DB Restore is very slow ....
-
Hi All,
Is there a way to fasten db RESTORES. We are in a process of migrating dbs from on-prem to azure environment. Its a SQL 2012 as is Migration to azure IaaS Later once everything works, we will migrate to SQL 2016.
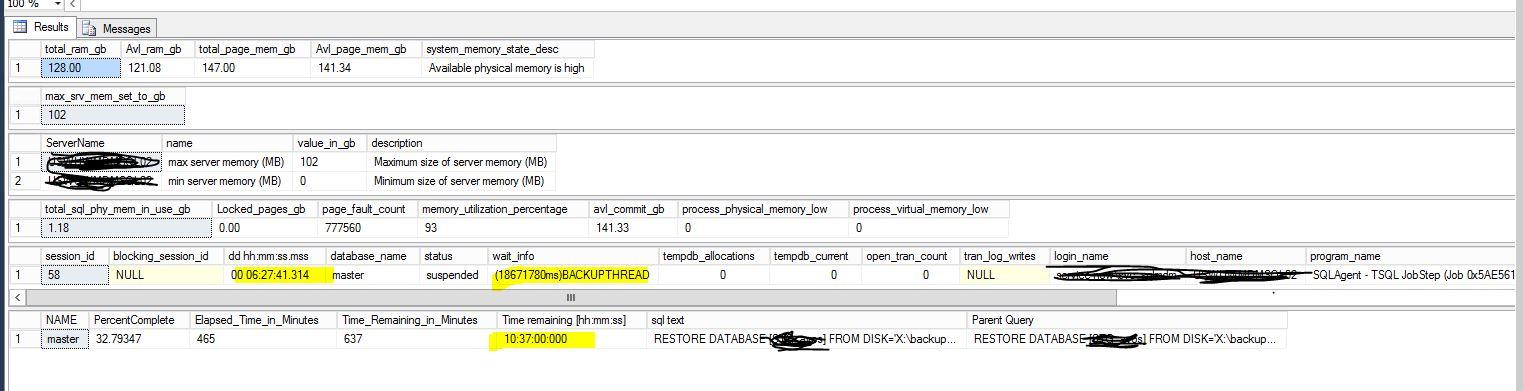
One of the database restore is taking long time. Below are the details from DMVs. We are the only users ( 2 DBA's ) who is performing the migration. It's showing BACKUPTHREAD as waittype. Anyway to make the db restore fast?
Env details
--------------
Microsoft SQL Server 2012 (SP4) (KB4018073) - 11.0.7001.0 (X64)
Aug 15 2017 10:23:29
Copyright (c) Microsoft Corporation
Enterprise Edition: Core-based Licensing (64-bit) on Windows NT 6.3 <X64> (Build 9600: ) (Hypervisor)

Thanks,
Sam
-
few questions.
- what is the size of db - logs and data sizes separate
- is IFI enabled on the server
- was compression enabled on the backup (it should have)
- how backup many files (should be 4 to 8 for better performance)
destination drives
- are data and log on same drive or different drives
- what is the block size of the those drives (would expect 64kb)
-
shrink your log file before the backup - if you have to initialize a large log file at restore time then it could slow you down.
MVDBA
-
Frederico and Mike have things to think about. This is almost always IO driven, so the more IO you can throw at it, the better. Even if you restore the full, a diff, and then logs, you might want premium, fast storage that's spread out. Striping backup files will help with this.
-
Mmmmm... maybe. I've frequently seen where striped backups and restores actually take longer, just like parallelism can sometimes have adverse effects.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I've seen it both ways. You have to have good IO systems for striping, both on the source and target. Otherwise you can have issues. You have to test and try different things for your environment.
Parallelism works great in some situations. Not so good in others. It's neither good nor bad, but it's a factor and a tool in tuning your system
- Steve Jones - SSC Editor wrote:
I've seen it both ways. You have to have good IO systems for striping, both on the source and target. Otherwise you can have issues. You have to test and try different things for your environment.
Parallelism works great in some situations. Not so good in others. It's neither good nor bad, but it's a factor and a tool in tuning your system
+1 on the test point
we have a running battle at work on parallelism, maxdop keeps getting changed behind my back - but striping backups has never been anything we considered - compression has always been better
MVDBA
-
Answers inline please
frederico_fonseca wrote:few questions.
- what is the size of db - logs and data sizes separate
2.3TB
- is IFI enabled on the server
Yes
- was compression enabled on the backup (it should have)
Yes
- how backup many files (should be 4 to 8 for better performance)
- backup taken to 1 single file. its not a striped backup, its a normal backup. Actual db contains 4 files . 3 data files and 1 log file.
destination drives
- are data and log on same drive or different drives
data drive and log file locations are different
- what is the block size of the those drives (would expect 64kb)
I don't know. is there any DOS command or a query to get this information ? what is the recommended values for SQL Server?
-
Can you please state what is the size of the log file - I did ask for it to be supplied separately - if your datafiles are 300GB and your log file is 2TB that would be your first thing to change!!!
try and split your backup onto 4 files and test it - then again with 8 files if you have capacity for it. still with compression on.
for disk size - recommended is 64KB as I mentioned and you can find the sizes with the following powershell
$wmiQuery = "SELECT Name, Label, Blocksize FROM Win32_Volume WHERE FileSystem='NTFS'"
Get-WmiObject -Query $wmiQuery -ComputerName '.' | Sort-Object Name | Select-Object Name, Label, Blocksize
-
To add to what Frederico is talking about on the Transaction Log File, the other thing to check is the number of VLFs. The log file is almost like its own operating system in that it has to not only allocate the space for the log file during a restore, it also has to restore the format of the VLFs almost like disk sectors in the old days. If your log file started out with the default settings for size and growth or are otherwise set incorrectly, the "formatting" of the log file during restores can take crippling amounts of time to restore.
I would check on that before doing anything else.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
SELECT [name], s.database_id,
COUNT(l.database_id) AS 'VLF Count',
SUM(vlf_size_mb) AS 'VLF Size (MB)',
SUM(CAST(vlf_active AS INT)) AS 'Active VLF',
SUM(vlf_active*vlf_size_mb) AS 'Active VLF Size (MB)',
COUNT(l.database_id)-SUM(CAST(vlf_active AS INT)) AS 'In-active VLF',
SUM(vlf_size_mb)-SUM(vlf_active*vlf_size_mb) AS 'In-active VLF Size (MB)'
FROM sys.databases s
CROSS APPLY sys.dm_db_log_info(s.database_id) l
GROUP BY [name], s.database_id
ORDER BY 'VLF Count' DESC
GO -
thanks guys - I forgot about the number of VLF - one would expect that these days where this is well known fact that any DBA has already set that correctly for any big database
- Steve Jones - SSC Editor wrote:
SELECT [name], s.database_id,
COUNT(l.database_id) AS 'VLF Count',
SUM(vlf_size_mb) AS 'VLF Size (MB)',
SUM(CAST(vlf_active AS INT)) AS 'Active VLF',
SUM(vlf_active*vlf_size_mb) AS 'Active VLF Size (MB)',
COUNT(l.database_id)-SUM(CAST(vlf_active AS INT)) AS 'In-active VLF',
SUM(vlf_size_mb)-SUM(vlf_active*vlf_size_mb) AS 'In-active VLF Size (MB)'
FROM sys.databases s
CROSS APPLY sys.dm_db_log_info(s.database_id) l
GROUP BY [name], s.database_id
ORDER BY 'VLF Count' DESC
GOThanks for posting the code, Steve.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - frederico_fonseca wrote:
thanks guys - I forgot about the number of VLF - one would expect that these days where this is well known fact that any DBA has already set that correctly for any big database
I totally agree that should be common knowledge... but look at some of the other questions that people working with big databases are asking. It's actually pretty spooky and is also reflected during interviews I've been in both on the employer's side of the table and the candidate side of the table. As a candidate (it's been quite a while since I was one), I've actually had interviewers insist (for example) that rCTEs are a "Best Practice" for incrementally creating sequences of numbers. And what I see on supposed "expert" blogs just scares the bejeezus out of me, especially since "Comments are closed" on a whole lot of them.
On the subject of VLFs, I frequently advertise that only 2 out of 22 job candidates (before I stopped counting) for the positions of Senior DBA and Senior Developer could name one of the functions to get the current date and time using T-SQL. It was meant to be an easy ice-breaker question to help candidates relax a bit and turned out to be a litmus strip, instead. I even had one guy that claimed more than 10 years of performance in "performance tuning" tell me that he never worked with Clustered Indexes because he's never had the opportunity to work on "Clustered Systems".
I've interviewed a whole lot of DBA's since that time, all claiming more than 5 years of experience and a whole lot of them claiming at least 10 years of experience. Like I said, I stopped counting years ago but out of all those "Senior DBAs" I've interviewed, only a couple actually knew what a VLF actually was.
I'm to the point where nothing surprises me during interviews, on forums, or on "expert" blogs anymore but I'm positive they'll find a way. 😀 And, I'm not even that smart myself. For example, I've always worked on a team where the infrastructure guys took care of mirroring, replication, "Always On", etc, etc. I understand the basic principles but I couldn't actually do such a thing without having to do some pretty serious study.
That might be the difference in some of us... we know what we don't know, admit we don't know (especially during an interview, instead of trying to BS our way through), and tell them how we'd find out how to do it.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:frederico_fonseca wrote:
thanks guys - I forgot about the number of VLF - one would expect that these days where this is well known fact that any DBA has already set that correctly for any big database
I totally agree that should be common knowledge... but look at some of the other questions that people working with big databases are asking. It's actually pretty spooky and is also reflected during interviews I've been in both on the employer's side of the table and the candidate side of the table. As a candidate (it's been quite a while since I was one), I've actually had interviewers insist (for example) that rCTEs are a "Best Practice" for incrementally creating sequences of numbers. And what I see on supposed "expert" blogs just scares the bejeezus out of me, especially since "Comments are closed" on a whole lot of them.
I'm to the point where nothing surprises me during interviews, on forums, or on "expert" blogs anymore but I'm positive they'll find a way. 😀
A few years ago I was interviewing someone for a team lead position - SSIS team. So asked what should be a basic question at that level - "can you tell me what type of containers exist". Reply was "I don't know what a container is".
A few more like this and it was pretty clear that the individual didn't know more than the really basics about SSIS.
But I love it when we ask 2-3 questions and the quality of the replies just make it clear that you are dealing with someone that does know what it is all about and the interview just turns into an informal chat rather than an interview.
Viewing 15 posts - 1 through 15 (of 18 total)
You must be logged in to reply to this topic. Login to reply