Generate Duplicate Value Range Based
-
Hi Everyone,
I Have a table which looks like this
 Source Table
Source TableAnd i want to write a sql query which produces output like image below i.e. for PIF 7247564 i want to generate number of rows that has row_id value from 2 to 53. That is repetition of values based on ROW_ID and Last_Row for a PIF.
Output of sqlSample Schema of Source Table and Expected output.
/* Source Table Design and sample values */
; WITH CTE AS
(
SELECT
1AS Batch_ID , 2AS ROW_ID ,53 AS Last_Row,7247564 PIF
UNION ALL
SELECT
1,54,305,7495906
UNION ALL
SELECT
1,306,458,7497087
UNION ALL
SELECT
1,459,617,7497892
UNION ALL
SELECT
1,618,810,7497892
)
SELECT * FROM CTE
/* Expected Output */
SELECT
1 AS Batch_ID, 2 AS Row_ID, 7247564 AS PIF
UNION ALL
SELECT
1 AS Batch_ID, 3 AS Row_ID, 7247564 AS PIF
UNION ALL
SELECT
1 AS Batch_ID, 4 AS Row_ID, 7247564 AS PIF
UNION ALL
SELECT
1 AS Batch_ID, 5 AS Row_ID, 7247564 AS PIF
UNION ALL
SELECT
1 AS Batch_ID, 6 AS Row_ID, 7247564 AS PIF
UNION ALL
SELECT
1 AS Batch_ID, 7 AS Row_ID, 7247564 AS PIF
UNION ALL
SELECT
1 AS Batch_ID, 53 AS Row_ID, 7247564 AS PIF -
Create a "Numbers" table holding all the numbers required to display the expanded result. Join this "Numbers" table with the source table on both the ROW_ID and the Last_Row column. Somthing like:
/* Source Table Design and sample values */
;
with CTE
as (
select 1 as Batch_ID
, 2 as ROW_ID
, 53 as Last_Row
, 7247564 as PIF
union all
select 1
, 54
, 305
, 7495906
union all
select 1
, 306
, 458
, 7497087
union all
select 1
, 459
, 617
, 7497892
union all
select 1
, 618
, 810
, 7497892
)
, -- CTE with sequential numbers starting at 1
cte_numbers
as (
select top 1000 row_number() over (
order by i1.COLUMN_NAME
) as Num
from master.INFORMATION_SCHEMA.COLUMNS i1
cross join master.INFORMATION_SCHEMA.COLUMNS i2
)
select Batch_ID
, Num as Expanded_Row_ID
/*, ROW_ID*/
/*, Last_Row*/
, PIF
from cte_numbers
left join CTE
on cte_numbers.Num >= CTE.ROW_ID
and cte_numbers.Num <= CTE.Last_Row
where Num >= (select MIN(ROW_ID) from CTE)
and Num <= (select MAX(Last_Row) from CTE)
;
I've not tested on performance, so there could be improvement possible...
** Don't mistake the ‘stupidity of the crowd’ for the ‘wisdom of the group’! ** -
Hi @Hanshi
Thank you very much for providing your valuable solution. Unfortunately i tried running your code over my original data set and it taking lot of time to execute. Originally i am trying to Replace above asked SQL Code to an existing SQL solution in which we are facing issues as we doing Range Based Search i.e. using BETWEEN clause in JOIN Clause.
My intent is to replace BETWEEN clause with simple JOIN ON KEY column thus to achieve i am trying to prepare this row_id,last_row set into a row set through i'll be able to run it efficiently.
I have tried different methods (cross apply,recursive query and etc ) to Build above asked sql solution but not been able to achieve it. Would appreciate if you could help me in deriving a clean and effective solution.
Thanks
-
--------------------------------------------------------------------
-- ben brugman
-- 20190419
--------------------------------------------------------------------
-- DROP TABLE F1
-- Create data.
SELECT * INTO F1 FROM
(
SELECT 1 AS Batch_ID , 2AS ROW_ID ,53 AS Last_Row,7247564 PIF
UNION ALL
SELECT 1,54,305,7495906
UNION ALL
SELECT 1,306,458,7497087
UNION ALL
SELECT 1,459,617,7497892
UNION ALL
SELECT 1,618,810,7497892
) XXX
-- SELECT * FROM F1
--------------------------------------------------------------------
-- Create a row for each row between ROW_ID AND Last_Row including.
--------------------------------------------------------------------
DECLARE @M INT = (SELECT MAX(LAST_ROW) MM FROM F1)
;
WITH
L0 AS(SELECT 0 AS c UNION ALL SELECT 0 UNION ALL SELECT 0 UNION ALL SELECT 0), -- 4
L1 AS(select 0 as x from L0 A, L0 B, L0 C, L0 D), -- 4 ^4 = 256
L2 AS(select 0 as x from L1 A, L1 B, L1 C, L1 D), -- (4 ^ 4) ^4 = 4 Giga
L9 AS(Select row_number() OVER(PARTITION BY 1 order by x ) as P from L2), -- voeg rijnummers toe
LL AS(Select * from L9 WHERE P<= @M),
COMB AS(SELECT P, F1.* FROM LL JOIN F1 ON P >= ROW_ID AND p <= LAST_ROW)
SELECT * FROM COMB
--
-- Is this what you are looking for ?
-- Greetings,
-- ben - Mr. Kapsicum wrote:
My intent is to replace BETWEEN clause with simple JOIN ON KEY column thus to achieve i am trying to prepare this row_id,last_row set into a row set through i'll be able to run it efficiently.
Using relational multiplication for this isn't just an unnecessary complication, but it will be slower that using the between on the existing table. What you really need to do is figure out what you're doing wrong in your query and figure out whether or not the right kind of index might help or not. Your current table is a classic Type 2 Slowly Changing Dimension and there's no reason to move away from that even temporarily.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
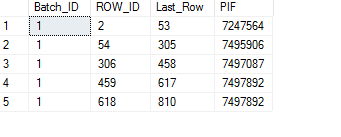 Source Table
Source Table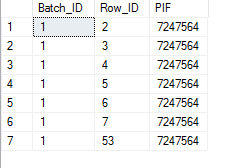 Output of sql
Output of sqlViewing 5 posts - 1 through 5 (of 5 total)
You must be logged in to reply to this topic. Login to reply