How to find unique values in a table
-
Hello trying to find unique values on the following table
First temporary table query (Master Data)
insert into #tempCOO
select sk.CountryOfOrigin,im.partnumber,sk.Quantity,sol.id,lp.id,lpl.id,so.id,p.SerialNumber
FROM sk
join lpl on sk.LoadPlanLineId = lpl.id
join lp on lp.id = lpl.LoadPlanId
join sol(nolock) on sol.id=lpl.SalesOrderLineId
join so on so.id=sol.SalesOrderId
join im on im.id = sol.itemmasterid
join pd on pd.content = sk.batchnumber and Pd.PackageAttributeId=37
join p on p.id=pd.PackageId
where lp.Loadnumber= 'L001' order by p.SerialNumber desc
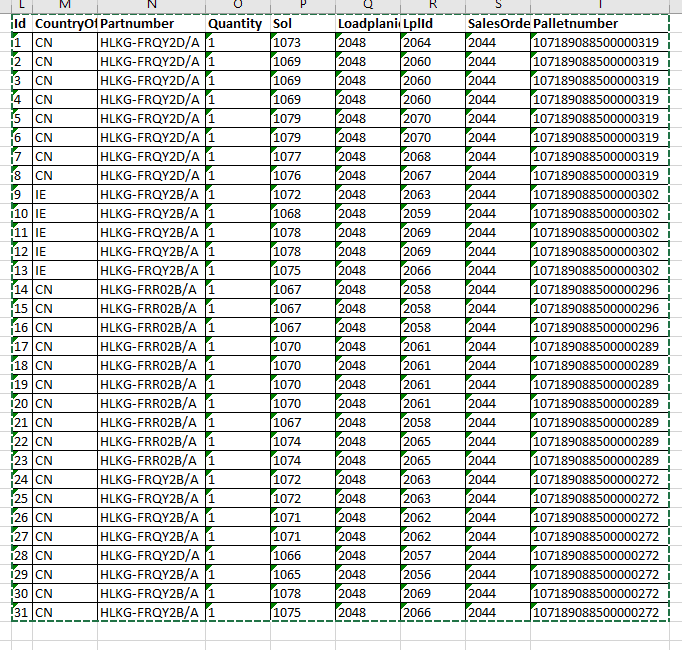
The result is the following:

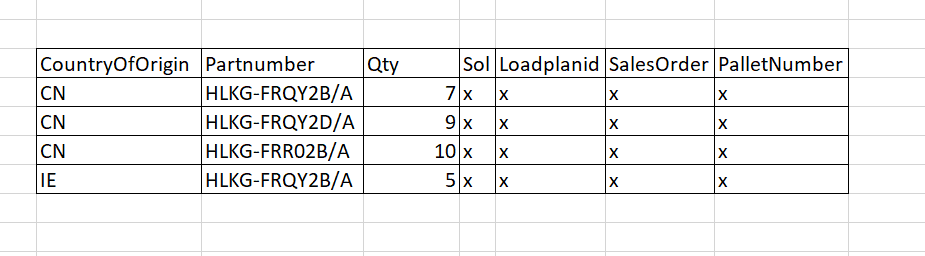
I need to find unique values for a combination of country of Origin and Part Number
These are the values I expect
Could you help me to write the querys I need?
Thanks so much
-
Basic totals query. Give it a try. Not like you can break anything.
Not sure who told you to put NO LOCK in all your queries, but don't unless you like risking getting inaccurate query results.
-
To add to what pietlinden said, I think that a DISTINCT and a SUM are going to be your friend in this query.
This is also just my preference, but I generally don't like capturing data that I am going to throw away. If the last 4 columns are useless in your final result, I would scrap them in your initial data pull. You MAY still need the joins (for filtering the data), but some of those may be able to be scrapped as well.
And a "personal preference" thing - I HATE "magic numbers". What I mean by magic numbers in your query is this:
Pd.PackageAttributeId=37
If a new developer comes in to look at this code, they have no idea what a package attribute id of "37" is or why it is relevant in this query. Now, if you had an INT variable named something like "@intBoxedItemID" and set that to 37, then in your query I know that a package attribute ID of 37 means it is a Boxed Item (or at least SHOULD mean boxed item) and debugging or changing your code becomes a LOT easier for the new developer. Or even for you when you have to support this code in 10 years.
And I agree 110% with pietlinden on the NO LOCK hint. Unless your table is named "sol(nolock)", I would avoid using NOLOCK. It is in my coding standards that NOLOCK should be avoided except where potential data inaccuracy is acceptable AND it must contain comments explaining which end user approved the data inaccuracy. Sure, it gets around blocking, but it does so by allowing rows to be read multiple times or rows to be missed completely. Locks are there for a reason. Also, 9/10 times I advise against query hints. USUALLY the optimizer is good about picking good query plans without your hints. The exception to this is if you KNOW you are going to hit a parameter sniffing problem in which case the OPTIMZE FOR hint is acceptable (and preferable by me over RECOMPILE). I don't see these in your code, just things I would watch for. I find that a lot of times when a query hint is added, it is added because the developer googled their problem and that was the first solution that came up. Sometimes the best solution (sometimes RECOMPILE or NOLOCK is the only option to solve your problem), sometimes a very bad solution. Instead of NOLOCK, you may benefit from adding some indexes so you can get your data faster for example.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
"The result is"
For you, but not for us! We don't have access to your tables nor do we know anything about them. We need actual usable data to test with, i.e., CREATE TABLE and INSERT statement(s), not just a picture of data. Not only that, your SELECT statement does not match the data shown.
We also need more details on specifically what result you want. You are summing up quantity, but you're still listing other detail columns, such as sol and Palletnumber. If you add up 7 rows, and some of them have different Palletnumber(s), which Palletnumber do you want to show in the final result? Min? Max? First? Last?
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Mr. Brian Gale wrote:
And I agree 110% with pietlinden on the NO LOCK hint. I would avoid using NOLOCK. It is in my coding standards that NOLOCK should be avoided except where potential data inaccuracy is acceptable AND it must contain comments explaining which end user approved the data inaccuracy. Sure, it gets around blocking, but it does so by allowing rows to be read multiple times or rows to be missed completely. Locks are there for a reason.
Most people seem to forget that you can get nonrepeatable reads (NRR) and phantom reads (PR) when using READ COMMITTED (RC), the default level, just like you get them with NOLOCK (RU(READ UNCOMMITTED)).
Yes, NOLOCK/RU does add in dirty reads -- rows in the process of being UPDATEd or INSERTed or DELETEd -- that RC does not. So, then, it really depends on what you're pulling from the joined table as to how dangerous NOLOCK is. In this case, the join seems to be solely to look up the name for an id. I'd use NOLOCK for that virtually every time, and I've been a DBA for 35 years (gak!) .
Yes, there is one bigger issue with NOLOCK: allocation scans. Very technical, but basically makes it much more likely to get NRR and PRs. Fortunately, there's an, again very technical, way to avoid that too.
In summary, you must be very careful about using NOLOCK, but don't go overboard against it like so many people seem to do. It does save overhead.
Obviously if you're running something very critical, then don't use it. Then again, for something like that, you should also seriously consider going beyond the normal RC level as well: look at SERIALIZABLE or SNAPSHOT if the reason you're reading the data is that vital.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Note, too, that the OP did not indiscriminately use NOLOCK everywhere.
In fact, it was used on only 1 table out of 9 (or so).
To me, that is exactly the way NOLOCK should be used:
selectively (get it) where it won't hurt functionality and will reduce overhead.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Scott - I agree that NOLOCK has its purposes, as do all query hints. Otherwise they wouldn't be in there to begin with. I was just trying to over-emphasize that in most cases, it is not needed and only causes more problems than it solves.
NOLOCK also has the problem of dirty reads (reads of uncommitted data). There are use cases for NOLOCK, just like there are use cases to put your database into RU isolation level as the default, or adding a RECOMPILE hint on a stored procedure. The trick is knowing WHEN to use it.
For most queries that I write and verify, I find that NOLOCK was put in place to correct a blocking issue. In one case it was put in to help a rare parallelism related blocking issue (self blocking) that resulted in a query that ran in about 1 minute but in a rare case ran for 2 hours. NOLOCK fixed the issue, but MAXDOP 1 hint would have solved that as well (or adjusting the cost threshold for parallelism) and was a "better" option.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - Mr. Brian Gale wrote:
Unless your table is named "sol(nolock)", I would avoid using NOLOCK. It is in my coding standards that NOLOCK should be avoided except where potential data inaccuracy is acceptable AND it must contain comments explaining which end user approved the data inaccuracy.
...
Scott - I agree that NOLOCK has its purposes, as do all query hints. Otherwise they wouldn't be in there to begin with. I was just trying to over-emphasize that in most cases, it is not needed and only causes more problems than it solves.
NOLOCK also has the problem of dirty reads (reads of uncommitted data). There are use cases for NOLOCK, just like there are use cases to put your database into RU isolation level as the default, or adding a RECOMPILE hint on a stored procedure. The trick is knowing WHEN to use it.
For most queries that I write and verify, I find that NOLOCK was put in place to correct a blocking issue. In one case it was put in to help a rare parallelism related blocking issue (self blocking) that resulted in a query that ran in about 1 minute but in a rare case ran for 2 hours. NOLOCK fixed the issue, but MAXDOP 1 hint would have solved that as well (or adjusting the cost threshold for parallelism) and was a "better" option.
And that's where I disagree. I don't think NOLOCK restrictions should be that tight. *No*, NOLOCK should not be used automatically or too indiscriminately. But most businesses generally won't generally suffer any great harm from using NOLOCK relatively aggressively. I'll point out, too, that we edit the bejeebers of out of data before we add/modify it in prod, so rollbacks for us are very rare, which of course reduces potential issues with phantom reads and dirty data.
Specifically, to me, NOLOCK should generally be available for:
(1) lookup of name/description for a given id
(2) verifying country / state/province / postal code (zip code is more U.S only, postal code is more global) / and other generally very static data
(3) historic data that you know is not changing at all now
(4) most other generally static data, esp. if a covering index is available
Of course you have to use common sense and business sense here.
Let's take a specific example: currency exchange rates. For dates/times in the past, those don't change. Once you get rates from whatever source you get those rates from, they're fixed. So I say, yeah, use NOLOCK to read those. Especially, say, if you were running financials for year 2020. No way those rates are anything but static now.
Finally, suppose you're looking up/reporting on employee hours/schedule. Those can vary quite a bit, sometimes on short notice, and you never want to give an employee a wrong work schedule. Thus, avoid NOLOCK like the plague for that and get only committed data.
It also helps if you just commit to a cursor threshold setting, which eliminates the possibility of an allocation scan even for NOLOCK (at least last time I checked this still worked). The knowledge about that setting and its effects came from Paul White.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
You make some good points Scott. I think my approach had been that NOLOCK, like CURSORS, should be avoided except where absolutely necessary. It was what I had read in many places online (both on this forum and elsewhere), and had heard in multiple webinars/conferences, so I thought if the experts said to avoid it and I am by no means an "expert" when I see how much others know of SQL Server, they must be right. On a side note - I remember the first time I heard about windowing functions and it blew my mind! Brought that back to the team and at that time (1 DBA (me), 4 developers, 1 BA), nobody had heard of windowing functions. It made all of our code so much more efficient. Then I heard about CTE's and recursive CTE's and brought that back to the team and our BA loved them. Nobody else really used them for our stuff, but was good to know they existed.
Learning of uses for NOLOCK is actually good for me! I like learning new things and after reading for years about how NOLOCK is evil, I just took it to be truth. But the more I think about it, the more I realize that if it was to be avoided 100%, then Microsoft would have removed it from SQL Server (or at least disabled it because if they disabled that hint, old code would still run, just the hint would not do anything).
Where I work, we have the system busy, but not THAT busy, so NOLOCK is rarely the right solution to our problems when we hit performance issues. USUALLY if we hit a performance issue, an index or rewriting the query is a better solution than NOLOCK. NOLOCK is our "band-aid" fix so people stop complaining while we work on the real issue.
I also gave the example with RECOMPILE above and while I prefer to avoid it. There are cases where it fixes the problem you are having, but again, at my workplace, this is more of a "band-aid" fix than a proper fix. OPTIMIZE FOR UNKNOWN is a better option in most cases and optimizing for a specific value is in general a better solution than UNKNOWN. Alternately, adding an index can help with this too.
You gave me something to think about with this. I am going to revisit my coding standards. I know I changed some stuff when the previous primary DBA left. One big one I changed was they had "don't use CHAR, use VARCHAR". I changed that to "use appropriate data types and try to use the smallest required data type (ie INT vs BIGINT)".
I am now running through my head of other things I advise to avoid and am thinking about which ones are "should be avoided" and which ones are "use only where appropriate". Should be avoided ones I am still thinking Cursors are in that bucket. They have a purpose and a use, but overall I find them to be abused and used when not needed (looping for no good reason). NOLOCK, for all of the use cases I have at my workplace, seems like more of a "magic button" fix than a proper fix, same thing with RECOMPILE. Our blocking is generally short and I generally recommend it for the tables we see the blocking happening on. But I am going to change our coding documentation (for SQL) so that NOLOCK is allowed without needing to comment things and get approvals, but that the developer needs to be aware of the risks of using it and that the code reviewer may question that decision.
Another one I usually recommend against using is sp_msforeachdb or sp_msforeachtable, but that is because I've read stories where it skips some db's or tables. Thankfully, writing your own version of that is fairly easy to do and from my experience is reliable. And is one of the use cases for a cursor where I don't complain if I see a cursor.
On a completely unrelated note - one of the BIGGEST pet peeves of mine is single character variables and aliases. That was another big thing I added to our coding standards. Variables and aliases must be descriptive enough that I don't need to scroll through the code to determine what the alias or variable is to be used for. Poorly named objects are also a no-go in my system with the exception of objects named from 3rd party tools. If part of the ETL process is to copy a table from a 3rd party tool to the data mart, the table name should be prefixed with the system/tool it came from followed by the original table name. But I am starting to get really far off topic, so I will stop this post.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. - Mr. Brian Gale wrote:
but MAXDOP 1 hint would have solved that as well (or adjusting the cost threshold for parallelism) and was a "better" option.
These are always over looked in favour of RU in my experience
-----------------------------------------------------------------------------------------------------------
"Ya can't make an omelette without breaking just a few eggs" 😉
- Mr. Brian Gale wrote:
Scott - I agree that NOLOCK has its purposes, as do all query hints. Otherwise they wouldn't be in there to begin with. I was just trying to over-emphasize that in most cases, it is not needed and only causes more problems than it solves.
They used NOLOCK on 1 table out of 8 and to look up a description for a code only.
That seems like a perfect use of NOLOCK to me. Yet you still objected.
Just be honest and openly state that you oppose any use of NOLOCK. If one can't use it in this very limited way, then when would you ever allow its use??
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Scott - I am not sure if you saw my most recent reply where I basically retracted my previous statements on NOLOCK. It was a bit of a ramble and rant, but I am agreeing that I need to re-think and re-do my coding standards.
Previously I had read only hate and horror stories of using NOLOCK and how it would fix one problem only to cause more in the future. Hence, I had a "don't use NOLOCK" policy and whenever I see it in someones code (on here or at my workplace), I would call it out to make sure that the end user actually NEEDED NOLOCK.
I still feel the use cases for it are limited; as are MOST query hints. Majority of the time, if statistics are up to date and indexes are built well, the query optimizer is going to pick the proper plan along with appropriate locks. On top of that, I've seen cases where hints are ignored. Mind you these are usually because the hint makes no sense (like NOLOCK on an UPDATE statement).
I will be honest and openly state that I am not a fan of NOLOCK and I will continue to question its use in all queries that I am looking at. I refrain from using NOLOCK (and most other query hints) as much as I possibly can. That being said, I also try to avoid using undocumented features such as quirky updates or sp_msforeachdb and when I see those in code, I call them into question as well. Even cursors, I try to avoid unless it is the only option. Part of my code verification process that I do at my workplace is to evaluate and discuss if a cursor is the correct approach. Sometimes it is, but that is rarely the case. Same thing with NOLOCK. SOMETIMES it is the correct solution to the problem (excessive blocking), other times there are better solutions. And there are also the cases where end users abuse NOLOCK and put it on all tables or misuse it like having it in a query that requires a lock.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Sorry, I somehow thought was from a different person (pietlinden), totally my fault, I was going on auto-pilot.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
The very best solution to overall performance, and to blocking/deadlocking, is to go back and get the best clustered index keys on every table. Hint: this will most often not, repeat NOT, be a $IDENTITY column. But (1) that's a lot of work, (2) takes expertise, and (3) many people can't accept the idea that $IDENITY is not a perfect clus key for every table by default.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
It's all good! Not sure if I've been mistaken for Pietlinden before, but I know my opinions on query hints are that they should be avoided.
And I agree about getting a good clustered index key to help with blocking and deadlocks. Sometimes though, you inherit the system or it is a 3rd party tool and changes like that put you out of support, so you are stuck living with what you got. And sometimes the Sr DBA watched a presentation where they heard that a Clustered index key should be numeric and ever increasing and they thought "Hey, that's an IDENTITY!" and now all clustered index keys are IDENTITY's.
I think there ARE cases where an IDENTITY is the right choice, but if MOST of your SELECTs aren't filtering (or sorting) by the IDENTITY value, you have picked the wrong key. And sometimes to fix picking the wrong key, a nonclustered index needs to be created. But this is more of a "band-aid" fix to the problem.
I'm still not a huge fan of query hints in general as I have found that once you find a hint that helped one query, it is FAR too easy to think it'll fix ALL queries. I've seen abuse of NOLOCK, RECOMPILE, OPTIMIZE FOR, HASH JOIN... sometimes it is best to leave it to the optimizer to do its magic. Another reason why I like to have comments surrounding query hints is that it can be useful when doing upgrade testing. When we change from 2016 to 2019 (for example), do we still need that query hint OR did a change in the CE help that query and we can remove the hint? It is a thing we can test.
When I ask for those types of comments, I'm not looking for a novel explaining why NOLOCK was used, I am looking for things like "Support ticket 12345 - excessive blocking was noticed on table ABC and we needed a quick fix to get production back up and running - BG". Explains what was fixed, why it was fixed, and who fixed it.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system.
Viewing 15 posts - 1 through 15 (of 18 total)
You must be logged in to reply to this topic. Login to reply