS #DateRanges
SELECT *,
DateGroup = ROW_NUMBER() OVER (PARTITION BY unit ORDER BY test_date),
FirstDateToCount = LAG(test_date, 9, NULL) OVER (PARTITION BY unit ORDER BY test_date)
INTO #DateRanges
FROM #temp1
--SELECT * FROM #DateRanges ORDER BY unit, test_date
DROP TABLE IF EXISTS #Rank
SELECT dr.DateGroup,
RowInThisGroup = ROW_NUMBER() OVER (PARTITION BY dr.unit, dr.DateGroup ORDER BY t1.test_date),
t1.*,
MetricRank = PERCENT_RANK() OVER (PARTITION BY dr.unit, dr.DateGroup ORDER BY t1.metric)
INTO #Rank
FROM #temp1 t1
CROSS JOIN #DateRanges dr
WHERE t1.unit = dr.unit
AND t1.test_date >= dr.FirstDateToCount
AND t1.test_date <= dr.test_date
--SELECT * FROM #Rank ORDER BY unit, DateGroup, test_date
SELECT t1.*, r.MetricRank
FROM #temp1 t1
LEFT JOIN #Rank r
ON t1.unit = r.unit
AND t1.test_date = r.test_date
AND r.RowInThisGroup = 10
ORDER BY t1.Unit, t1.test_date -
this works! thank you so much!!!
I tried the query on a much larger dataset and after 4.5 hours it is still running. The dataset has about 10million records. Is there any way to make it more efficient?
-
Initial thoughts (although I fully expect the heavy hitters on this forum to come up with better suggestions i.e. my hero Jeff Moden), is that you could look at doing it in batches. No doubt your actual table is not a temp table so indexes would be needed - on unit and date. In the example you provided, the "unit" is all "abc". If you have different units, you could process each unit in their own batch. Yeah, this would be a pig if you just ran that on a 10M row table in one query.
-
I tried the batch approach yesterday. There are over 5000 units and one unit took about 6 seconds to run. If I did this in batches of one unit at a time then it will take close to 9 hours to process all units. 🙁
-
To add to SoCal_DBD's reply - which of the 3 queries is being super slow and how big is your tempdb and do you still have space on disk for tempdb to grow?
With 10 million rows, putting all that data into temp tables is likely going to eat up a lot of tempdb space and may be triggering a lot of tempdb autogrow which is a slow operation.
As for optimizing it, I'm not the best at optimizing queries, but for a slight performance improvement, you may be able to use the PK (or whatever you are using for a row uniquifier) from #temp1 to pick which columns to insert into #rank rather than putting ALL columns in (ie duplicating data). Same thing with #dateranges. The query is triplicating the data (#temp1 contains all data, #dateranges contains all data plus 2 extra columns, #rank contains all data from #temp1 plus 3 columns). Reducing the amount of duplicated data by only pulling in the primary key to each of those should improve performance and reduce data duplication.
Reducing data duplication should speed things up a little bit. Maybe not drop it from 4.5 hours to 4.5 minutes, but it should improve performance. Also, if you can pre-grow tempdb (assuming it is getting full and growing while your query runs) can be beneficial.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system.
Viewing 15 posts - 1 through 15 (of 15 total)
You must be logged in to reply to this topic. Login to reply