"Frankenrows"
-
I'm not sure if that's the correct term for what we're seeing here, but it seems appropriate. Here's some code:
CREATE TABLE #Details
(
ID INT,
ColumnA INT,
ColumnB INT
)
CREATE TABLE #SubDetails
(
A INT,
B INT
)
INSERT INTO #SubDetails (A, B)
VALUES (1, NULL), (2, 2)
INSERT INTO #Details (ID)
VALUES (1), (2), (3)
-- This returns the dataset that is about to be updated.
SELECT D.ID,
ColumnA = SUB.A,
ColumnB = SUB.B
FROM #Details D
JOIN #SubDetails SUB ON (1 = 1)
UPDATE D
SET ColumnA = SUB.A,
ColumnB = SUB.B
FROM #Details D
JOIN #SubDetails SUB ON (1 = 1)
SELECT * FROM #Details
DROP TABLE #Details
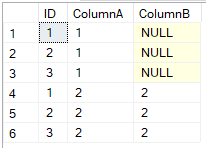
DROP TABLE #SubDetailsWe're doing an UPDATE on a dataset where there's more than one matching row for each row being updated. The first dataset returned above is

My understanding (mistaken, clearly) is that for each ID, SQL could chose either "1 and NULL" or "2 and 2" depending on who-knows-what.
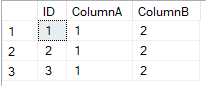
However, what actually happens is
where is seems to have picked the value from one column in one row and the second column from a different row.
Does anybody know what's going on here? Thanks.
-
ON (1 =1) is unusual JOIN syntax – can you explain what you want it to do?
- Phil Parkin wrote:
ON (1 =1) is unusual JOIN syntax – can you explain what you want it to do?
That's what people where I work at did before they knew how to spell CROSS JOIN.
And, it was intentional... that's what they actually wanted to do was a CROSS JOIN but didn't know.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
You get the same results with "CROSS JOIN #SubDetails SUB".
The code I posted is an abstraction / summary of some production code we were investigating recently. I'm just interested to know what's going on as it's not something I understand. (One of many things I don't understand!)
-
It seems to UPDATE with the first non null value it comes across.
Due to the way SQL Server is internally structured, with a small heap under low load this will probably be the order the data was inserted. The result will actually be nondeterministic as in theory a table is an unordered set and Microsoft documentation states that the order cannot be guaranteed. (So far the 'Quirky Update' can get around this with a lot of rules but this has nothing to do with your code.) ie The production code is probably wrong and causing obscure intermittent errors. I would try and find out what the code is meant to do and implement it in a deterministic manner.
This is also why ANSI SQL does not support an UPDATE with a JOIN and why MERGE throws an exception if there is an attempt to update the same row more than once. In tsql, given that MERGE can cause a lot of blocking, it is fine to use an UPDATE with a JOIN but you need to ensure the updated row only joins to one row in the other table as, unlike MERGE, there is no exception if multiple rows occur.
-
Try a
CROSS APPLYwith aTOP(1)instead of a join.CREATE TABLE #Details
(
ID INT,
ColumnA INT,
ColumnB INT
)
CREATE TABLE #SubDetails
(
A INT,
B INT
)
INSERT INTO #SubDetails (A, B)
VALUES (1, NULL), (2, 2)
INSERT INTO #Details (ID)
VALUES (1), (2), (3)
-- This returns the dataset that is about to be updated.
SELECT D.ID,
ColumnA = SUB.A,
ColumnB = SUB.B
FROM #Details D
JOIN #SubDetails SUB ON (1 = 1)
UPDATE d
SET ColumnA = SUB.A,
ColumnB = SUB.B
FROM #Details AS d
CROSS APPLY
(
SELECT TOP(1) *
FROM #SubDetails AS sub
ORDER BY sub.a DESC /* Change the ORDER BY as desired. */
) AS sub
SELECT * FROM #Details
DROP TABLE #Details
DROP TABLE #SubDetailsDrew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA - julian.fletcher wrote:
You get the same results with "CROSS JOIN #SubDetails SUB".
The code I posted is an abstraction / summary of some production code we were investigating recently. I'm just interested to know what's going on as it's not something I understand. (One of many things I don't understand!)
I'm still curious... is there actually a WHERE (1=1) in the production code or not?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
We have about 160 instances of "WHERE (1 = 1)" or "ON (1 = 1)" in our code base and 950 of "CROSS JOIN".
The code base has about 2.6m lines of code (including commenting).
But the execution plans seem to be the same, in this case at least, and that's not really "the interesting bit".
I was just wondering if anybody could explain how we end up with a "1" in ColumnA and a "2" in ColumnB where the source data doesn't have any row with both a "1" and a "2" in it. It's an academic question, prompted by but not replicated in our production code. I'm just interested to know what's going on under the bonnet as it were.
- julian.fletcher wrote:
We have about 160 instances of "WHERE (1 = 1)" or "ON (1 = 1)" in our code base and 950 of "CROSS JOIN".
The code base has about 2.6m lines of code (including commenting).
But the execution plans seem to be the same, in this case at least, and that's not really "the interesting bit".
I was just wondering if anybody could explain how we end up with a "1" in ColumnA and a "2" in ColumnB where the source data doesn't have any row with both a "1" and a "2" in it. It's an academic question, prompted by but not replicated in our production code. I'm just interested to know what's going on under the bonnet as it were.
Run the following and see.
DROP TABLE IF EXISTS #TableA,#TableB;
GO
SELECT v.SomeInt
INTO #TableA
FROM (VALUES (1),(2),(3),(4))v(SomeInt)
;
SELECT v.SomeInt
INTO #TableB
FROM (VALUES (5),(6),(7),(8))v(SomeInt)
;
--===== Forms a "Cross Join" where all rows of TableB
-- is returned for each row of TableA
SELECT aSomeInt = a.SomeInt
,bSomeInt = b.SomeInt
FROM #TableA a
JOIN #TableB b
ON 1=1
;The 1=1 and Cross Join stuff in your database is NOT necessarily bad. "It Depends" on what else is being used for criteria in the JOIN and WHERE clauses.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply