Index Fragmentation
-
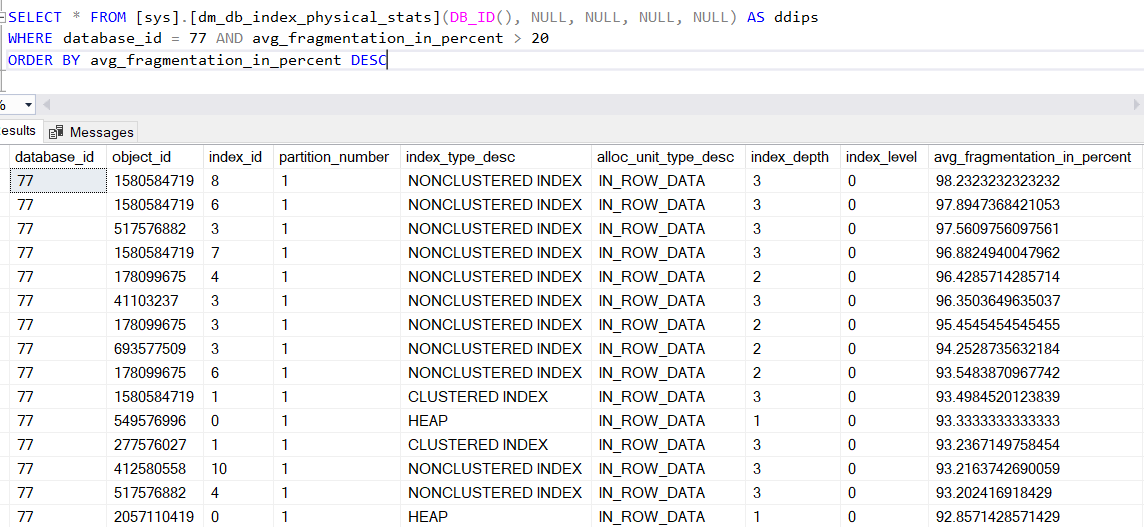
I am looking into fragmentation in one of my databases and ran across these stats - should I be rebuilding these indexes? That's what it looks like, just want some ideas/confirmation to see if I'm on the right track.

-
Index fragmentation is a very heated debate on SSC and ranges between "don't ever do it" to "do it once it gets above x%". My advice - if the index is fragmented, seeks on it are inefficient and thus reorganizing/rebuilding is not a bad idea... BUT it depends on how many rows are in the table. A table with 10 rows that are 90% fragmented will have almost no benefit to defragmenting them. But a table with 1 billion rows with 90% fragmentation MIGHT benefit from defragmentation but at the cost of heavy CPU and (if you are on standard edition) locks on the index.
A lot of times, the reason people defragment indexes is not because of performance issues; but because they read it on a forum post that it is a good idea to do so. My opinion, I like to defgragment my indexes as I have the downtime windows and none of my tables are huge (most are under 1 billion rows, a lot are even under 100 million).
Downside of defragmenting them is that it can cause a lot of page splits, especially if your fill factor is at 0 or 100 AND your inserts are not at the end of the table or your updates increase the size of the row. If your fragmentation is frequently high even after defragmenting, it likely means your fill factor is set wrong. Finding the right number though is a LOT of trial and error.
In the end, what it boils down to is - what problem are you trying to solve by dealing with index fragmentation? If it is performance on small tables, you likely won't notice a thing. If it is you are currently rebuilding indexes weekly and are thinking to change it to daily to help, it probably won't help that much... it might, but probably not. Adjusting your fill factor so your fragmentation doesn't grow to 90+% will likely help a lot more than rebuilding your indexes. Finding that "sweet spot" for fill factor though is a tough battle with lots of trial and error.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Thanks Brian. I don't mind the CPU and resource utilization. I do see what you mean about the fill factor though. I think defragmenting these is a good starting point (since I do have a night maintenance window). So, this "Average Fragmentation" is a reliable statistic to go by? Also, I noticed the same Index ID is listed multiple times, such as 3 and 1, is this the same index, or does/can the Index ID # vary with what physical index it represents (because I noticed the object ID DOES change).
-
The index ID and the Object_ID are tied together. Object_ID will tie back to a table whereas the Index ID will tie back to an index ON the table. So when you see an index ID listed multiple times, you need to look at the Object_ID to determine if it is in error (listed multiple times due to a bug of some sort in SQL Server, unlikely but possible) OR a completely different object (MUCH more likely).
Another thing to note - if Index_ID is 0, it is ALMOST ALWAYS a heap. If Index_ID is 1, it is almost always the clustered index. If it is greater than 1, it is almost always (this one I think is actually always) a non-clustered index.
If you see Index_ID of 10, it means there are 10 indexes (or more) on that table. If you add "OBJECT_NAME(object_ID)" to your SELECT * (ie SELECT OBJECT_NAME(object_id),*), you can see the table name that the index is associated with.
Also, since you are passing in db_id() as a parameter to dm_db_index_physical_stats, the "WHERE database_id = 77" is not needed. it will always be 77 UNLESS you change which dataabase you are in.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
I did get the table name to work --- will need to play around with it to get the database name, and the index name to be helpful.
In regards to your statement from your first post; "Adjusting your fill factor so your fragmentation doesn't grow to 90+% will likely help a lot more than rebuilding your indexes. " Won't I need to rebuild the indexes after I change the fill factor? I was planning on setting them to 90%. I realize this is controversial and debatable, but need to start somewhere, and I have room to play in this database if it hurts performance.
-
"Another thing to note - if Index_ID is 0, it is ALMOST ALWAYS a heap. If Index_ID is 1, it is almost always the clustered index. If it is greater than 1, it is almost always (this one I think is actually always) a non-clustered index."
Index_id = 0 is ALWAYS a HEAP, Index_id = 1 is ALWAYS a clustered index and Index_id > 1 is ALWAYS a nonclustered index!!!!!!
- stevec883 wrote:
I did get the table name to work --- will need to play around with it to get the database name, and the index name to be helpful.
In regards to your statement from your first post; "Adjusting your fill factor so your fragmentation doesn't grow to 90+% will likely help a lot more than rebuilding your indexes. " Won't I need to rebuild the indexes after I change the fill factor? I was planning on setting them to 90%. I realize this is controversial and debatable, but need to start somewhere, and I have room to play in this database if it hurts performance.
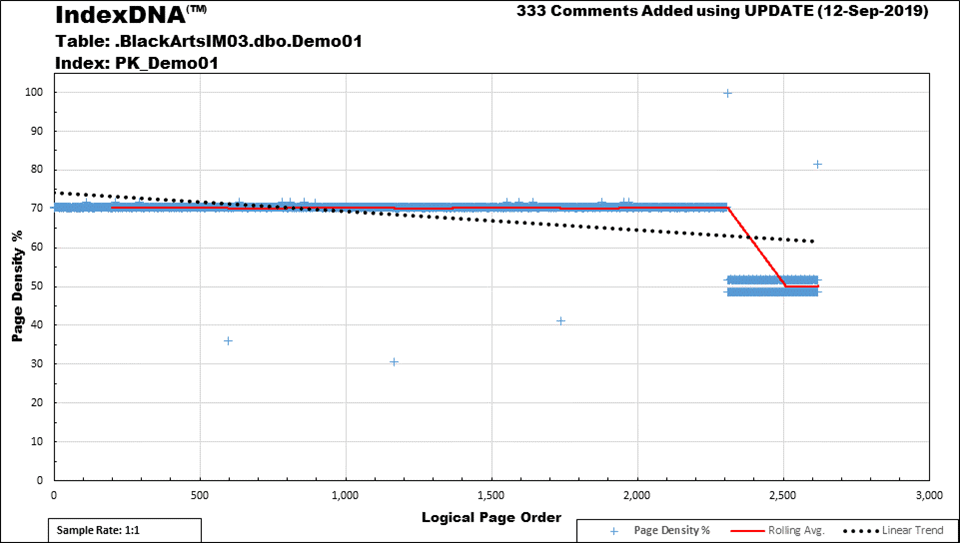
First of all, the graphic in the original post is missing several critical outputs and you REALLY need to know those before even thinking of starting defragmentation.
page_count
avg_page_space_used_in_percent
I'll also tell you that the supposed "Best Practices" for doing index maintenance are incorrect and will frequently setup the data in indexes so that there will be more page splits and more of the related fragmentation. There are (from what I've found in about 400 hours of testing and experimentation, 6 different patterns that affect indexes and doing things like blindly setting the Fill Factor can not only be a complete waste of time but also cost you dearly in a whole lot of areas, especially memory usage. Lowing the Fill Factor is absolutely NOT a guarantee that fragmentation will be prevented. On certain indexes, it can be a god-send. But you have to know how about the insert/update pattern and whether or not "ExpAnsive" updates are occurring because they're "ExpEnsive".
For example, why is this index fragmenting, why is having a lower Fill Factor a complete waste of memory, and what can you actually do to prevent the index from fragmenting at all?
Most people don't even have a clue that their indexes are doing this and it's especially prevalent when it comes to "ever-increasing keyed" indexes. The space above the blue line looks like a 30% waste of memory but, if you consider the extra pages the system had to create to use (in this case) a 70% fill factor (was for demo to make it painfully obvious), you actually end up with a whopping 42% wasted memory and, as you can tell by the line dipping to two bands near the 50% mark, it does absolutely NOTHING to prevent fragmentation.
A 90% Fill Factor will waste "only" an actual 11% of memory but it will still do absolutely NOTHING to prevent fragmentation and this type of index is very, very common.
I'm NOT saying that index maintenance shouldn't be done but I will say that doing index maintenance incorrectly is worse than doing none at all and I'll also state that what people currently use as supposed "Best Practices" for index maintenance is so very wrong. It was the cause of some very major blocking on the morning-after index maintenance on my systems and on the systems of a couple of people that have been working on this mess with index defragmentation with me. It even says in the MS documentation that it was meant only as a starting point and that experimentation on each index is required.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Thanks for your take Jeff. I did look into it much more and realized it's mainly about HOW the page is used (as you touched on). After some reading, I realized you could easily have a table that is only being read, and inserts at the end of the table; in this case, you'd want a 100 fill factor to have SQL read less pages, so it DEPENDS, right? So I agree it makes no sense to adjust a fill factor when you don't know anything about a tables use in the world (so there is no "standard" practive, I agree)
Another thing you mentioned and I'm curious what your take is; if you have a lower fill factor, say 70 percent like in your example, and that would yeild 42% wasted space. Wouldn't the open space be filled if it's a table with many inserts or updates (that happen to increase data in the middle)? There would be less page splits (so less fragmentation maybe?) and it could even be a great guess (after a lot of experimentation) to set them so the empty space gets utilized. So I'm wondering why you call it "wasted", couldn't it go to the right use under the right circumstances of course.
And I was wondering what you thought on fragmentation; There can be just physical fragmentation on the drive that needs to be defragged, and this should help performance(?) When I am thinking in terms of how a table is used, I'm thinking of that in the rhealm of logical fragmentation. So I'm think that running a defrag (without changeing the fill factor) would be a good thing on its own. You had mentioned a defrag venture cause blocking the next day, how did this happen?
- stevec883 wrote:
(so there is no "standard" practive, I agree)
I'm in the process of trying to create one. Some of it is rock solid and some of it is still a work-in-progress. You've identified a part of it. Static/nearly static tables and "ever-increasing" indexes that suffer no "expansive" updates. I rebuild the static tables at 100% so I can write code that knows what they are just by looking at the Fill Factor and the "clean" "ever-increasing" ones get rebuilt at 99% so I can tell what they are just by looking at the Fill Factor. On the latter, even those eventually get a little fragmented just because not all inserts are in contiguous extents. They end up fragmenting about 1-2% in 4 years or so.
I can let you in on some of the other things I'm hammering out... After I evaluate indexes for 100% or 99%, then I do the following evaluations in the order listed.
- If a table has some pretty high logical fragmentation but has a page density near the max for the given row widths, it's because of a phenomena I call "Sequential Silos". I rebuild those at 98% because there's nothing you can do about it and to identify them as "Sequential Silos" just by checking the Fill Factor.
- For indexes that DO have ever increasing indexes that suffer "end of index" fragmentation because of an INSERT followed Expansive Update of the rows recently inserted, I rebuild/mark those with an 97% Fill Factor. The "7" is like a "footless" 2 , which means I have something "2 do" to the index to fix it but can't get to it right now.
- Anything with a random GUID or other seriously "random distribution", I do a couple of things... First, only use REBUILD on these. REORGANIZE does nothing to prevent fragmentation on these types of indexes and, in fact, makes the data stored on the pages much more prone to fragmentation. Depending on the insert rate and the kind of updates it may suffer, I'll set these indexes to 71, 81, or 91%. The "1" reminds me that it's incredibly important to REBUILD these indexes just as soon as they start to fragment because all of the pages fill at the same rate and they all get full at the same time. Once a couple of them start to fragment (anything over 1% according to my rules), they need to be REBUILT that night because the page splits and resulting fragmentation are at a tipping point and will soon "avalanche"... like the whole next day and the day after.These are the indexes where lowering the FILL FACTOR is guaranteed to make a good difference and, as you say, the space isn't wasted because the pages do fill up. I've actually done some testing that shows that it actually wastes a whole lot less space when you REBUILD rather than REORGANIZE these types of indexes and, like I said, REBUILD is much more effective at preventing fragmentation and can go weeks or even months with absolutely zero page splits... not even the supposed good ones. There are a lot of reasons to avoid GUIDs but, if you know the right way to maintain them, fragmentation isn't actually a reason to avoid them because they're actually one of the best in the world of fragmentation. They're actually what most people envision for indexes and the reason why people say that lowering the FILL FACTOR can reduce/prevent fragmentation even though it doesn't work well or at all on most other types of indexes.
Since I REBUILD these at 1% fragmentation, I call these "Low Threshold Rebuilds".
- There are a whole lot of indexes that suffer both logical fragmentation and low page density. This is usually from out of order inserts or out of order "Expansive" updates. The fix for those is to find out what the cause of the "Expansive" updates are and fix that problem. They're everywhere, though and it's not that easy (although I've built some tools to help) fix columns suffering from "Expansive" updates (Modified_By columns are a prime and constant culprit). They usually show up with a low page density and fairly high fragmentation (not usually as high as "Sequential Silos"). If such indexes get below a 70% page density, I'll rebuild them at 82%. The "2" in that is to remind me that I rebuilt the index only to recover space and still have something "2 do" to the index. If the index survives a couple of weeks without needing to be defragmented or recover disk space and I still don't have the time to find out why it fragments and try to fix it, I may set it to 92% or just leave it at 82%. Again, I never mix these up with "Sequential Silos".These 82/92 indexes, which are a good percentage of your indexes, are the ones that will cause major pages splits and a shedload of blocking. They must NEVER be rebuilt or reorganized at 0 or 100%.Most of these indexes fall into a category that I call "Random Silos" and can be caused by out-of-order inserts and "ExpAnsive" updates. Deletes also come into play here as well as the 97% Fill Factor category of indexes.
- On the subject of REORGANIZE... I never use it because it doesn't work like most people think it does and it's not the tame little kitty that the documentation makes it out to be. It's actually a resource hog, takes a whole lot longer to execute, and it's a log file exploder. So are ONLINE rebuilds and neither do as good a job at resolving fragmentation as a REBUILD, which are MUCH quicker. The only time to use REORGANIZE is to recover IN-ROW LOB space and I tend to force all LOBs out of row with a table option for doing so. MS killed us when the defaulted the new MAX and XML datatype to in-row instead of (out-of-row) like the old TEXT, NTEXT, and IMAGE datatypes were prior to 2005.
stevec883 wrote:Another thing you mentioned and I'm curious what your take is; if you have a lower fill factor, say 70 percent like in your example, and that would yeild 42% wasted space. Wouldn't the open space be filled if it's a table with many inserts or updates (that happen to increase data in the middle)? There would be less page splits (so less fragmentation maybe?) and it could even be a great guess (after a lot of experimentation) to set them so the empty space gets utilized. So I'm wondering why you call it "wasted", couldn't it go to the right use under the right circumstances of course.
Again, "It Depends". It the graphic I posted, the index has a 70% Fill Factor and you can see the nice long Blue line of pages at the 70% page density level. You can also surmise by looking at the chart that it's an "Ever-Increasing" index that also suffers from "ExpAnsive" updates shortly after being inserted, which results in the ~50% page density of the pages further on the right.
So, based on that, you should also be able to surmise that the earlier pages in the index, which includes all those currently at 70%, will NEVER be updated and NEVER need room to grow because they're never modified and there are NEVER any out of order inserts. All the pages you see at the 70% line are stuck at 70% FOREVER. Following the numbered rules I outline above, this index should be rebuilt at 97% (which is the marker for "Ever-Increasing" and the recent inserts also have "ExpAnsive" updates) until you get around to somehow fixing the expansive updates... Then you could reclassify it as a 99% ("Ever-Increasing with NO "ExpAnsive" updates).
stevec883 wrote:And I was wondering what you thought on fragmentation; There can be just physical fragmentation on the drive that needs to be defragged, and this should help performance(?) When I am thinking in terms of how a table is used, I'm thinking of that in the rhealm of logical fragmentation. So I'm think that running a defrag (without changeing the fill factor) would be a good thing on its own.
First of all, NEVER defrag an index with a 0 FILL FACTOR. Leave them alone unless you're going to change the FILL FACTOR according to the numbered rules I posted. Otherwise, you'll end up like I did... sucking my thumb and frantically twiddling my hair wondering where the hell all the blocking came from on the morning after index maintenance.
I would also never defrag an index that has a FILL FACTOR that ends in "5" or "0" regardless of the first digit because that means that someone (they always use "0" or "5" as the second digit) made the same (and sorry but) bad assumption that you just stated. That's another reason why my seemingly crazy number system has no (except for 100% static indexes) FILL FACTORs that end with "0" or "5".
As for fragmentation on the disk itself, I've tried and failed to convince any and all SAN administrators that it SOMETIMES makes a difference on spinning rust of all forms. In a lot of cases (actually, most cases), I believe (haven't had the privilege to test it) it will make very little difference because there are so many other people hitting the disk that the read heads are going to be jumping all over the place anyway. The one place where it might make a difference is on SANs that have large contiguous data workloads and very, very few concurrent users, like one or 2.
On SSDs, similar fragmentation simply isn't going to make a difference no matter what. Adding to that, they're supposedly better at using random data than sequential data but I've not tested that either.
stevec883 wrote:You had mentioned a defrag venture cause blocking the next day, how did this happen?
That happened from me rebuilding indexes that had a "0" Fill Factor, which means I didn't know a thing about them. I was just like 99% of the rest of the world. When you rebuild an index that fragments a lot to 100% (which is what a Fill Factor of "0" really is), you slam everything into the proverbial ceiling with no "head room". If you do an out of order INSERT or an "ExpAnsive" update (even just 1 additional byte can do it), the pages are virtually guaranteed to split, which puts a system transaction across at least 3 pages... the target page, the next logical page, and the new page for the split. All of that and the reassignment of previous and next page pointers in the headers of all 3 pages and all of the data movement of moving roughly half the rows to the new page, plus the insert or update, are all fully logged regardless of recovery model and there are frequently more than 1 log entry per for moved. While all that is happening, all 3 of the pages are locked and blocked.
If you do that to about half of all the indexes in your database during index maintenance, then all those page splits on all those indexes happen on your most critical tables/indexes the very next day and that causes MASSIVE blocking.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
p.s. To be sure, my intention is to make all of that "auto-magic" for Row-Store indexes. I'm about 80% complete on that... as you know, the last 10-20% of something always takes longer than the rest.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Very useful information --- I will keep that in mind, to not degrag an index that has the server default (of O% fill factor). I also like your % numbers used as a naming convention to mark the index.
In your comment about the fill factor, "All the pages you see at the 70% line are stuck at 70% FOREVER." I
If I change this fill factor to 100% and rebuild the index, wouldn't the rebuild increase the page density? (In other words, fill factor of 70%, therefore 30% empty space on pages in anticipation of inserts, then inserts are done forever for that table and it becomes only reads, so increase fill factor to 100% so the empty space would then be utilized, pages filled, and density to near 100)?
- stevec883 wrote:
In your comment about the fill factor, "All the pages you see at the 70% line are stuck at 70% FOREVER." I
If I change this fill factor to 100% and rebuild the index, wouldn't the rebuild increase the page density? (In other words, fill factor of 70%, therefore 30% empty space on pages in anticipation of inserts, then inserts are done forever for that table and it becomes only reads, so increase fill factor to 100% so the empty space would then be utilized, pages filled, and density to near 100)?
Yes... and that's my point. So many people think that by simply reducing the Fill Factor, they will somehow make fragmentation less. Most of the time, that presumption (which some people have fallen into the trap of labeling it as a "Best Practice") is absolutely wrong because it doesn't do a thing to prevent any fragmentation and, worse, it's wasting a shedload of memory and disk space.
p.s. The index I portrayed in the graphic fits the 97% scenario, which is the Fill Factor I assign to "Ever-Increasing keyed indexes that suffer ExpAnsive Updates shortly after any new rows are inserted". It usually comes out to more than 97% because of the "overlap" of some rows and is totally worth it when it comes to easily and effectively identifying such indexes.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
If page size is less than 1000 then no use when rebuild the index.
Will get long duration if run fragmentation script for all tables instead of single problematic table.
Below script will use to get single table or multiple tables or all tables DB fragmentation details .
**********single table index fragmentation********
Use DB_name,
GO
SELECT DB_Name(DB_ID()) as DBName, dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID('DB_Name'),OBJECT_ID('Table_Name'), NULL, NULL, NULL) AS indexstats -- Mention DB_Name and Table_Name
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID()
and indexstats.page_count > 1000
and dbtables.[name] in ('Table_name')--Table Names
and dbindexes.[name] is NOT NULL
ORDER BY indexstats.avg_fragmentation_in_percent desc
***************
Use DB_name,
GO
SELECT a.object_id, object_name(a.object_id) AS TableName,
a.index_id, name AS IndedxName, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID('DB_Name),OBJECT_ID('Table_Name'), , NULL , NULL , NULL) AS a -- Mention DB_Name and Table_Name
INNER JOIN sys.indexes AS b
ON a.object_id = b.object_id
AND a.index_id = b.index_id;
*******************All tables fragmentation details in Single DB********
Use DB_name,
GO
SELECT DB_Name(DB_ID()) as DBName,dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID() and indexstats.page_count>1000
and dbindexes.[name] is NOT NULL
ORDER BY indexstats.avg_fragmentation_in_percent desc
**********Two or more tables fragmentation details*****
Use DB_name,
GO
SELECT DB_Name(DB_ID()) as DBName, dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID() and indexstats.page_count>1000
AND dbtables.[name] in ('Table1','table2',-----,'tablen')-- Mention the list of tables
ORDER BY indexstats.avg_fragmentation_in_percent desc
-
If page size is less than 1000 then no use when rebuild the index.
Will get long duration if run fragmentation script for all tables instead of single problematic table.
Below script will use to get single table or multiple tables or all tables DB fragmentation details .
**********single table index fragmentation********
Use DB_name,
GO
SELECT DB_Name(DB_ID()) as DBName, dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID('DB_Name'),OBJECT_ID('Table_Name'), NULL, NULL, NULL) AS indexstats -- Mention DB_Name and Table_Name
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID()
and indexstats.page_count > 1000
and dbtables.[name] in ('Table_name')--Table Names
and dbindexes.[name] is NOT NULL
ORDER BY indexstats.avg_fragmentation_in_percent desc
***************
Use DB_name,
GO
SELECT a.object_id, object_name(a.object_id) AS TableName,
a.index_id, name AS IndedxName, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (DB_ID('DB_Name),OBJECT_ID('Table_Name'), , NULL , NULL , NULL) AS a -- Mention DB_Name and Table_Name
INNER JOIN sys.indexes AS b
ON a.object_id = b.object_id
AND a.index_id = b.index_id;
*******************All tables fragmentation details in Single DB********
Use DB_name,
GO
SELECT DB_Name(DB_ID()) as DBName,dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID() and indexstats.page_count>1000
and dbindexes.[name] is NOT NULL
ORDER BY indexstats.avg_fragmentation_in_percent desc
**********Two or more tables fragmentation details*****
Use DB_name,
GO
SELECT DB_Name(DB_ID()) as DBName, dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID() and indexstats.page_count>1000
AND dbtables.[name] in ('Table1','table2',-----,'tablen')-- Mention the list of tables
ORDER BY indexstats.avg_fragmentation_in_percent desc
- Srinivas Merugu wrote:
Below script will use to get single table or multiple tables or all tables DB fragmentation details .
Hello and welcome aboard! I appreciate anyone that steps up to the proverbial plate and tries to help or share knowledge.
On the subject of your scripts, logical fragmentation forms an incomplete picture by itself especially since many have proven that logical fragmentation means less that statistics the need to be updated in most cases.
With that, I recommend returning the page type, the page density (avg_page_space_used_in_percent), the avg_fragment_size_in_pages, info about the "record" sizes, the number of modifications made in statistics, and maybe even some "usage" information.
There's also partition information and a wealth of other things to help make the decision of "Do I really need to rebuild, reorg (almost never and can easily perpetuate fragmentation), or just rebuild stats (the norm and doesn't need to always be FULL).
A lot of people consider Ola Hallengren's scripts to be the "gold standard" for such things. I just wouldn't use them for the traditional but incorrect 5/30 "standard" for doing index maintenance. Here's the link to Ola's scripts...
https://ola.hallengren.com/sql-server-index-and-statistics-maintenance.html
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 1 through 15 (of 19 total)
You must be logged in to reply to this topic. Login to reply