Importing a CSV into SQL Server Shouldn't Be This Hard
- ZZartin wrote:
At least when you're dealing with XML or JSON the average end users is too intimidated by the format(and usually lacks the tools anyways) to directly mess and generate the files.... which usually forces some kind of automation into things. Excel let's anyone think they can create csv and it'll work just as well for any tool as it does in excel.
That, good Sir, is why I tell people not to try to do the CSV thing. It's much easier to read from the spreadsheet using the ACE drivers. I actually have code the will look at a sheet and figure out out to import it even if there are multiple columns with the same names (like temporal reports that are horizontal by month with repeating column names for each month) and it was all done in T-SQL.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
As long as people are sharing their CSV secrets. Warning disclosure this contains C# code. A couple of years ago I worked on a project for a fitness tracking system which allows users to upload a CSV file with their workout history (from another system). The CSV files always have quotation issues and blank spaces are inconsistently populated in one of columns. Also, nothing prevents the file from being manually manipulated (screwed up) by the user prior to uploading. How to consistently read these CSV files and actually fix them when there are issues so SQL doesn't choke on the data when it gets there?
In .NET the library used most is CSVHelper. There's an official CSV definition and the author makes sure the library is standard compliant. This includes logic about column offsets based on class maps. Currently it's at version 27, there are over 1,000 commits to the repo, and there are more than 55 million Nuget.org package builds. I'm not affiliated in any way I just use it and it's been very reliable.
CSVHelper has an "auto detect" mode but if your file is definitely messed up it lets you register class maps. Class maps let you programmatically address each column by index offset however needed. CSVHelper's preferred object format to read/write files to/from is IENumerable<T> where T is a type. Here it's using List<t> which gets read into memory all at once. This could probably be further optimized.
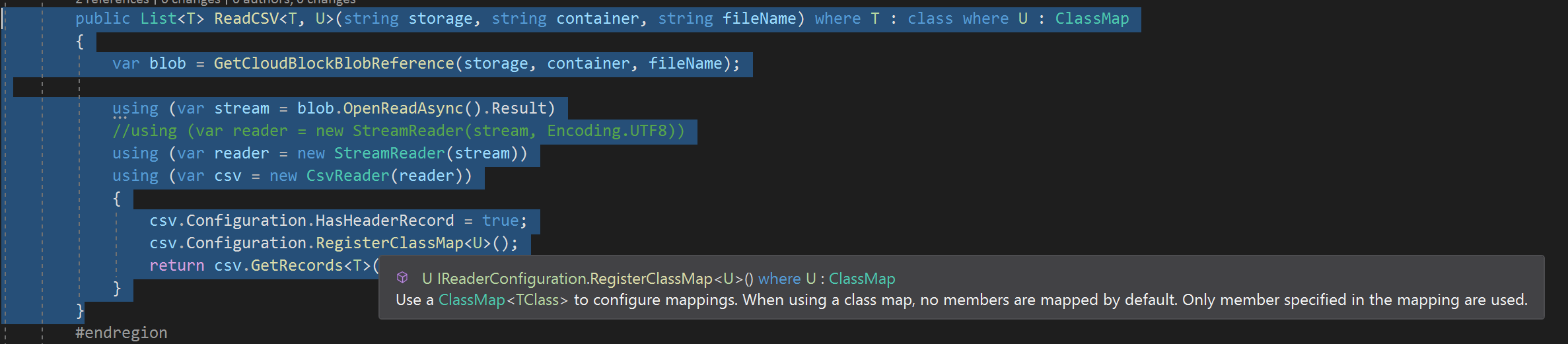
public List<T> ReadCSV<T, U>(string storage, string container, string fileName) where T : class where U : ClassMap
{
var blob = GetCloudBlockBlobReference(storage, container, fileName);
using (var stream = blob.OpenReadAsync().Result)
using (var reader = new StreamReader(stream))
using (var csv = new CsvReader(reader))
{
csv.Configuration.HasHeaderRecord = true;
csv.Configuration.RegisterClassMap<U>();
return csv.GetRecords<T>().ToList();
}
}The second to last line registers the class map. If the cursor is hovered over the RegisterClassMap<U>() method

The expected file is defined by a POCO class with a bunch of string Properties.
public class WorkoutFile
{
public string ClassDate { get; set; }
public string Workout { get; set; }
public string Result { get; set; }
public string Prescribed { get; set; }
public string Pukie { get; set; }
public string Work { get; set; }
public string WorkTime { get; set; }
public string FormattedResult { get; set; }
public string Notes { get; set; }
public string WorkoutDescription { get; set; }
}The ClassMap must inherit from CSVHelper's ClassMap<T> class and the columns are then accessible by index offset.
public sealed class WorkoutFileMap : ClassMap<WorkoutFile>
{
public WorkoutFileMap()
{
Map(m => m.ClassDate).Index(0);
Map(m => m.Workout).Index(1);
Map(m => m.Result).Index(2);
Map(m => m.Prescribed).Index(3);
Map(m => m.Pukie).Index(4);
Map(m => m.Work).Index(5);
Map(m => m.WorkTime).Index(6).Default(String.Empty);
Map(m => m.FormattedResult).Index(7);
Map(m => m.Notes).Index(8);
Map(m => m.WorkoutDescription).Index(9);
}
}It's possible in the class map to write whatever custom "input buffer" code is required. In theory you could start with anything no matter how bad and make it work in the end. To fix the jagged column issue the above uses a built-in method to add a default empty string to the 6th offset column (which is mapped to WorkTime Property). There are many other helpful methods or you you can make your own.
Once a class map has been defined and the file has been read into a List<T> another CSVHelper method 'WriteRecords' writes out the file.
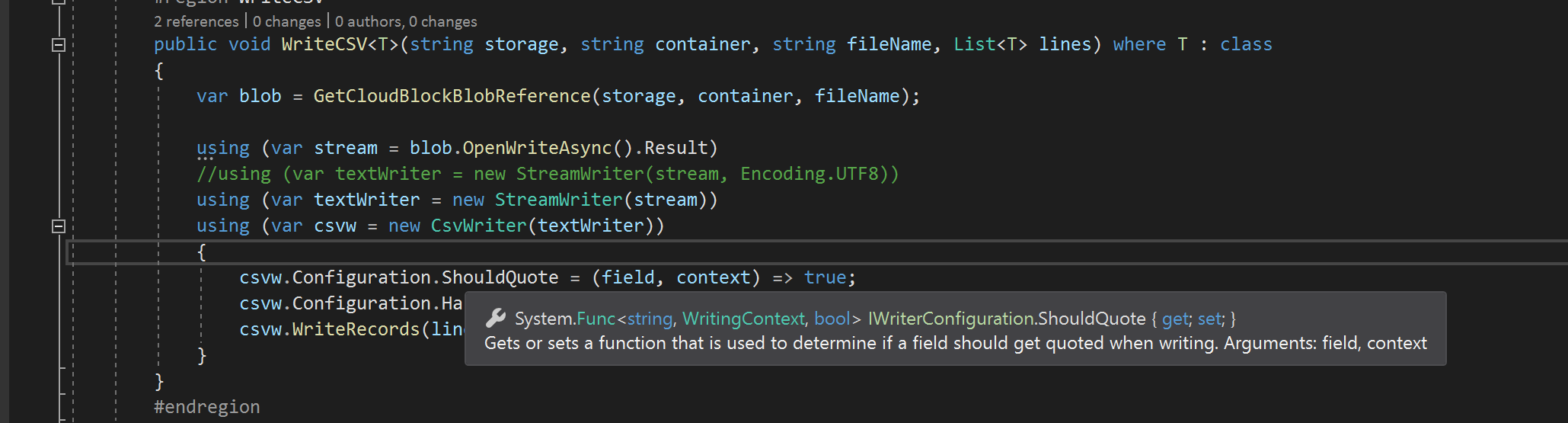
public void WriteCSV<T>(string storage, string container, string fileName, List<T> lines) where T : class
{
var blob = GetCloudBlockBlobReference(storage, container, fileName);
using (var stream = blob.OpenWriteAsync().Result)
using (var textWriter = new StreamWriter(stream))
using (var csvw = new CsvWriter(textWriter))
{
csvw.Configuration.ShouldQuote = (field, context) => true;
csvw.Configuration.HasHeaderRecord = true;
csvw.WriteRecords(lines);
}
}The 3rd to last line is the magical line that 100% FIXES EVERYTHING. If the cursor is hovered over the ShouldQuote method
"Gets or sets a function that is used to determine if a field should get quoted when writing." Afaik that means to make the columns always include the quotation delimiters. We've never had any issue ever with any file after it's been "should quoted" by CSVHelper. This feature used to be documented (I couldn't find any longer when I looked) but then years ago there was an update and the method was renamed (to what it is now, I forget what it was). The only explanation and references found now are in Github QA or Stack Overflow (which is sometimes a useful site). SQL Server reads the "should quoted" data from blob storage each time without any issue.
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
Viewing 2 posts - 61 through 62 (of 62 total)
You must be logged in to reply to this topic. Login to reply