How to display original part and recommende part with each other but must recome
-
I work on sql server 2019 i face issue on slow running
when I have 100000 part on table PartsHaveBestDisplayOrder and all these parts have same package and same coderulesid and Different display order
so it take too much time
so are there are any way to achieve that quickly
script code sql server
IF OBJECT_ID(N'Extractreports.dbo.PartsHaveBestDisplayOrder') Is NOT NUll
BEGIN
DROP TABLE Extractreports.dbo.PartsHaveBestDisplayOrder
END
create table Extractreports.dbo.PartsHaveBestDisplayOrder
(
PartId int,
CodeRulesId int,
PackageId int,
DisplayOrder int
)
insert into Extractreports.dbo.PartsHaveBestDisplayOrder(PartId,CodeRulesId,PackageId,DisplayOrder)
values
(12111,120,19110,1),
(12901,120,19110,5),
(33091,120,19110,4),
(30911,120,19110,3),
(55899,120,19110,2),
(80122,120,19110,1),
(30918,120,19110,3),
(76012,120,19110,2),
(54031,120,19110,4),
(30401,120,19110,5)what i try as below :
select T1.PartID as OrignalPartId , T2.PartId as RecomendationPartId,T1.DisplayOrder as OriginalDisplayOrder,T2.DisplayOrder as RecomendedDisplayOrder
from Extractreports.dbo.PartsHaveBestDisplayOrder T1 inner join
Extractreports.dbo.PartsHaveBestDisplayOrder T2 on T1.CodeRulesId =T2.CodeRulesId and T1.PackageID=t2.PackageID
where T2.DisplayOrder >t1.DisplayOrderexpected result
file attached with message
-
Does your table have any keys or indexes?
-
yes i put index for
CREATE UNIQUE CLUSTERED INDEX cdx ON dbo.PartsHaveBestDisplayOrder (CodeRulesId,PackageId,DisplayOrder,PartId);
but still slow because data is big
so are there are any solution for large amount of data
by rewrite query with another way
-
Does the query return the expected output?
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
yes
but issue on performance
so can i write statement above with another way best
-
Apologies... I used 1,000,000 for the source row count instead of just 100,000. I'll be back with corrected calculations.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Here's the corrected math considering the 100,000 rows instead of the extra zero my too-quick keyboard added....
If the rest of the data follows the example of the data you provided, the formula for the number of rows that will be in the result set will be that of an "Exclusive Triangular Join" minus the original count of the source rows.
DECLARE @SourceRowCount BIGINT = 100000;
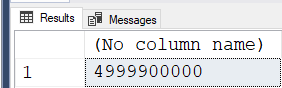
SELECT POWER(@SourceRowCount,2)/2-@SourceRowCount;RESULT:

If we add some thousands separators to that number...
4,999,900,000
...we can see that the final result set will contain 100,000 rows less than 5 BILLION ROWS!
How long do you think that will take to run on your server? I'll also tell you that the row size of the result will be 23 bytes (not including 2 bytes for the slot array), that there will be 323 whole rows per page (which does take the 2 bytes for each row in the slot array of each page into consideration) , that 4,999,900,000/323 results in 15,479,567 pages, and that there are 128 pages per Mega Byte. Doing that math of 15,479,567 /128 will result in 120,934.1171875 Mega Bytes, which is equal to ~121 GIGA BYTES.
That, not withstanding, the code you wrote is about the fastest there is for this task. You're just going to have to wait for it to complete.
I suggest you find a different methodology for whatever it is that you're trying to do because the math says this is going to cost you some time and space.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply