Help with SQL memory pressure investigation
-
Hello,
Please help me with SQL memory pressure investigation.1 month ago we upgraded from SQL2005 (on WindowsServer2008) to SQL2016 (on WindowsServer2016).
Since that moment we had few serious incidents caused by memory pressure.
How do I know that we had memory pressure?
SQL plans size dropped to 100MB instead of standard 8GB.
Multiple errors in log like: "AppDomain 22 (XXX.dbo[runtime].28) is marked for unload due to memory pressure."Are there any well known reasons of internal/external memory pressure?
I suspect that it was internal memory pressure because:
- there was enough free system memory on server (not used by SQL)
- problem was solved by restart of SQL Server serviceOur system description:
SQL 2016 13.0.4451.0 (SP1+CU5)
Server Memory: 262048 MB - divided between 3 SQL instances (MaxMemory: 160GB/32GB/16GB + over 40GB free for System)
Availability Groups enabled and replicated to Secondary Server.
Query Store currently disabled since first problem occured (it was suspected as source of problem).
Lock Pages in Memory and Instant File Initialization - enabled
DB Compatibility level = SQL2016 (few times we changed to SQL2012 because CPU was better, and it seems that we didn't have memory pressure).
Legacy Cardinality Estimation = ON (much better plans). Query optimizer fixes = ON
optimize for ad hoc workloads option = ENABLEDHow can we prepare for next memory pressure disaster?
We monitor such parameters like #Compilations or PageLifeExpectancy so we noticed that there is disaster in progress.
But we need to monitor something to find reason of memory pressure.
Can we enable some additional logging?
Some useful event logs in WindowsServer?Any well known memory pressure sources from your experience?

-
Hi,
I would be interested in transaction\sec and batches\sec.
Along with an idea of what is actually running at that point to cause the spike.Is it more transactions or bad code or process.
Profiler might be able to point you in the direction of what code is running.
Or you might want to use SP_WHOISACTIVE and turn on logging.It would seem to me something runs or was running in that 10-12 min period which had a drain on resources.
SC
-
I suspect bad code or missing indexes or possibly a report pointing to this server\db.
Again you need to find out what was\is running profiler or WHOISACTIVE is the best bet. -
The reason for something like this is the queries being sent to your system. You need to capture those queries. I'd suggest one of two approaches. First, the most accurate, but the hardest to set up and maintain, create an extended events session that will capture the rpc_completed and sql_batch_completed events on your server so that you can see the behavior of the queries. You'll immediately see the ones that have high reads/writes and possibly long duration that are surely messing with your memory. The other option, easier to set up and maintain, but far less accurate for this type of investigation, would be to enable Query Store. That will capture plans and query metrics including the reads and writes. The capture is aggregated, by default, every 60 minutes, so you'll only be able to see an aggregated average (with min, max and standard deviation) for the time frame you're interested in, but you will be able to identify the queries that are using your resources.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
@SuperCat:
- SQL Profiler - we had it, but we fuc**d up and Trace file was overwritten. We will have info next time when disaster appear again
- WhoIsActive - we run it every 30 seconds and save results to table, but when disaster started then WhoIsActive couldn't complete in 7 minutes and finally was killed.
(last WhoIsActive results 30 seconds before disaster didn't show any problematic queries, but we will analyze it again, because this is all we have now)@Grant:
- QueryStore - we used this tool since day one after migration to SQL2016. But we have seen many CPU problems each time we tried to see stats in QueryStore.
Finally we decided to turn it off, which also decreased total CPU usage on server (not sure if that was 100% related, but it was much better without QueryStore)
also I've seen some forum posts where QueryStore was suspected of memory pressure
- ExtendedEvents - no experience with this tool but I guess we need to start using it 🙂What if problem wasn't caused by some query? We think we know all bad queries in our system.
What if some other process slowly eats memory and doesn't release it causing unexpected memory pressure after few days.
Is there some info that memory pressure will appear soon (when we reach some limit)? - chreo - Thursday, December 14, 2017 7:59 AM
It's possible that it's some weird memory leak, sure. However, you haven't eliminated through the data presented that it's a query or queries causing the problems. Most of the time, it's something to do with queries, data structures, indexes, missing indexes, and out of date or missing statistics. These things cause about 85% of all performance problems. You guys are just capturing system metrics. Those can tell you where a problem is, disk or memory or cpu, but not what. You need to drill down further. The majority of cases the problem is very straight forward, not obscure memory leaks that are only happening to you. That's just now how this stuff works.
As to Query Store causing problems, it can, like any other monitoring tool. However, once more, you turned it off without any sort of indication that it was the problem. There are Query Store specific wait statistics that would give you an indication of what was wrong. Also, by turning it off, you've made it so that you're not monitoring queries (since you don't have extended events up & running). You're just not gathering a full set of metrics for making your decisions.
In addition to capturing query metrics, what about wait statistics. Knowing you have memory pressure doesn't say where the slow down is occurring. You need more and better data.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
What did the two counters Total Server Memory and Target Server Memory look like over that period?
Gail Shaw
Microsoft Certified Master: SQL Server, MVP, M.Sc (Comp Sci)
SQL In The Wild: Discussions on DB performance with occasional diversions into recoverabilityWe walk in the dark places no others will enter
We stand on the bridge and no one may pass -
chreo - Thursday, December 14, 2017 2:41 AM
Hello,
Please help me with SQL memory pressure investigation.1 month ago we upgraded from SQL2005 (on WindowsServer2008) to SQL2016 (on WindowsServer2016).
Since that moment we had few serious incidents caused by memory pressure.How do I know that we had memory pressure?
SQL plans size dropped to 100MB instead of standard 8GB.
Multiple errors in log like: "AppDomain 22 (XXX.dbo[runtime].28) is marked for unload due to memory pressure."Are there any well known reasons of internal/external memory pressure?
I suspect that it was internal memory pressure because:
- there was enough free system memory on server (not used by SQL)
- problem was solved by restart of SQL Server serviceOur system description:
SQL 2016 13.0.4451.0 (SP1+CU5)
Server Memory: 262048 MB - divided between 3 SQL instances (MaxMemory: 160GB/32GB/16GB + over 40GB free for System)
On the one instance or all 3, you haven't stated, it's not clear-----------------------------------------------------------------------------------------------------------
"Ya can't make an omelette without breaking just a few eggs" 😉
-
I'm working with chreo on this problem. Please let me provide some answers + add some fresh info on the problem.
In the following post someone described similar behavior: https://social.technet.microsoft.com/Forums/en-US/537b2179-10ed-4c69-9b27-bb2c81f7708c/sql-server-2016-memory-pressure-response-flushing-plan-cache?forum=sqlkjmanageability@perry - the problem can be observed on 1 instance at a time. So far we experienced it 4 times on 2 instances. 3 times on most busy one and 1 timeon medium load one. Twice the problem occurred on the next day after migration to SQLL 2016, so practically we had 2 production incidents with this issue. Just today we spotted it on different smaller sql instance (this was the 4th incident of this type)
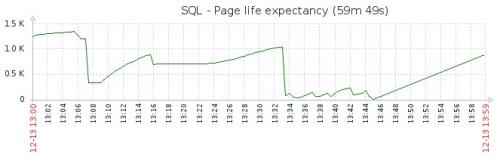
@GilaMonster– Total & Target Memory counters stay on the level equal to max server memory and does not change/decrease during the incident occurrence. OS freememory stays on safe level. OS has over 30GB of memory available for itself.
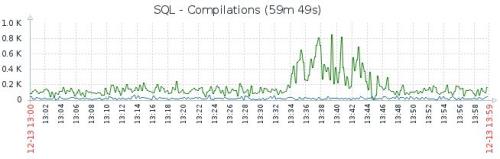
The analysis of the problem we did so far lead us to the conclusion that thereis some internal or external to SQL server factor that is causing the memory pressure. We can recognize the problem by SQL becoming unresponsive which is aconsequence of excessive query compilations/s and thus much longer executionof each query, it results in very high CPU at 100%. We are able to see it in the error logs that at the moment when CPU goes 100% + sql compilations/suddenly increase several times. We managed to discover that for some reasonSQL server does not store most of the compiled plans in the query cache. The problem which is described here troubled us few times since we migrated 1,5 month ago. As our system requires high availability, we have little time for reaction and resolution. During the first occurrence of the problem we figured out that the only measure that solves temporarily situation is SQLServer restart. (I know, one may say that this is bad practice, but in thissituation we can't afford the system being unavailable any longer). After this all gets back to normal, compilations return to the normal level, same with CPU etc.
So we have two questions:
* what causes the memory pressure?
* why SQL server behaves in such a way that it does not store compiled plans inthe cache any more?As we have no much time when the problem occurs we prepared a plan to gather asmuch data as possible on the next occurrence, before we restart the SQL. What do we want to see:
*stats from sys.dm_exec_cached_plans
* output of sys.dm_os_memory_clerks
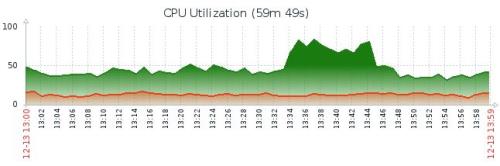
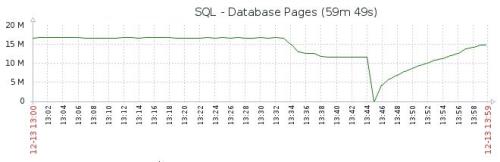
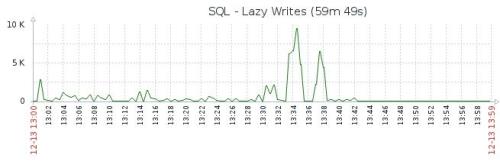
* output of sys.dm_os_memory_cache_clock_handsAnd "luckily" today we had 4th occurrence of this problem, but on different, smaller and less busy SQL instance. We observed SQL compilations very high, fewhundred times more than normally (see the charts below - blue line is for thatinstance, dropped after SQL restart), on the other hand CPU was"only" 2 times higher.
We suspect that the users could work but with the degraded performance. We concluded that after we noticed that the first symptoms of the memory pressurewere visible on 21.12 (one of them is "app domain is marked for unload dueto memory pressure" in the errorlog) and the problem persisted through thewhole Christmas period until today (27.12 11:38). See another longer term chart(blue line)
As planned I’ve executed the planned in advance queries saved them to the excel file and restarted SQL. Half an hour after SQL server restart I’ve run the queries once again and saved the to the same excel (see attached). For each of 3 queries you will see 2 sheets in theexcel. The one suffixed with B means Before restart and the one suffixed with A means After the restart.
My first observations and comments after looking at the statistics are:
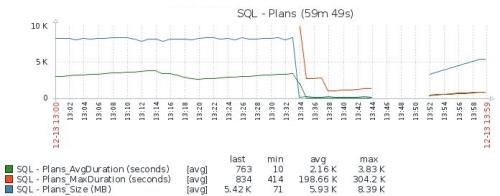
Ad Hoc and Prepared plans were not stored inthe cache plan. You could see one for a while and was immediately remove dafterwards. In the statistics of cached plans you will see ~1400 plans beforethe restart and ~ 13 000 after the restart.
The size of the cache plan before the restart was 3.8GB and 2.1GB after the restart. This is very strange considering that the 2.1GB cache was able to store 13k objects.
Probably there was kind of external memory pressure. When I summed up all objects from the cache there was 28GB before the restart and 32GB after the restart.
Any suggestions from your side?
-
From the graphs I see high CPU, low PageLifeExpectancy, and high Compilations. All these happen when doing a table Rebuild or REINDEX or Auto Update Statistics.
I would do something very simple such as logging all sysprocesses every minute for a day and comparing processes just before, during, and after the event.
- Bill Talada - Wednesday, December 27, 2017 6:15 AM
We did it. When the compilations go up, the logging is stopped or incomplete. We were not able to spot any suspected query just before or at the moment when the problem started.
We did not see any query that can trigger the memory pressure. Even if it was a query, still there is no explanation for strange behaviour of query governor which is not storing the plans in the plan cache. -
Especially because this has symptoms in the form of recompiles, check sp_Who2 during the problem and see how many SPIDs are in a KILLED/ROLLBACK state compared to normal (there usually should be none). If you're starting to see a bunch, then check your applications for the connection strings being used. You need to check and see if MARS (Multiple Active Result Sets) is turned on or off. Contrary to what many people think, it should be turned off. We had a similar problem about 5 or 6 months ago and changing the connection strings to have MARS turned off stopped the sometimes 30 minute floor outage while dozens of CPUs were solely engaged in doing KILLED/ROLLBACKs. Don't listen to people that say that ORMs (especially Entity Framework) default to having it off because we have anecdotal but solid indications that the opposite is actually true. The MS documentation for MARS states that it's for special purposes and that the code must be just right. Most code isn't. Turn it off everywhere. And, yes... one of the other major symptoms was "high memory pressure".
That's half the battle. The worst thing about MARS is that it causes the rollbacks when it decides (to grossly over-simplify) that if a "run" takes longer than the "batch" (not sure how that's even possible but it's in the documentation) that MARS will cause a rollback. So what could do such a thing? The answer is long compile times for code that MUST recompile every time it's used (part of the definition of "Crap Code"). Once we fixed the connection strings, we still had (for us) very high CPU usage with an average of 22% across 48 CPUs. To make a much longer story shorter, we found that a single particular query that ran in "only" 100 ms was taking anywhere from 2 to 22 SECONDS to compile every time it was called and it ran thousands of times per hour. We had reached a "tipping point" and it was killing us. How to find those queries with long compile times? Please see the wonderful article by Jonathan Kehayias. The code takes a long time to run but it's worth every second. Then, you need to get someone to either fix the GUI/ORM code that's identified as high compile time or you need to convert it to a well written stored procedure and then change the GUI code to use the stored procedure. We chose the latter and our CPU usage dropped from an average of 22% across 48 CPUs to vary between 6 and 8% even during the busy times of the day. Here's the link to Jonathan's article...
The other problem may be with the "new" Cardinality Estimator that came into being in 2014. When we made the jump from 2012 to 2016, it crushed us. The bad form of page sniffing seemed to go nuts and a lot of our major queries changed plans and were suddenly taking more than 20 times longer to execute. Many of the "shorter" queries did, as well. Way too many for us to fix because of the time that it takes to rewrite them, it's difficult to do because you need the data in the prod environment, and it takes a huge amount of time to do the proper regression testing.
If you can find the code that has a problem using the "new" Cardinality Estimator (CE), you could simply add a Trace Flag (or other methods/hints) to tell SQL Server to use the old CE just for the offended code. We had too much code to fix in the short amount of time that we had to do the upgrade and so we used the Trace Flag that reverted back to the old CE server wide (a very bad but very necessary choice). We'll someday need to fix that and that's a nasty Catch-22 because people won't allocate the time to fix something that's working right now and that's a part of the reason why it's such a bad choice (they'll someday deprecate and discontinue the old CE and then the feathers will really hit the fan).
Here are some articles on the subject of the "new" CE and the related Trace Flags. The original Google search I did was for is included as the first link below.
https://www.google.com/search?q=disable+new+cardinality+estimator
https://docs.microsoft.com/en-us/sql/relational-databases/performance/cardinality-estimation-sql-server
http://www.theboreddba.com/Categories/FunWithFlags/How-To-Turn-Off-the-New-2014-Cardinality-Estimator.aspx
https://blogs.technet.microsoft.com/dataplatform/2017/03/22/sql-server-2016-new-features-to-deal-with-the-new-ce/To summarize all the above...
1. Check for and change any and all connection strings that enable MARS to disable it.
2. Fix code that's taking a long time to compile and frequently does a recompile.
3. Temporarily take advantage of CE Trace Flags to "get you out of the woods".
4. Eventually, rework all code that the new CE caused to have performance problems.--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, December 27, 2017 8:34 AM
Thanks Jeff, seems to me as a good, fresh idea to investigate.
And yes, we were aware about the changes in CE but luckily we didn't have lots of troubles when switching from 2005 to 2016. Still we notice that 2012 compatibility mode provided more stable environment than 2016. If not the "memory pressure" problem and it's consequences I would say that our environment is comparable now to what we had with 2005. Well, we also know that the SQL code that we have to deal with is not perfect, but we try to cooperate with programmers to refactor it - though not easy task as our system based on kind of an old framework.
Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply