Delete Duplicates from table based on two columns
-
Assuming I have a table similar to the following:
Auto_ID Account_ID Account_Name Account_Contact Priority
1 3453463 Tire Co Doug 1
2 4363763 Computers Inc Sam 1
3 7857433 Safety First Heather 1
4 2326743 Car Dept Clark 1
5 2342567 Sales Force Amy 1
6 4363763 Computers Inc Jamie 2
7 2326743 Car Dept Jenn 2
I'm trying to delete all duplicate Account_IDs, but only for the highest priority (in this case it would be the lowest number).
I know the following would delete duplicate Account_IDs:
DELETE FROM staging_account
WHERE auto_id NOT IN
(SELECT MAX(auto_id)
FROM staging_account
GROUP BY account_id)
The problem is this doesn't take into account the priority; in the above example I would want to keep auto_ids 2 and 4 because they have a higher priority (1) than auto_ids 6 and 7 (priority 2).
How can I take priority into account and still remove duplicates in this scenario?
Thanks!
-
ROW_NUMBER is usually the best way to do something like this. Here's an idea:
DECLARE @test TABLE
(
Auto_ID int,
Account_ID INT,
Account_Name VARCHAR(25),
Account_Contact VARCHAR(10),
PRIORITY SMALLINT
);
INSERT INTO @test
(Auto_ID, Account_ID, Account_Name, Account_Contact, PRIORITY)
VALUES
(1, 3453463, 'Tire Co', 'Doug', 1),
(2, 4363763, 'Computers Inc', 'Sam', 1),
(3, 7857433, 'Safety FIRST', 'Heather', 1),
(4, 2326743, 'Car Dept', 'Clark', 1),
(5, 2342567, 'Sales FORCE', 'Amy', 1),
(6, 4363763, 'ComputersInc', 'Jamie', 2),
(7, 2326743, 'Car Dept', 'Jenn', 2);
WITH Dupes
AS (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY T.Account_ID ORDER BY T.PRIORITY) AS RowNo
FROM
@test AS T
)
DELETE FROM
Dupes
WHERE
Dupes.RowNo <> 1;
SELECT
*
FROM
@test AS T;
Please note how I provided the example data in a consumable format.
Jack Corbett
Consultant - Straight Path Solutions
Check out these links on how to get faster and more accurate answers:
Forum Etiquette: How to post data/code on a forum to get the best help
Need an Answer? Actually, No ... You Need a Question -
Try this:
DELETE FROM staging_account WHERE Auto_Id IN (
SELECT a1.Auto_Id
FROM staging_account a1
JOIN staging_account a2 ON a2.Account_Id = a1.Account_Id
AND a2.Auto_Id != a1.Auto_Id AND a2.Priority < a1.Priority)
-
This should work for you
WITH CTE AS (
SELECT *,ROW_NUMBER() OVER(PARTITION BY Account_ID ORDER BY Priority) AS rn
FROM staging_account)
DELETE FROM CTE
WHERE rn > 1;
____________________________________________________
Deja View - The strange feeling that somewhere, sometime you've optimised this query before
How to get the best help on a forum
http://www.sqlservercentral.com/articles/Best+Practices/61537
-
Hello Jack and Moderator,
I am sharing the following query which I tried and tested without using ROW_NUMBER() on SQL server 2016. Don't you think this is also an efficient way
DELETE staging_account
FROM
(
SELECT Account_ID DupAccount_ID,MIN(PRIORITY) PriorityToKeepFROM Delete2ColumnsGROUP BY Account_IDHAVING COUNT(*) > 1
)
subquery
WHERE Account_ID=subquery.DupAccount_ID AND PRIORITY!=subquery.PriorityToKeep -
Why not do both and compare the query plans?
SET STATISTICS TIME, IO ON;
and then do it. Which one takes longer?
-
Never mind... I misread some code that was written in a strange fashion.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
delete x
from @staging_account x
where not exists(select *
from staging_account y
where y.Account_ID= x.Account_ID
having max(y.PRIORITY) = x.PRIORITY) -
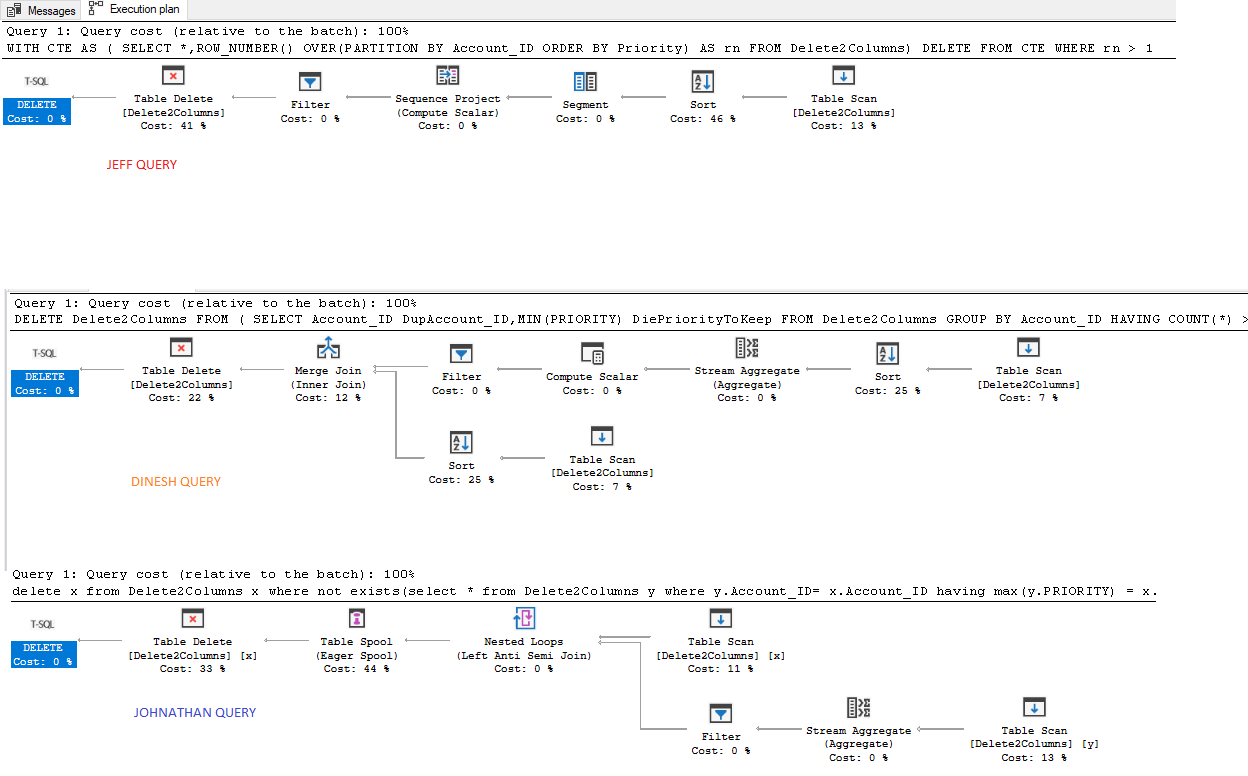
I ran all the queries by setting IO and Time on. Assumption data has 7 rows as used by Jeff.Jeff query is the clear winner
Jeff Query:
Table 'Delete2Columns'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Dinesh Query:
Table 'Delete2Columns'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Johnathan Query:
Table 'Delete2Columns'. Scan count 8, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.

-
I wonder how you got a "Jeff Query" out of this thread. I don't have any code posted. 😉
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Apology for confusion, it is Mark Cowne
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply