Inflow / outflow report per day
-
Ok. First of all, we need to get rid of the incremental rCTE (recursive CTE) that you're using to come up with the missing dates. Please see the following article for one of the major reasons why.
https://www.sqlservercentral.com/articles/hidden-rbar-counting-with-recursive-ctes
Instead, we'll use the cCTE (cascading CTE) method that Itzik Ben-Gan first came up with. My rendition of it is called "fnTally" and can be found at the last link in my signature line below. It IS 2005 compatible.
Shifting gears to the solution code, there's no telling how many entries you may have for each date and, since you're using SMALLDATETIME for the entry dates, it IS possible for your original Invoices and Payments tables (which I can't imagine being as simple as you posted) to have times in them as well as the multiple entries per date that I spoke of. If the tables you provided are actually "interim" tables, then this will still work but it would also work very quickly on larger, wider tables.
As always, the details are in the comments in the code. If you have any questions, please don't hesitate to ask. I tried to write it to be 100% 2005 compatible and that's the reason for the separate #Results table. Like I said, I did my testing (as 2012+ code) against two 102 million row tables and it finished about 345 milliseconds (not a mistake... about 1/3rd of a second). This code won't fair much worse.
--=====================================================================================================================
-- Presets
--=====================================================================================================================
--===== Environmental Settings
SET NOCOUNT ON
;
--===== If it exists, drop the #Results table. (We don't need this except for SQL Server < 2012.
IF OBJECT_ID('tempdb..#Results','U') IS NOT NULL
DROP TABLE #Results
;
--===== Identify the range of dates to be included in the report. These could be parameters in a stored procedure.
DECLARE @LoDate SMALLDATETIME --Should always be the first day you want to include
,@CoDate SMALLDATETIME --Should always be the day after the "end date" you want
;
SELECT @LoDate = 'Nov 2020' --Inclusive
,@CoDate = 'Dec 2020' --Exclusive. Should always be the day after the "end date" you want
;
--=====================================================================================================================
-- Pre-Aggregate and "Pivot" the data using a "CROSSTAB" to seemingly "JOIN" the dates from both tables.
--=====================================================================================================================
WITH
ctePreAgg AS
(--==== Pre-aggregate the data as an EAV using the date filters.
-- Note that we're not yet concerned with how things will be displayed. This seriously reduces the amount of data
-- we work with and is the key how quickly this code produces results.
SELECT Date = DATEADD(dd,DATEDIFF(dd,0,InvoiceDate),0) --Strip out any possible time now or in the future.
,Type = 'I' --This identifies Invoice rows
,DailyTotal = SUM(Total)
FROM dbo.Invoices
WHERE InvoiceDate >= @LoDate
AND InvoiceDate < @CoDate
GROUP BY DATEDIFF(dd,0,InvoiceDate)
UNION ALL
SELECT Date = DATEDIFF(dd,0,PaymentDate)
,Type = 'P' --This identifies Payment rows
,DailyTotal = SUM(Total)
FROM dbo.Payments
WHERE PaymentDate >= @LoDate
AND PaymentDate < @CoDate
GROUP BY DATEDIFF(dd,0,PaymentDate)
)
SELECT YYYY_MM_DD = ISNULL(DATEADD(dd,t.N,@LoDate),0) --ISNULL makes this column NOT NULL in the Temp Table
,Invoiced = SUM(CASE WHEN Type = 'I' THEN DailyTotal ELSE 0 END)
,Paid = SUM(CASE WHEN Type = 'P' THEN DailyTotal ELSE 0 END)
,CashFlow = CONVERT(DECIMAL(18,2),NULL)
INTO #Results --We have to store the results in a table to do high performance "Quirky Update" running totals
FROM ctePreAgg pa
RIGHT JOIN dbo.fnTally(0,DATEDIFF(dd,@LoDate,@CoDate)-1) t
ON pa.Date = DATEADD(dd,t.N,@LoDate)
GROUP BY t.N
;
--=====================================================================================================================
-- Calculate the running total as requested using a "Black Arts" method known as the "Quirky Update".
-- This method is incredibly fast and works in all versions of T-SQL.
--=====================================================================================================================
--===== Setup for the high performance "Quirky Update" method for doing running totals
-- Add a system named Clustered Index on the key column of the #Results table
ALTER TABLE #Results ADD PRIMARY KEY CLUSTERED (YYYY_MM_DD)
;
-- Declare and preset the local variables to support the "Quirky Update"
DECLARE @PrevCashFlow DECIMAL(18,2)
,@Control SMALLDATETIME;
SELECT @PrevCashFlow = 0.00
;
--===== Do the "Quirky Update" to produce the running total forcing index 1 (The Clustered Index)
-- to control the sort order in conjuction with the @Control variable, which is the key column.
-- The use of OPTION (MAXDOP 1) is essential to prevent parallelism for this serial task.
UPDATE tgt
SET @PrevCashFlow = CashFlow = @PrevCashFlow + Invoiced - Paid
,@Control = YYYY_MM_DD
FROM #Results tgt WITH (TABLOCK, INDEX(1))
OPTION (MAXDOP 1)
;
--=====================================================================================================================
-- Display the final result.
--=====================================================================================================================
--===== Display the final result along with the desired reformatting of the date.
SELECT YYYY_MM_DD = CONVERT(CHAR(10),YYYY_MM_DD,102)
,Invoiced, Paid, CashFlow
FROM #Results r
ORDER BY r.YYYY_MM_DD
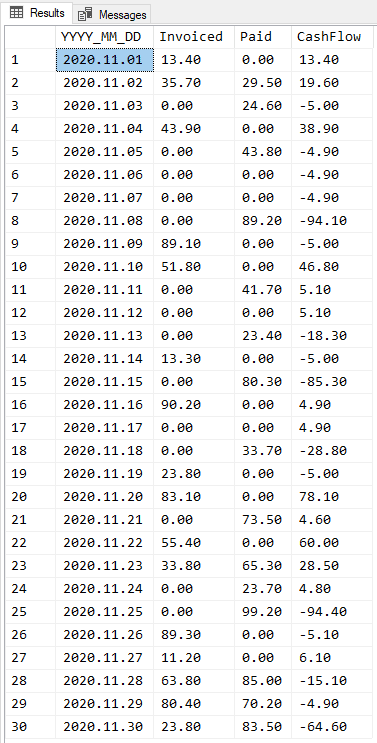
;Here are the results for the test data you provided.

Just in case someone suggests a different way (rCTE, Self Join, Aggregate based on an inequality, Cursor, While Loop), be careful... even at low row counts, they can take a heck of a toll on resources. And, BTW... the "Quirky Update" continues to work even in modern versions of SQL Server (I'm using 2017 on the laptop I built the code on).
Please see the following article about "Triangular Joins", which covers why the "Aggregate based on an inequality" is so very bad for resource usage.
https://www.sqlservercentral.com/articles/hidden-rbar-triangular-joins
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thank you, Jeff for taking the time to write and comment your response.
However, I get the following error when I run the script:
Msg 208, Level 16, State 1, Line 21
Invalid object name 'fnTally'. - milo1981 wrote:
Thank you, Jeff for taking the time to write and comment your response.
However, I get the following error when I run the script:
Msg 208, Level 16, State 1, Line 21
Invalid object name 'fnTally'.You didn't read the second paragraph of my previous response where I say "Instead, we'll use the cCTE (cascading CTE) method that Itzik Ben-Gan first came up with. My rendition of it is called "fnTally" and can be found at the last link in my signature line below."
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I tried using your function but in the function comments it says:
1. This code works for SQL Server 2008 and up.
Msg 156, Level 15, State 1, Procedure fnTally, Line 67 [Batch Start Line 0]
Incorrect syntax near the keyword 'VALUES'.
Msg 102, Level 15, State 1, Procedure fnTally, Line 86 [Batch Start Line 0]
Incorrect syntax near ','. -
Why not create the clustered index on the temp table before it gets loaded? That would save extra writing / rewriting of data, I would think.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Looks like I'll have to migrate to a newer version of SQL. Thank you everyone for their support!
- milo1981 wrote:
Looks like I'll have to migrate to a newer version of SQL. Thank you everyone for their support!
There's no need to wait... simply use the following code for the fnTally function, which is 2005 compatible (and I've not used in quite a while). Also, accept my apologies for forgetting that the one I originally pointed you to was for 2008 and above.
CREATE FUNCTION dbo.fnTally
--===== Define the I/O for this function
(@BaseValue INT, @MaxValue INT)
RETURNS TABLE WITH SCHEMABINDING AS
RETURN WITH
--===== Generate up to 1 Million rows ("En" indicates the power of 10 produced)
--E1(N) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1))n(N)),
E1(N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E3(N) AS (SELECT 1 FROM E1 a,E1 b,E1 c),
E6(N) AS (SELECT 1 FROM E3 a,E3 b)
--===== Conditionally start the sequence at 0
SELECT N = 0 WHERE @BaseValue = 0
UNION ALL
--===== Enumerate the rows generated by the cascading CTEs (cCTE)
SELECT TOP (@MaxValue)
N = CAST(ROW_NUMBER()OVER(ORDER BY N) AS INT)
FROM E6
;
GO--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
After the update the code could look something like this
drop TABLE if exists #Invoices
go
CREATE TABLE #Invoices(
[InvoiceID] [int] IDENTITY(1,1) NOT NULL,
[InvoiceDate] [smalldatetime] NULL,
[Total] [decimal](18, 2) NULL,
CONSTRAINT [PK_Invoices] PRIMARY KEY CLUSTERED
(
[InvoiceID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
drop TABLE if exists #Payments
go
CREATE TABLE #Payments(
[PaymentID] [int] IDENTITY(1,1) NOT NULL,
[PaymentDate] [smalldatetime] NULL,
[Total] [decimal](18, 2) NULL,
CONSTRAINT [PK_Payments] PRIMARY KEY CLUSTERED
(
[PaymentID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
insert #Invoices(InvoiceDate, Total) values
('2020-11-01', 13.4), ('2020-11-02', 35.7),
('2020-11-04', 43.9), ('2020-11-09', 89.1),
('2020-11-10', 51.8), ('2020-11-14', 13.3),
('2020-11-16', 90.2), ('2020-11-19', 23.8),
('2020-11-20', 83.1), ('2020-11-22', 55.4),
('2020-11-23', 33.8), ('2020-11-26', 89.3),
('2020-11-27', 11.2), ('2020-11-28', 63.8),
('2020-11-29', 80.4), ('2020-11-30', 23.8);
insert #Payments(PaymentDate, Total) values
('2020-11-02', 29.5), ('2020-11-03', 24.6),
('2020-11-05', 43.8), ('2020-11-08', 89.2),
('2020-11-11', 41.7), ('2020-11-13', 23.4),
('2020-11-15', 80.3), ('2020-11-18', 33.7),
('2020-11-21', 73.5), ('2020-11-23', 65.3),
('2020-11-24', 23.7), ('2020-11-25', 99.2),
('2020-11-28', 31.1), ('2020-11-28', 53.9),
('2020-11-29', 70.2), ('2020-11-30', 83.5);
;with
i_cte(dt, inv) as (
select cast(InvoiceDate as date), sum(Total)
from #Invoices
group by InvoiceDate),
p_cte(dt, pay) as (
select cast(PaymentDate as date), sum(Total)
from #Payments
group by PaymentDate),
dt_cte(dt) as (
select distinct dt from i_cte
union
select distinct dt from p_cte),
dt_range_cte(min_dt, max_dt) as (
select min(dt), max(dt)
from dt_cte)
select dt.dt, isnull(i.inv, 0) inv, isnull(p.pay, 0) pay,
sum(isnull(i.inv, 0)-isnull(p.pay, 0)) over (order by dt.dt) diff_cum_sum
from dt_range_cte dr
cross apply dbo.fnTally(0, datediff(day, dr.min_dt, dr.max_dt)) fn
cross apply (values (dateadd(day, fn.n, dr.min_dt))) dt(dt)
left join i_cte i on dt.dt=i.dt
left join p_cte p on dt.dt=p.dt;Output
dtinvpaydiff_cum_sum
2020-11-0113.400.0013.40
2020-11-0235.7029.5019.60
2020-11-030.0024.60-5.00
2020-11-0443.900.0038.90
2020-11-050.0043.80-4.90
2020-11-060.000.00-4.90
2020-11-070.000.00-4.90
2020-11-080.0089.20-94.10
2020-11-0989.100.00-5.00
2020-11-1051.800.0046.80
2020-11-110.0041.705.10
2020-11-120.000.005.10
2020-11-130.0023.40-18.30
2020-11-1413.300.00-5.00
2020-11-150.0080.30-85.30
2020-11-1690.200.004.90
2020-11-170.000.004.90
2020-11-180.0033.70-28.80
2020-11-1923.800.00-5.00
2020-11-2083.100.0078.10
2020-11-210.0073.504.60
2020-11-2255.400.0060.00
2020-11-2333.8065.3028.50
2020-11-240.0023.704.80
2020-11-250.0099.20-94.40
2020-11-2689.300.00-5.10
2020-11-2711.200.006.10
2020-11-2863.8085.00-15.10
2020-11-2980.4070.20-4.90
2020-11-3023.8083.50-64.60Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Again, can't use SUM() OVER for the running total on this one. The OP said he's actually using 2005.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Again, can't use SUM() OVER for the running total on this one. The OP said he's actually using 2005.
The OP said they're going to migrate to a newer version. 🙂
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
Viewing 10 posts - 16 through 25 (of 25 total)
You must be logged in to reply to this topic. Login to reply