Error: Cannot insert duplicate key row in... a non-unique index?!
- Jeffrey Williams 3188 - Tuesday, December 18, 2018 2:56 PM
Is there a known issue with page compression and false key violation errors?
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- Eric M Russell - Tuesday, December 18, 2018 3:20 PM
Not that I've ever heard of. And I hope not: I have thousands of compressed indexes.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Eric M Russell - Tuesday, December 18, 2018 3:20 PM
Not that I am aware of - just something I saw that may have an impact.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
OK, here I will restate the problem, this time with less obfuscation, except for the actual data values involved.
Here is a sample error.
Cannot insert duplicate key row in object 'storeops.Payment_AgreementPayment'
with unique index 'IX_storeops_Payment_AgreementPayment_AgreementId'.
The duplicate key value is
( 21999
, C9999
, 2018-12-13
, 2018-12-14
, 219999 ).Here is the definition for the index cited in the sample error message above. Notice the index is not unique, and notice there are (5) columns cited in the error message but only (4) key columns in the index.
CREATE NONCLUSTERED INDEX [IX_storeops_Payment_AgreementPayment_AgreementId]
ON [storeops].[Payment_AgreementPayment]
(
[AgreementId] ASC,
[SourceStore] ASC,
[RowStartDate] ASC,
[RowEndDate] ASC
)
INCLUDE (
[LeaseAmount],
[ReceiptId],
[OldPaidThroughDate],
[RowIsNoLongerInSource],
[RowIsCurrent]
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 100, DATA_COMPRESSION = PAGE)
ON [ps_RowEndDate]([RowEndDate])
GOThe error occurs only occasionally during the nightly ETL run, maybe once every two weeks, at seemingly random times, on a handful of similar tables and. The error may occur in DEV, UAT, and Production, one environment successfully processing a dataset that fails in another environment. Subsequently rerunning a failed run will result in success.
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
-
After examining Query Store, I have determined the following update statement is the source for the sample error above. It's performing an UPDATE/JOIN between a staging table and the production table.
DECLARE @RowStartDate DATE = GETDATE();UPDATE
d
SET
d.RowEndDate = DATEADD(DAY, -1, stg.RowStartDate),
d.RowIsCurrent = 0,
d.RowIsNoLongerInSource = 0,
d.ETLLogIdUpdated = stg.ETLLogIdInserted
FROM storeops_staging.Payment_AgreementPayment stg
INNER JOIN storeops.Payment_AgreementPayment d ON
stg.AgreementPaymentId = d.AgreementPaymentId AND
stg.SourceStore = d.SourceStore AND
stg.RowStartDate = @RowStartDate AND
stg.RowIsNoLongerInSource = 0 AND
(
d.RowEndDate = '9999-12-31' OR
(
d.RowEndDate < '9999-12-31' AND
d.RowIsCurrent = 1 AND
d.RowIsNoLongerInSource = 1
)
)
WHERE
HASHBYTES(N'MD5',
CAST(ISNULL(d.[RowIsNoLongerInSource], CAST(0 AS BIT)) AS NVARCHAR(1)) +
CAST(ISNULL(d.[ReceiptId], CAST(0 AS INT)) AS NVARCHAR(11)) +
CAST(ISNULL(d.[AgreementId], CAST(0 AS INT)) AS NVARCHAR(11)) +
.. 20+ more columns
)
<>
HASHBYTES(N'MD5',
CAST(ISNULL(stg.[RowIsNoLongerInSource], CAST(0 AS BIT)) AS NVARCHAR(1)) +
CAST(ISNULL(stg.[ReceiptId], CAST(0 AS INT)) AS NVARCHAR(11)) +
CAST(ISNULL(stg.[AgreementId], CAST(0 AS INT)) AS NVARCHAR(11)) +
.. 20+ more columns
)"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- Eric M Russell - Tuesday, December 18, 2018 3:37 PM
It's logical that it could create a dup key error since it's changing one of the keys.
Otoh, why are you specifying a column as a key that needs updated??
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Here is a portion of the execution plan:

"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- ScottPletcher - Tuesday, December 18, 2018 3:42 PM
When I mentioned key columns above, I was just talking about the (4) "key" columns in the non-unique index cited in the error message. I can see how the UPDATE is problematic, but even if the UPDATE is creating duplicates for the primary key, it's odd that a supplemental non-unique index [IX_storeops_Payment_AgreementPayment_AgreementId] is what gets cited in the error message. The (5) columns in the error message don't line up with the primary key either.
The following is the primary key for the table:
CONSTRAINT [PK_storeops_Payment_AgreementPayment] PRIMARY KEY NONCLUSTERED
(
[AgreementPaymentId] ASC,
[SourceStore] ASC,
[RowEndDate] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, FILLFACTOR = 90, DATA_COMPRESSION = PAGE)
ON [ps_RowEndDate]([RowEndDate]),I didn't write this ETL process, so I'm just guessing about the why of it, but RowEndDate gets updated when an updated version of a AgreementPaymentId is received. This appears to be a SCD Type 2 table.
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- Eric M Russell - Tuesday, December 18, 2018 3:42 PM
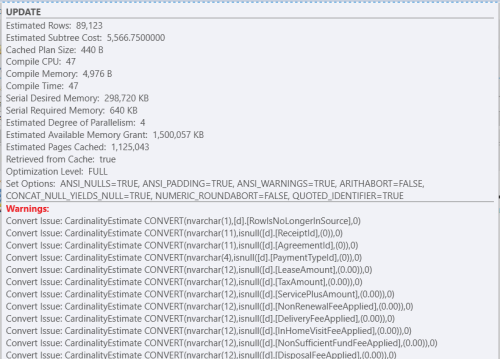
What does the warning triangle have to say?
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Tuesday, December 18, 2018 7:17 PM
It's warning about cardinality estimates; which are resulting due to data type conversion going on in the HASHBYTES() functions.
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
-
I have to admit that I've not seen the likes of this problem before without some trigger, indexed view, or audit system in place. Looking at the code and discounting some of the obvious code smells that are ugly but not likely to be the cause, the only thing that remains is the possible collisions that using the MD5 algorithm may cause. I wonder if changing that to something like SHA-256 would resolve the cause (with the understanding that we still haven't figure out an answer for your original question).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden - Wednesday, December 19, 2018 8:52 AM
On closer examination of the execution plan, I noticed an operator for inserting change tracking, and I have confirmed this is enabled on the target table [storeops].[Payment_AgreementPayment]. However, I can find reference to no known issues regarding change tracking and false key violation errors.
At this point, I have a few theories:
- Bug related to memory pressure or large parallel update plan, but I would expect a different type of error and so far I cannot correlate low resources will timeframe of these isolated and sporadic errors.
- A bug in UPDATE statement or data is causing an actual duplicate violation on the primary key, but some obscure SQL Server bug is resulting in and error message that cites the wrong index name.
- Dirty reads resulting from read uncommitted isolation causing a large parallel update to double insert. But ETL developers claim default read committed is used, and it's hard to determine exactly what isolation level the process is actually used at runtime.I suspect that if I tweak the execution plan as a work-around, perhaps MAXDOP (1) hint or using session trace flag to disable spool operation, the error will just go away, but it's unclear how this would impact performance.
This is an annoying distraction from my efforts to wrap up other tasks. Fortunately, the ETL process is designed in such a way that if the update on a specific table fails one night, it will simply pickup missed update the following night. It looks like I'll have to start a PSS after the holidays.
"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
-
I also sporadically received this error. I posted on dba.stackexchange and Paul White reported it as a bug. Similar to you, I was also updating the Primary Key field, unnecessarily, which seemed to be triggering this error. Removing it seems to have made the problem go away.
https://dba.stackexchange.com/questions/240822/cannot-insert-duplicate-key-row-on-a-non-unique-index
He created an article on the underlying bug and a bug report (go vote for it!):
https://sqlperformance.com/2019/07/sql-performance/the-any-aggregate-is-broken
-
I ran code that Paul posted on the Azure Feedback. While I understand the angst there and a lot of people will argue with me about it, I would attribute this error to the user that wrote the code and not the optimizer nor the UPDATE nor the ANY aggregate because a specific row was not identified as the source of the update. If it were me, the most I would do for a change is to return a warning to the user stating that the user has identified more than one source row to update a single row.
Shifting gears a bit, if the apparent action of this code were documented and operated in a predictable and consistent fashion (I've not tested the actual action nor the predictability/consistency), it could be regarded as a feature rather than a fault (Show me the first non-null value in c2 and c3 for each value of c1). 😀
It might not seem right to most but I wouldn't be surprised to see MS respond to this one as "Closed... operates as expected".
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - ScottPletcher wrote:
Otoh, why are you specifying a column as a key that needs updated??
Missed this before... + 1 Billion!!!
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)

Viewing 15 posts - 16 through 30 (of 32 total)
You must be logged in to reply to this topic. Login to reply