How to remove quote marks using SSIS and a little C#
-
Comments posted to this topic are about the item How to remove quote marks using SSIS and a little C#
-
interesting and a good example for SSIS - but does not catch all cases, neither addresses the real issue that is that the file was badly created and is therefore not a CSV file
how will your regex deal with
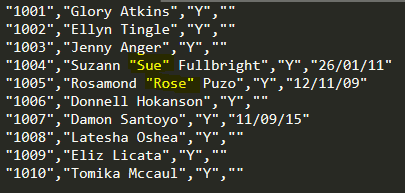
"1005","Rosamond "Rose"" Puzo","Y","12/11/09"
"1005","Rosamond ,"Rose" Puzo","Y","12/11/09"
In many cases, but again not all, searching for "," is a better bet to replace this by another delimiter - and replacing the first and last quote.
sample - new delimiter should be a combination that would normally not be used
- do not use double quote as text delimiter on SSIS
- replace "," by ^#^
- remove first and last "
- split by ^#^
-
I like articles like this one from which I can learn new, niche tips and tricks... especially where regular expressions are involved, because I'm not that good at them!
I question the solution, though. The name in the source was Suzann "Sue" Fullbright, yet after transforming the data we end up inserting Suzann 'Sue' Fullbright, which is not the same thing. It's close, but not the same. If you don't have the option of changing the delimiter in the source file, then this may be an acceptable alternative, depending upon the requirements.
Nice job.
-
I haven't analyzed your RegEx, but isn't there *inherent* ambiguity in certain situations that are impossible to definitively resolve?
What if the text of a field's data contains quote-comma-qoute, like this:
"1005","Rosamond "," Puzo","Y","12/11/09"
The *sending* system (the process that generates the comma-delimted file) is supposed to definitively handle every situation by replacing all embedded " with "" (ie: replace all embedded CHR(34) with CHR(34)CHR(34)), and the receiving system can definitively resolve all of those back.
BUT if we are trying to deal with files that were *not* created correctly (eg: where embedded CHR(34) were *not* replaced with CHR(34)CHR(34), then all bets are off!! There's all kinds of bad character-combinations that could cause problems that lead to irreconcilable ambiguities In the example I gave, how is it possible for *any* parsing process, or anything that is trying to 'fix' this to decide whether to join the "Rosamond" and "Puzo" parts together or the "Puzo" and the "Y" parts (or any other pair out of the *5* contiguous 'fields')?
-
Fine for small files, but -
Reading the entire file into memory as a single string will not scale.
You could use stream readers/writers but it also seems silly to be reading and writing the file, then reading it again in the Data Flow.
It might be worth using the Script Component as Source. You can read the file once, line by line, passing each line to the buffer as you go.
I would also use a variable or a connection to manage the file path, and pass it into your script component (or task).
A similar thread with some sample code - https://social.msdn.microsoft.com/Forums/en-US/b4e958e5-2f68-4574-9038-b98e7879b91b/script-source-component-reading-a-flat-file-and-manipulating-each-row?forum=sqlintegrationservices
Docs on script source - https://docs.microsoft.com/en-us/sql/integration-services/extending-packages-scripting-data-flow-script-component-types/creating-a-source-with-the-script-component?view=sql-server-ver15
-
Do like this neat example of fixing file strings pre load.
Comes into its own when you have none (or limited) control over the Source data.
Good work well written!
-
If you were running this package as a SQL Server Agent scheduled task, what account does the script task actually run under? I have a similar job set up to parse a single-line into multiple rows and despite running the job on a schedule where the "run as" impersonates me and I have full control to the file system path the job doesn't work as designed. If I run it interactively, it works perfectly.
- SparTodd wrote:
If you were running this package as a SQL Server Agent scheduled task, what account does the script task actually run under? I have a similar job set up to parse a single-line into multiple rows and despite running the job on a schedule where the "run as" impersonates me and I have full control to the file system path the job doesn't work as designed. If I run it interactively, it works perfectly.
The SQL Agent service account. You can check the All Executions report & look for the value of 'Caller' to check this.
- Darren Green-187877 wrote:
Fine for small files, but -
Reading the entire file into memory as a single string will not scale.
... Script Component as Source. You can read the file once, line by line, passing each line to the buffer as you go.
+1 - this method scales better, does not require modification of the source file & requires only one pass of the source data.
-
Expanding on my prior post... (Sorry this is so long. I know that a lot of people already know these details, but I think some people don't)
Programs that 'export' data into a delimited file need to deal with the fact that field-data itself might contain the field-delimiter character, and do it in such a way that a downstream 'import' process can **un-ambiguously** parse out all fields in each record correctly.
For CSV (Comma-Separated-Value) files, the delimiter is the comma character, and the way to deal with field-data that *contains* a comma, is to surround the field-data with quotes [chr(34)]. The 'import' process regards all commas found *within* quotes as part of the current-field-data, and not as a delimiter to start a new field.
But now you also have to deal with the fact that the field-data itself might *contain* one-or-more quotes [chr(34)]. You don't want the 'import' process to regard those embedded quotes as a signal to terminate the current field-data, but rather pull-in those quotes as part-of the field data. The way this is done is for the 'export' process to replace *every* chr(34) found in each field with chr(34)chr(34) (ie: two contiguous quotes). and for the 'import' process to regard pairs of consecutive chr(34) as *data* to pull into the field, and not terminate the field-data until a solitary chr(34) is found.
Properly designed CSV 'export' and 'import' processes are desgined to do all of the above, and there is *never* any ambiguity and everything works. Perfectly. All the time.
While you might be using a properly designed 'import' program, you sometimes have to deal with files that were not created by a properly designed 'export' program. Some programmers write their own 'export' programs and fail to deal with these issues in the correct way. Their algorithm might do something unsophisticated like this: For each field: just put chr(34) on both ends of the source field-data (verbatim), and then just separate each field with a comma.
So, a source-record that looks like this:
SOURCE: [Name: Kenneth Smith] [Address: 555 Main St] [City: Austin]
Becomes:
CSV: "Kenneth Smith","555 Main St", "Austin"
So far, so good, no ambiguities or problems there.
But if the source record looks like this (notice the embedded quotes in the Name and the embedded comma in the Address):
SOURCE: [Name: Kenneth "Kenny" Smith] [Address: 555 Main St, Apt 3C] [City: Austin]
A *properly* formatted CSV record should be:
GOOD CSV: "Kenneth ""Kenny"" Smith","555 Main St, Apt 3C","Austin"
And the 'import' program unambiguously 'knows' that each pair of quotes surrounding Kenny are part of the data, and that they do not signal the end of the field, and it also knows that the solitary quote after Smith unambiguously signals the end of the field. The paired-quotes [chr(34)chr(34)] are restored back to back to just [chr(34)] on the receiving end, and all is good.
But a poorly-written export process might produce this (field data inserted *verbatim* between the quotes):
BAD CSV: "Kenneth "Kenny" Smith","555 Main St, Apt 3C","Austin"
The import program sees the solitary quote just before Kenny and assumes that's the end of the field data, but then the next character is not the expected field delimiter (comma) and therefore an error occurs. Well, you might say that the *import* program should simply regard any single-quote that is *not-immediately-followed-by* a comma as part of the field data and move on. YES THAT WOULD WORK IN THIS EXAMPLE.
*BUT* what if the source field data *does* have a quote followed by a comma in it? Or worse yet, a quote-comma-quote in it?
SOURCE: [Name: Kenneth "," Smith] [Address: 555 Main St, Apt 3C] [City: Austin]
GOOD CSV: "Kenneth "","" Smith","555 Main St, Apt 3C","Austin"
BAD CSV: "Kenneth "," Smith","555 Main St, Apt 3C","Austin"
In this BAD CSV case, it is utterly impossible for an general-use CSV 'import' process (or any general-use pre-processor, for that matter) to reliably reconstruct the source record properly because every place you see quote-comma-quote in this example it is (to the importer) unambiguously a signal end the field and start a new field.
With the GOOD CSV, the import process can unambiguously handle everything perfectly. It sees the contiguous pairs of quotes as part of the field-data and not as field terminators, and those pairs [chr(34)chr(34)] get restored back to [chr(34)] on the receiving end. All is good.
-
Hey man, really saved my butt with this post! I shamelessly copy pasted your code snippet and noticed one little typo that I will outline below. Basically some of the filepaths had the @ token inside of quotes, which prevents system.io from recognizing them as filepaths. You will notice this because all the \s will be red-squigglied.
var fileContent = File.ReadAllLines("@C:\Users\John Smith\Desktop\Import.txt");
should be
var fileContent = File.ReadAllLines(@"C:\Users\John Smith\Desktop\Import.txt");
and
File.WriteAllLines("@C:\Users\John Smith\Import.txt", fileContentUpdated);
should be
File.WriteAllLines(@"C:\Users\John Smith\Import.txt", fileContentUpdated);
resulting in
var fileContent = File.ReadAllLines(@"C:\Users\John Smith\Desktop\Import.txt");
var fileContentUpdated = fileContent.Select(
x => new Regex(@"(?<!^)(?<!\,)""(?!\,)(?!$)").Replace(x, "'")).ToArray();
File.WriteAllLines(@:C:\Users\John Smith\Import.txt", fileContentUpdated);
Thanks again!
-
Gosh, folks... if we look at the example from the article...

There's no need for all the special handling if you make the realization that the delimiter is actually "," (with the quotes). Yes, you still need to deliberately get rid of the first character in the first column and the last character in the last column (because they're quotes) but that's not something that needs Regex or a trip to C#. And, if you have SQL Server 2017 or up, the TRIM function will take care of those quite nicely and quite quickly.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Yes, you still need to deliberately get rid of the first character in the first column and the last character in the last column (because they're quotes) but that's not something that needs Regex or a trip to C#.
If the leading and trailing quotes are guaranteed then you can do it in the format file no need for trim.
Far away is close at hand in the images of elsewhere.
Anon. - David Burrows wrote:Jeff Moden wrote:
Yes, you still need to deliberately get rid of the first character in the first column and the last character in the last column (because they're quotes) but that's not something that needs Regex or a trip to C#.
If the leading and trailing quotes are guaranteed then you can do it in the format file no need for trim.
Totally agreed and absolutely necessary prior to 2017.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Of course, even without the "CSV" file type available in BULK INSERT as of 2017, it's pretty simple to make a BCP format file that will handle all of this during the import.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 15 posts - 1 through 15 (of 15 total)
You must be logged in to reply to this topic. Login to reply