Interview Question
-
Hi Team ,
Today i had an interview call. there was a question asked to me . I could answer the question but the interviewer was asking me to give more optimized solution
Question
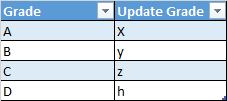
There is a table which has 10 lakh rows . The column grade in the table needs to be update .

I answered the question by saying we can write case statement.
update table
set grade =
case
when grade = A then x
when grade = B then y
when grade = C then z
when grade = D then h
else grade end
The interviewer said is there any more optimized way to do it . He also said what if the developer does any typo error .
Can you guys help me understand what the interview was expecting here .
Thanks & Regards
Arvind
-
I'd probably use a mapping table rather than a rambling CASE statement - makes the code easier to read, particularly if there are lots of distinct grades to be updated. But I wouldn't expect it to run any faster ... it will be interesting to see what others suggest.
DROP TABLE IF EXISTS #Grade;
CREATE TABLE #Grade
(
Grade CHAR(1) NOT NULL
);
INSERT #Grade
(
Grade
)
VALUES
('A')
,('B')
,('C')
,('D');
SELECT *
FROM #Grade g;
DROP TABLE IF EXISTS #GradeMap;
CREATE TABLE #GradeMap
(
OldGrade CHAR(1) NOT NULL PRIMARY KEY CLUSTERED
,NewGrade CHAR(1) NOT NULL
);
INSERT #GradeMap
(
OldGrade
,NewGrade
)
VALUES
('A', 'X')
,('B', 'Y')
,('C', 'Z')
,('D', 'H');
UPDATE G
SET G.Grade = GM.NewGrade
FROM #Grade G
JOIN #GradeMap GM
ON G.Grade = GM.OldGrade;
SELECT *
FROM #Grade g; -
Since the interviewer specifically stated "what if the developer does any typo error", I'm thinking he was looking for the "mapping table" that Phil spoke of in his post.
That would also be true to solve the question of "is there any more optimized way to do it", although I hate the word "optimize" when used in such a general, nondescript way because it could mean so many different things.
For example, it will NOT "optimize" the number of logical reads done by code. Using a mapping table would only add to the number of logical reads. That will also add to the amount of memory used, although such a table will be trivial in size. I may also actually slow things down a bit compared to hard-coded constants.
It could improve performance a tiny bit but enough to be maybe be worth it. For example, a physical Tally table in memory can be, at the expense of logical reads, faster than using cCTEs ("cascading CTEs" made famous by Itzek Ben-Gan's "GetNums" function. Don't confuse the much more resource intensive rCTEs ("recursive CTEs")).
Getting back to the "what if the developer does any typo error", such a mapping table would help prevent such a thing because it's "one and done". You build the table, someone else checks it for accuracy, and you can use it forever without the worry of a typing error of the values it contains. Another advantage is that, if you need to make a global change", you only have to do it in one spot, the table, instead of having to find where all the code doesn't such a thing and changing that. Even if it's only ever done in one piece of code, it's usually cheaper and quicker to regression test and deploy a values change in a table than it is an actual code change, which would be multiplied many times if multiple pieces of code used it.
Of course, the interviewer also said "There is a table which has 10 lakh rows . The column grade in the table needs to be update [sic] ." If it's a "one off" change, there's really no need for a lookup table except maybe for purposes of posterity. Perhaps the interviewer was looking for "thinking outside the box". For example, are there one or more non-cluster (or column store but not going there) indexes on the column being changed? If so, it may be beneficial to disable those indexes, do the update, and then rebuild them because the update is going to lock the whole table (like rebuilding the indexes will do) and it may be faster than leaving those indexes active during the update.
It might also be that the interviewer was looking for a "persisted calculated column" but that's stretching things a bit because you don't know and didn't ask why the update was necessary ("It depends... why is the update necessary and is it a permanent change"?).
One other thing that you did miss in your code... How many unique values are there in the "Grade" column? If there are more than the 4 listed, a WHERE Grade IN ('A','B','C','D') would prevent all rows in possibly multiple indexes from being updated which could seriously save on the number of log file entries made even if the database isn't in the FULL recovery model. Maybe that was the "optimization" the interviewer was looking for. (you also forgot to single quote your string literals in the code).
Heh... and people sometimes hate me for this... I would ask "Developer mistake? Are you saying that you allow Developers such access to production code and they can do so without peer review and testing in a test environment"? I'd have also done a select to get an actual rowcount and to dump the results at least to a temp table to get counts of the individual grades, which would also verify that a typo wasn't made. I'd also start the code with a BEGIN TRAN so I could verify the number of rows updated and manually do a COMMIT if good and a ROLLBACK if not.
Last but not least, I'd alert the DBAs and work with them to take a log file backup (if not in the SIMPLE recovery model) just before I punched the "GO" button... just in case.
So, like almost everything else, the correct answer starts with the words "It Depends" followed by a "Even such a seemingly small change can have serious ramifications. What is the reason for the change so I can code appropriately?" dissertation of different options similar to the above.. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I think a case statement from a performance perspective is pretty much optimal. It would just need one scan of the table, it's not possible to do it in less than one scan if every row needs to be updated.
As for making a typo, it would be as easy to make a typo in creating a reference table as making a typo in your code. So if you got someone else to check the code or check the table then there would be no advantage to either.
One optimisation would be to have the values that need to be updated in the WHERE clause as method you wrote would update every row whether or not it was needed.
update table
set grade = case
when grade = A then x
when grade = B then y
when grade = C then z
when grade = D then h
else grade end
WHERE grade in('A', 'B', 'C', 'D'); -
Indexing would be the only way I see to make this faster. Whether you use a CASE or Phil's solution, I wouldn't expect one to be appreciably faster.
I did an experiment:
This code:
UPDATE dbo.StudentGrade
SET Grade = CASE
WHEN grade = 'A' THEN 'X'
WHEN grade = 'B' THEN 'Y'
WHEN grade = 'C' THEN 'Z'
WHEN grade = 'D' THEN 'H'
ELSE grade END
GOThese results:
SQL Server parse and compile time:
CPU time = 1 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Table 'StudentGrade'. Scan count 1, logical reads 25, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 15 ms.
(10000 rows affected)This code (reversed the update):
UPDATE G
SET G.Grade = GM.OldGrade
FROM StudentGrade G
JOIN #GradeMap GM
ON G.Grade = GM.NewGrade;These results:
SQL Server parse and compile time:
CPU time = 15 ms, elapsed time = 15 ms.
Table 'StudentGrade'. Scan count 1, logical reads 20025, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table '#GradeMap___________________________________________________________________________________________________________000000000016'. Scan count 1, logical reads 2, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 29 ms.
(10000 rows affected)Made a real table
CREATE TABLE GradeMap
(
OldGrade CHAR(1) NOT NULL PRIMARY KEY CLUSTERED
,NewGrade CHAR(1) NOT NULL
);
INSERT GradeMap
(
OldGrade
,NewGrade
)
VALUES
('A', 'X')
,('B', 'Y')
,('C', 'Z')
,('D', 'H');
go
UPDATE G
SET G.Grade = GM.OldGrade
FROM dbo.StudentGrade AS G
JOIN GradeMap GM
ON G.Grade = GM.NewGrade;
GOThese results:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 14 ms.
Table 'StudentGrade'. Scan count 1, logical reads 25, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'GradeMap'. Scan count 1, logical reads 2, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 4 ms.
(0 rows affected)The temp table adds some overhead, but it seems a real mapping table or the inline update aren't different.
Table def:
CREATE TABLE StudentGrade
( StudentGradeID INT NOT NULL CONSTRAINT StudentGradePK PRIMARY KEY
, StudentID INT
, Grade CHAR(1)
);
GOUsed SQL Data Generator to add 10k rows.
Viewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply